 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimized Text Embedding Models and Benchmarks for Amharic Passage Retrieval
May 25, 2025Neural retrieval methods using transformer-based pre-trained language models have advanced multilingual and cross-lingual retrieval. However, their effectiveness for low-resource, morphologically rich languages such as Amharic remains underexplored due to data scarcity and suboptimal tokenization. We address this gap by introducing Amharic-specific dense retrieval models based on pre-trained Amharic BERT and RoBERTa backbones. Our proposed RoBERTa-Base-Amharic-Embed model (110M parameters) achieves a 17.6% relative improvement in MRR@10 and a 9.86% gain in Recall@10 over the strongest multilingual baseline, Arctic Embed 2.0 (568M parameters). More compact variants, such as RoBERTa-Medium-Amharic-Embed (42M), remain competitive while being over 13x smaller. Additionally, we train a ColBERT-based late interaction retrieval model that achieves the highest MRR@10 score (0.843) among all evaluated models. We benchmark our proposed models against both sparse and dense retrieval baselines to systematically assess retrieval effectiveness in Amharic. Our analysis highlights key challenges in low-resource settings and underscores the importance of language-specific adaptation. To foster future research in low-resource IR, we publicly release our dataset, codebase, and trained models at https://github.com/kidist-amde/amharic-ir-benchmarks.
Lightweight and Direct Document Relevance Optimization for Generative Information Retrieval
Apr 07, 2025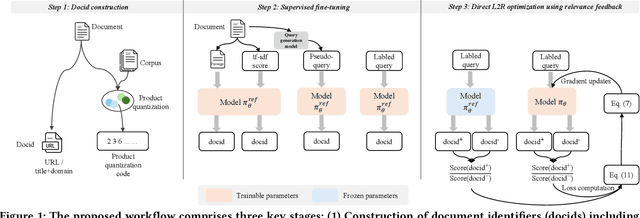
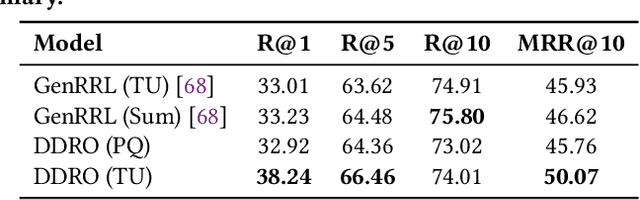
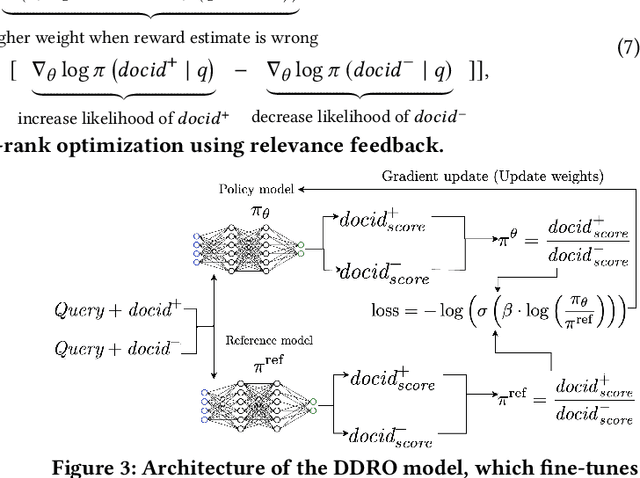
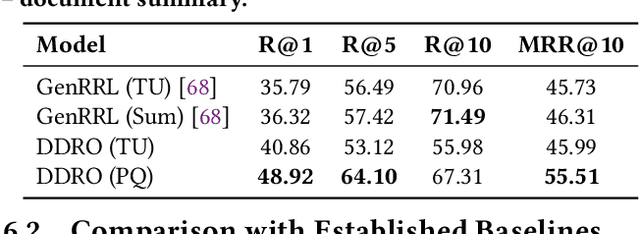
Generative information retrieval (GenIR) is a promising neural retrieval paradigm that formulates document retrieval as a document identifier (docid) generation task, allowing for end-to-end optimization toward a unified global retrieval objective. However, existing GenIR models suffer from token-level misalignment, where models trained to predict the next token often fail to capture document-level relevance effectively. While reinforcement learning-based methods, such as reinforcement learning from relevance feedback (RLRF), aim to address this misalignment through reward modeling, they introduce significant complexity, requiring the optimization of an auxiliary reward function followed by reinforcement fine-tuning, which is computationally expensive and often unstable. To address these challenges, we propose direct document relevance optimization (DDRO), which aligns token-level docid generation with document-level relevance estimation through direct optimization via pairwise ranking, eliminating the need for explicit reward modeling and reinforcement learning. Experimental results on benchmark datasets, including MS MARCO document and Natural Questions, show that DDRO outperforms reinforcement learning-based methods, achieving a 7.4% improvement in MRR@10 for MS MARCO and a 19.9% improvement for Natural Questions. These findings highlight DDRO's potential to enhance retrieval effectiveness with a simplified optimization approach. By framing alignment as a direct optimization problem, DDRO simplifies the ranking optimization pipeline of GenIR models while offering a viable alternative to reinforcement learning-based methods.
