 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLM Annotations Replace User Clicks for Learning to Rank?
Nov 10, 2025Large-scale supervised data is essential for training modern ranking models, but obtaining high-quality human annotations is costly. Click data has been widely used as a low-cost alternative, and with recent advances in large language models (LLMs), LLM-based relevance annotation has emerged as another promising annotation. This paper investigates whether LLM annotations can replace click data for learning to rank (LTR) by conducting a comprehensive comparison across multiple dimensions. Experiments on both a public dataset, TianGong-ST, and an industrial dataset, Baidu-Click, show that click-supervised models perform better on high-frequency queries, while LLM annotation-supervised models are more effective on medium- and low-frequency queries. Further analysis shows that click-supervised models are better at capturing document-level signals such as authority or quality, while LLM annotation-supervised models are more effective at modeling semantic matching between queries and documents and at distinguishing relevant from non-relevant documents. Motivated by these observations, we explore two training strategies -- data scheduling and frequency-aware multi-objective learning -- that integrate both supervision signals. Both approaches enhance ranking performance across queries at all frequency levels, with the latter being more effective. Our code is available at https://github.com/Trustworthy-Information-Access/LLMAnn_Click.
Leveraging LLMs for Utility-Focused Annotation: Reducing Manual Effort for Retrieval and RAG
Apr 08, 2025Retrieval models typically rely on costly human-labeled query-document relevance annotations for training and evaluation. To reduce this cost and leverage the potential of Large Language Models (LLMs) in relevance judgments, we aim to explore whether LLM-generated annotations can effectively replace human annotations in training retrieval models. Retrieval usually emphasizes relevance, which indicates "topic-relatedness" of a document to a query, while in RAG, the value of a document (or utility) depends on how it contributes to answer generation. Recognizing this mismatch, some researchers use LLM performance on downstream tasks with documents as labels, but this approach requires manual answers for specific tasks, leading to high costs and limited generalization. In another line of work, prompting LLMs to select useful documents as RAG references eliminates the need for human annotation and is not task-specific. If we leverage LLMs' utility judgments to annotate retrieval data, we may retain cross-task generalization without human annotation in large-scale corpora. Therefore, we investigate utility-focused annotation via LLMs for large-scale retriever training data across both in-domain and out-of-domain settings on the retrieval and RAG tasks. To reduce the impact of low-quality positives labeled by LLMs, we design a novel loss function, i.e., Disj-InfoNCE. Our experiments reveal that: (1) Retrievers trained on utility-focused annotations significantly outperform those trained on human annotations in the out-of-domain setting on both tasks, demonstrating superior generalization capabilities. (2) LLM annotation does not replace human annotation in the in-domain setting. However, incorporating just 20% human-annotated data enables retrievers trained with utility-focused annotations to match the performance of models trained entirely with human annotations.
Unleashing the Power of LLMs in Dense Retrieval with Query Likelihood Modeling
Apr 07, 2025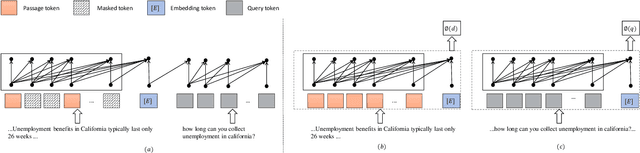
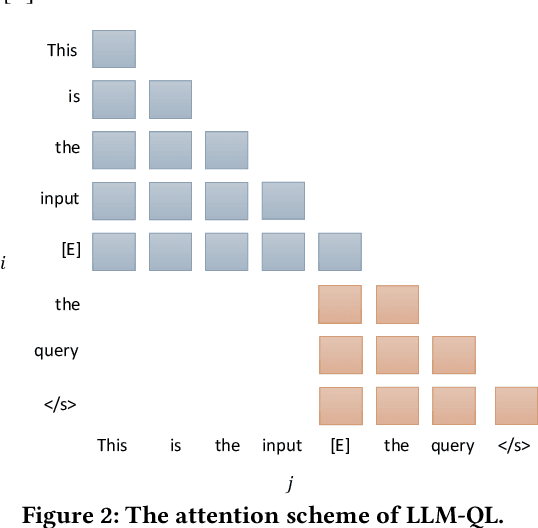
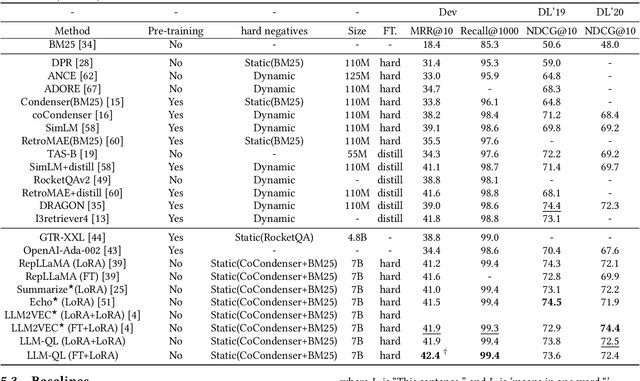
