 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Step Semantic Reasoning in Generative Retrieval
Mar 12, 2026Generative retrieval (GR) models encode a corpus within model parameters and generate relevant document identifiers directly for a given query. While this paradigm shows promise in retrieval tasks, existing GR models struggle with complex queries in numerical contexts, such as those involving semantic reasoning over financial reports, due to limited reasoning capabilities. This limitation leads to suboptimal retrieval accuracy and hinders practical applicability. We propose ReasonGR, a framework designed to enhance multi-step semantic reasoning in numerical contexts within GR. ReasonGR employs a structured prompting strategy combining task-specific instructions with stepwise reasoning guidance to better address complex retrieval queries. Additionally, it integrates a reasoning-focused adaptation module to improve the learning of reasoning-related parameters. Experiments on the FinQA dataset, which contains financial queries over complex documents, demonstrate that ReasonGR improves retrieval accuracy and consistency, indicating its potential for advancing GR models in reasoning-intensive retrieval scenarios.
Lightweight and Direct Document Relevance Optimization for Generative Information Retrieval
Apr 07, 2025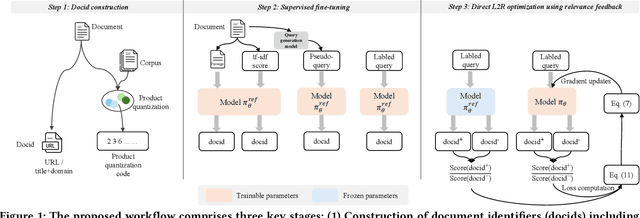
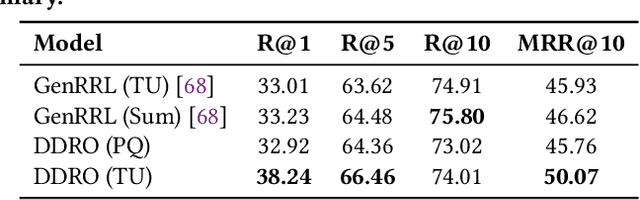
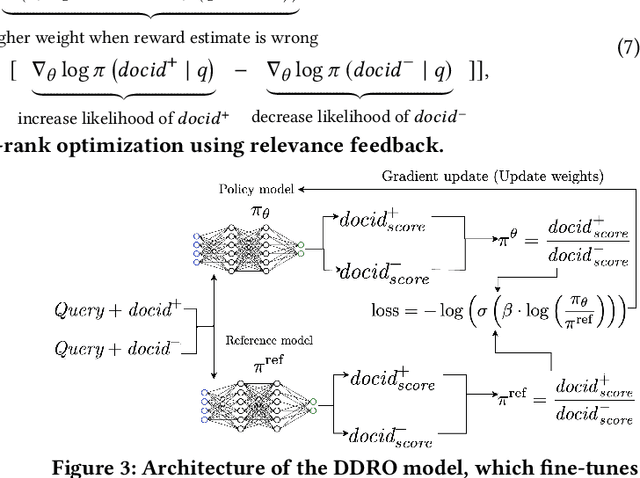
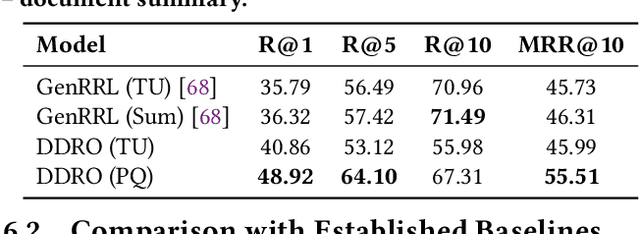
Generative information retrieval (GenIR) is a promising neural retrieval paradigm that formulates document retrieval as a document identifier (docid) generation task, allowing for end-to-end optimization toward a unified global retrieval objective. However, existing GenIR models suffer from token-level misalignment, where models trained to predict the next token often fail to capture document-level relevance effectively. While reinforcement learning-based methods, such as reinforcement learning from relevance feedback (RLRF), aim to address this misalignment through reward modeling, they introduce significant complexity, requiring the optimization of an auxiliary reward function followed by reinforcement fine-tuning, which is computationally expensive and often unstable. To address these challenges, we propose direct document relevance optimization (DDRO), which aligns token-level docid generation with document-level relevance estimation through direct optimization via pairwise ranking, eliminating the need for explicit reward modeling and reinforcement learning. Experimental results on benchmark datasets, including MS MARCO document and Natural Questions, show that DDRO outperforms reinforcement learning-based methods, achieving a 7.4% improvement in MRR@10 for MS MARCO and a 19.9% improvement for Natural Questions. These findings highlight DDRO's potential to enhance retrieval effectiveness with a simplified optimization approach. By framing alignment as a direct optimization problem, DDRO simplifies the ranking optimization pipeline of GenIR models while offering a viable alternative to reinforcement learning-based methods.