Adv-KD: Adversarial Knowledge Distillation for Faster Diffusion Sampling
May 31, 2024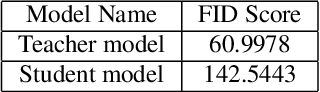

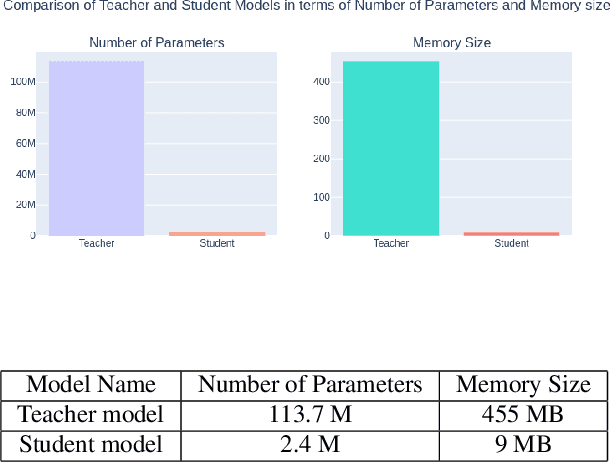
Diffusion Probabilistic Models (DPMs) have emerged as a powerful class of deep generative models, achieving remarkable performance in image synthesis tasks. However, these models face challenges in terms of widespread adoption due to their reliance on sequential denoising steps during sample generation. This dependence leads to substantial computational requirements, making them unsuitable for resource-constrained or real-time processing systems. To address these challenges, we propose a novel method that integrates denoising phases directly into the model's architecture, thereby reducing the need for resource-intensive computations. Our approach combines diffusion models with generative adversarial networks (GANs) through knowledge distillation, enabling more efficient training and evaluation. By utilizing a pre-trained diffusion model as a teacher model, we train a student model through adversarial learning, employing layerwise transformations for denoising and submodules for predicting the teacher model's output at various points in time. This integration significantly reduces the number of parameters and denoising steps required, leading to improved sampling speed at test time. We validate our method with extensive experiments, demonstrating comparable performance with reduced computational requirements compared to existing approaches. By enabling the deployment of diffusion models on resource-constrained devices, our research mitigates their computational burden and paves the way for wider accessibility and practical use across the research community and end-users. Our code is publicly available at https://github.com/kidist-amde/Adv-KD
Conditioning GAN Without Training Dataset
May 31, 2024Deep learning algorithms have a large number of trainable parameters often with sizes of hundreds of thousands or more. Training this algorithm requires a large amount of training data and generating a sufficiently large dataset for these algorithms is costly\cite{noguchi2019image}. GANs are generative neural networks that use two deep learning networks that are competing with each other. The networks are generator and discriminator networks. The generator tries to generate realistic images which resemble the actual training dataset by approximating the training data distribution and the discriminator is trained to classify images as real or fake(generated)\cite{goodfellow2016nips}. Training these GAN algorithms also requires a large amount of training dataset\cite{noguchi2019image}. In this study, the aim is to address the question, "Given an unconditioned pretrained generator network and a pretrained classifier, is it feasible to develop a conditioned generator without relying on any training dataset?" The paper begins with a general introduction to the problem. The subsequent sections are structured as follows: Section 2 provides background information on the problem. Section 3 reviews relevant literature on the topic. Section 4 outlines the methodology employed in this study. Section 5 presents the experimental results. Section 6 discusses the findings and proposes potential future research directions. Finally, Section 7 offers concluding remarks. The implementation can be accessed \href{https://github.com/kidist-amde/BigGAN-PyTorch}{here}.
Balanced Face Dataset: Guiding StyleGAN to Generate Labeled Synthetic Face Image Dataset for Underrepresented Group
Aug 07, 2023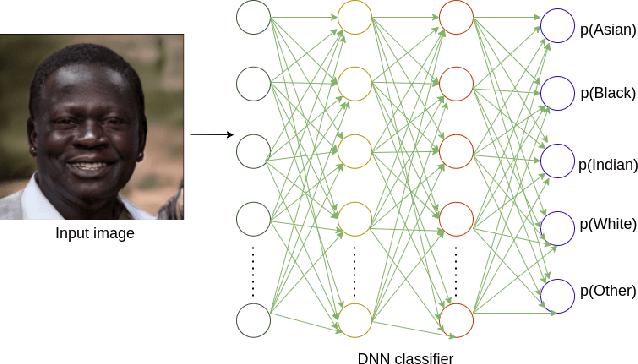



For a machine learning model to generalize effectively to unseen data within a particular problem domain, it is well-understood that the data needs to be of sufficient size and representative of real-world scenarios. Nonetheless, real-world datasets frequently have overrepresented and underrepresented groups. One solution to mitigate bias in machine learning is to leverage a diverse and representative dataset. Training a model on a dataset that covers all demographics is crucial to reducing bias in machine learning. However, collecting and labeling large-scale datasets has been challenging, prompting the use of synthetic data generation and active labeling to decrease the costs of manual labeling. The focus of this study was to generate a robust face image dataset using the StyleGAN model. In order to achieve a balanced distribution of the dataset among different demographic groups, a synthetic dataset was created by controlling the generation process of StyleGaN and annotated for different downstream tasks.