Dense retrieval is a crucial task in Information Retrieval (IR) and is the foundation for downstream tasks such as re-ranking. Recently, large language models (LLMs) have shown compelling semantic understanding capabilities and are appealing to researchers studying dense retrieval. LLMs, as decoder-style generative models, are competent at language generation while falling short on modeling global information due to the lack of attention to tokens afterward. Inspired by the classical word-based language modeling approach for IR, i.e., the query likelihood (QL) model, we seek to sufficiently utilize LLMs' generative ability by QL maximization. However, instead of ranking documents with QL estimation, we introduce an auxiliary task of QL maximization to yield a better backbone for contrastively learning a discriminative retriever. We name our model as LLM-QL. To condense global document semantics to a single vector during QL modeling, LLM-QL has two major components, Attention Stop (AS) and Input Corruption (IC). AS stops the attention of predictive tokens to previous tokens until the ending token of the document. IC masks a portion of tokens in the input documents during prediction. Experiments on MSMARCO show that LLM-QL can achieve significantly better performance than other LLM-based retrievers and using QL estimated by LLM-QL for ranking outperforms word-based QL by a large margin.
Unbiased Learning to Rank with Query-Level Click Propensity Estimation: Beyond Pointwise Observation and Relevance
Feb 18, 2025Most existing unbiased learning-to-rank (ULTR) approaches are based on the user examination hypothesis, which assumes that users will click a result only if it is both relevant and observed (typically modeled by position). However, in real-world scenarios, users often click only one or two results after examining multiple relevant options, due to limited patience or because their information needs have already been satisfied. Motivated by this, we propose a query-level click propensity model to capture the probability that users will click on different result lists, allowing for non-zero probabilities that users may not click on an observed relevant result. We hypothesize that this propensity increases when more potentially relevant results are present, and refer to this user behavior as relevance saturation bias. Our method introduces a Dual Inverse Propensity Weighting (DualIPW) mechanism -- combining query-level and position-level IPW -- to address both relevance saturation and position bias. Through theoretical derivation, we prove that DualIPW can learn an unbiased ranking model. Experiments on the real-world Baidu-ULTR dataset demonstrate that our approach significantly outperforms state-of-the-art ULTR baselines. The code and dataset information can be found at https://github.com/Trustworthy-Information-Access/DualIPW.
Generative Retrieval for Book search
Jan 19, 2025



In book search, relevant book information should be returned in response to a query. Books contain complex, multi-faceted information such as metadata, outlines, and main text, where the outline provides hierarchical information between chapters and sections. Generative retrieval (GR) is a new retrieval paradigm that consolidates corpus information into a single model to generate identifiers of documents that are relevant to a given query. How can GR be applied to book search? Directly applying GR to book search is a challenge due to the unique characteristics of book search: The model needs to retain the complex, multi-faceted information of the book, which increases the demand for labeled data. Splitting book information and treating it as a collection of separate segments for learning might result in a loss of hierarchical information. We propose an effective Generative retrieval framework for Book Search (GBS) that features two main components: data augmentation and outline-oriented book encoding. For data augmentation, GBS constructs multiple query-book pairs for training; it constructs multiple book identifiers based on the outline, various forms of book contents, and simulates real book retrieval scenarios with varied pseudo-queries. This includes coverage-promoting book identifier augmentation, allowing the model to learn to index effectively, and diversity-enhanced query augmentation, allowing the model to learn to retrieve effectively. Outline-oriented book encoding improves length extrapolation through bi-level positional encoding and retentive attention mechanisms to maintain context over long sequences. Experiments on a proprietary Baidu dataset demonstrate that GBS outperforms strong baselines, achieving a 9.8\% improvement in terms of MRR@20, over the state-of-the-art RIPOR method...