Generative Retrieval for Book search
Jan 19, 2025



In book search, relevant book information should be returned in response to a query. Books contain complex, multi-faceted information such as metadata, outlines, and main text, where the outline provides hierarchical information between chapters and sections. Generative retrieval (GR) is a new retrieval paradigm that consolidates corpus information into a single model to generate identifiers of documents that are relevant to a given query. How can GR be applied to book search? Directly applying GR to book search is a challenge due to the unique characteristics of book search: The model needs to retain the complex, multi-faceted information of the book, which increases the demand for labeled data. Splitting book information and treating it as a collection of separate segments for learning might result in a loss of hierarchical information. We propose an effective Generative retrieval framework for Book Search (GBS) that features two main components: data augmentation and outline-oriented book encoding. For data augmentation, GBS constructs multiple query-book pairs for training; it constructs multiple book identifiers based on the outline, various forms of book contents, and simulates real book retrieval scenarios with varied pseudo-queries. This includes coverage-promoting book identifier augmentation, allowing the model to learn to index effectively, and diversity-enhanced query augmentation, allowing the model to learn to retrieve effectively. Outline-oriented book encoding improves length extrapolation through bi-level positional encoding and retentive attention mechanisms to maintain context over long sequences. Experiments on a proprietary Baidu dataset demonstrate that GBS outperforms strong baselines, achieving a 9.8\% improvement in terms of MRR@20, over the state-of-the-art RIPOR method...
Generative Retrieval Meets Multi-Graded Relevance
Sep 27, 2024



Generative retrieval represents a novel approach to information retrieval. It uses an encoder-decoder architecture to directly produce relevant document identifiers (docids) for queries. While this method offers benefits, current approaches are limited to scenarios with binary relevance data, overlooking the potential for documents to have multi-graded relevance. Extending generative retrieval to accommodate multi-graded relevance poses challenges, including the need to reconcile likelihood probabilities for docid pairs and the possibility of multiple relevant documents sharing the same identifier. To address these challenges, we introduce a framework called GRaded Generative Retrieval (GR$^2$). GR$^2$ focuses on two key components: ensuring relevant and distinct identifiers, and implementing multi-graded constrained contrastive training. First, we create identifiers that are both semantically relevant and sufficiently distinct to represent individual documents effectively. This is achieved by jointly optimizing the relevance and distinctness of docids through a combination of docid generation and autoencoder models. Second, we incorporate information about the relationship between relevance grades to guide the training process. We use a constrained contrastive training strategy to bring the representations of queries and the identifiers of their relevant documents closer together, based on their respective relevance grades. Extensive experiments on datasets with both multi-graded and binary relevance demonstrate the effectiveness of GR$^2$.
Bootstrapped Pre-training with Dynamic Identifier Prediction for Generative Retrieval
Jul 16, 2024



Generative retrieval uses differentiable search indexes to directly generate relevant document identifiers in response to a query. Recent studies have highlighted the potential of a strong generative retrieval model, trained with carefully crafted pre-training tasks, to enhance downstream retrieval tasks via fine-tuning. However, the full power of pre-training for generative retrieval remains underexploited due to its reliance on pre-defined static document identifiers, which may not align with evolving model parameters. In this work, we introduce BootRet, a bootstrapped pre-training method for generative retrieval that dynamically adjusts document identifiers during pre-training to accommodate the continuing memorization of the corpus. BootRet involves three key training phases: (i) initial identifier generation, (ii) pre-training via corpus indexing and relevance prediction tasks, and (iii) bootstrapping for identifier updates. To facilitate the pre-training phase, we further introduce noisy documents and pseudo-queries, generated by large language models, to resemble semantic connections in both indexing and retrieval tasks. Experimental results demonstrate that BootRet significantly outperforms existing pre-training generative retrieval baselines and performs well even in zero-shot settings.