InverseCoder: Unleashing the Power of Instruction-Tuned Code LLMs with Inverse-Instruct
Jul 08, 2024Recent advancements in open-source code large language models (LLMs) have demonstrated remarkable coding abilities by fine-tuning on the data generated from powerful closed-source LLMs such as GPT-3.5 and GPT-4 for instruction tuning. This paper explores how to further improve an instruction-tuned code LLM by generating data from itself rather than querying closed-source LLMs. Our key observation is the misalignment between the translation of formal and informal languages: translating formal language (i.e., code) to informal language (i.e., natural language) is more straightforward than the reverse. Based on this observation, we propose INVERSE-INSTRUCT, which summarizes instructions from code snippets instead of the reverse. Specifically, given an instruction tuning corpus for code and the resulting instruction-tuned code LLM, we ask the code LLM to generate additional high-quality instructions for the original corpus through code summarization and self-evaluation. Then, we fine-tune the base LLM on the combination of the original corpus and the self-generated one, which yields a stronger instruction-tuned LLM. We present a series of code LLMs named InverseCoder, which surpasses the performance of the original code LLMs on a wide range of benchmarks, including Python text-to-code generation, multilingual coding, and data-science code generation.
MSR-net:Low-light Image Enhancement Using Deep Convolutional Network
Nov 07, 2017
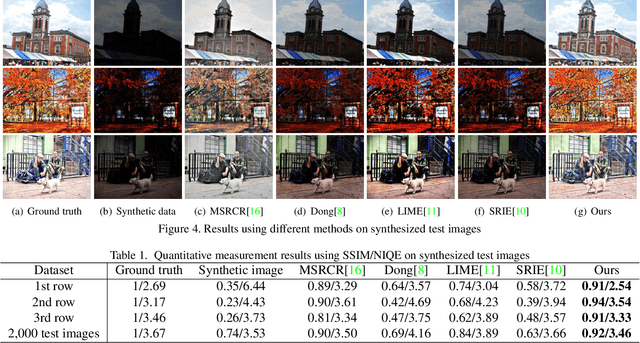
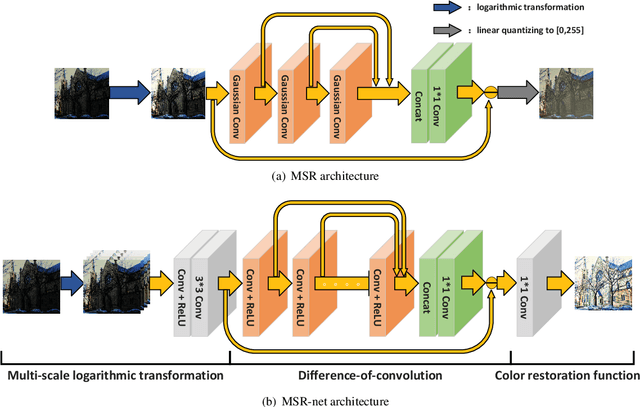

Images captured in low-light conditions usually suffer from very low contrast, which increases the difficulty of subsequent computer vision tasks in a great extent. In this paper, a low-light image enhancement model based on convolutional neural network and Retinex theory is proposed. Firstly, we show that multi-scale Retinex is equivalent to a feedforward convolutional neural network with different Gaussian convolution kernels. Motivated by this fact, we consider a Convolutional Neural Network(MSR-net) that directly learns an end-to-end mapping between dark and bright images. Different fundamentally from existing approaches, low-light image enhancement in this paper is regarded as a machine learning problem. In this model, most of the parameters are optimized by back-propagation, while the parameters of traditional models depend on the artificial setting. Experiments on a number of challenging images reveal the advantages of our method in comparison with other state-of-the-art methods from the qualitative and quantitative perspective.