Listwise Generative Retrieval Models via a Sequential Learning Process
Mar 19, 2024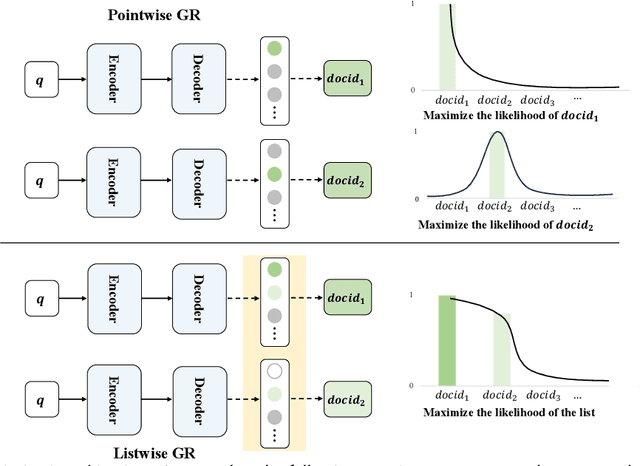



Recently, a novel generative retrieval (GR) paradigm has been proposed, where a single sequence-to-sequence model is learned to directly generate a list of relevant document identifiers (docids) given a query. Existing GR models commonly employ maximum likelihood estimation (MLE) for optimization: this involves maximizing the likelihood of a single relevant docid given an input query, with the assumption that the likelihood for each docid is independent of the other docids in the list. We refer to these models as the pointwise approach in this paper. While the pointwise approach has been shown to be effective in the context of GR, it is considered sub-optimal due to its disregard for the fundamental principle that ranking involves making predictions about lists. In this paper, we address this limitation by introducing an alternative listwise approach, which empowers the GR model to optimize the relevance at the docid list level. Specifically, we view the generation of a ranked docid list as a sequence learning process: at each step we learn a subset of parameters that maximizes the corresponding generation likelihood of the $i$-th docid given the (preceding) top $i-1$ docids. To formalize the sequence learning process, we design a positional conditional probability for GR. To alleviate the potential impact of beam search on the generation quality during inference, we perform relevance calibration on the generation likelihood of model-generated docids according to relevance grades. We conduct extensive experiments on representative binary and multi-graded relevance datasets. Our empirical results demonstrate that our method outperforms state-of-the-art GR baselines in terms of retrieval performance.
Semantic-Enhanced Differentiable Search Index Inspired by Learning Strategies
May 24, 2023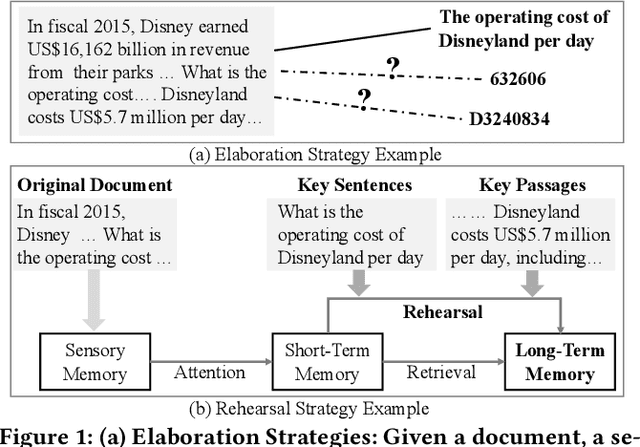
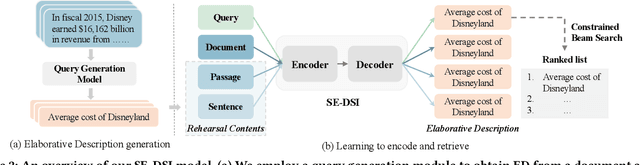
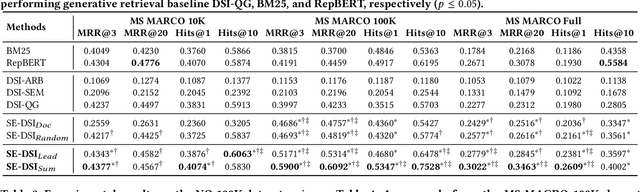
Recently, a new paradigm called Differentiable Search Index (DSI) has been proposed for document retrieval, wherein a sequence-to-sequence model is learned to directly map queries to relevant document identifiers. The key idea behind DSI is to fully parameterize traditional ``index-retrieve'' pipelines within a single neural model, by encoding all documents in the corpus into the model parameters. In essence, DSI needs to resolve two major questions: (1) how to assign an identifier to each document, and (2) how to learn the associations between a document and its identifier. In this work, we propose a Semantic-Enhanced DSI model (SE-DSI) motivated by Learning Strategies in the area of Cognitive Psychology. Our approach advances original DSI in two ways: (1) For the document identifier, we take inspiration from Elaboration Strategies in human learning. Specifically, we assign each document an Elaborative Description based on the query generation technique, which is more meaningful than a string of integers in the original DSI; and (2) For the associations between a document and its identifier, we take inspiration from Rehearsal Strategies in human learning. Specifically, we select fine-grained semantic features from a document as Rehearsal Contents to improve document memorization. Both the offline and online experiments show improved retrieval performance over prevailing baselines.