 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Power of LLMs in Dense Retrieval with Query Likelihood Modeling
Apr 07, 2025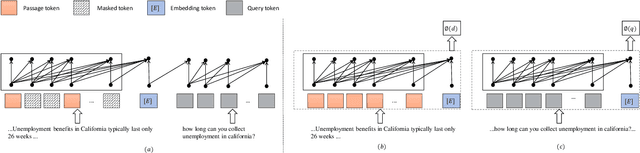
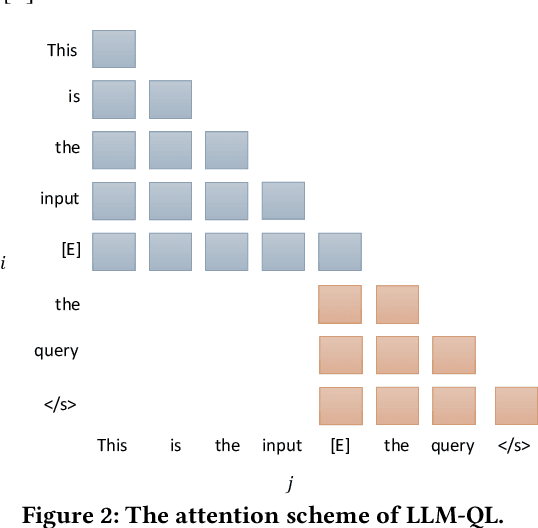
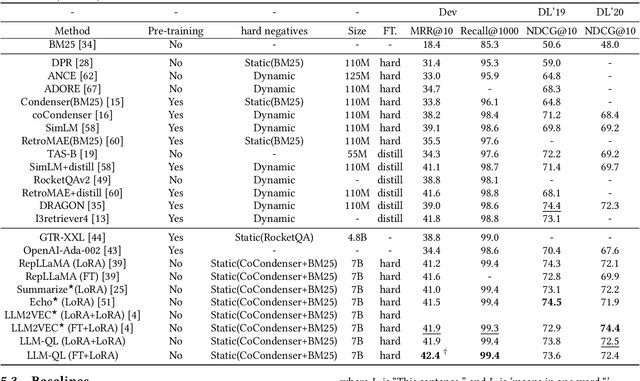
Dense retrieval is a crucial task in Information Retrieval (IR) and is the foundation for downstream tasks such as re-ranking. Recently, large language models (LLMs) have shown compelling semantic understanding capabilities and are appealing to researchers studying dense retrieval. LLMs, as decoder-style generative models, are competent at language generation while falling short on modeling global information due to the lack of attention to tokens afterward. Inspired by the classical word-based language modeling approach for IR, i.e., the query likelihood (QL) model, we seek to sufficiently utilize LLMs' generative ability by QL maximization. However, instead of ranking documents with QL estimation, we introduce an auxiliary task of QL maximization to yield a better backbone for contrastively learning a discriminative retriever. We name our model as LLM-QL. To condense global document semantics to a single vector during QL modeling, LLM-QL has two major components, Attention Stop (AS) and Input Corruption (IC). AS stops the attention of predictive tokens to previous tokens until the ending token of the document. IC masks a portion of tokens in the input documents during prediction. Experiments on MSMARCO show that LLM-QL can achieve significantly better performance than other LLM-based retrievers and using QL estimated by LLM-QL for ranking outperforms word-based QL by a large margin.
Reproducibility Analysis and Enhancements for Multi-Aspect Dense Retriever with Aspect Learning
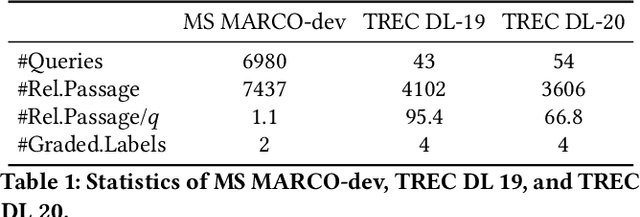
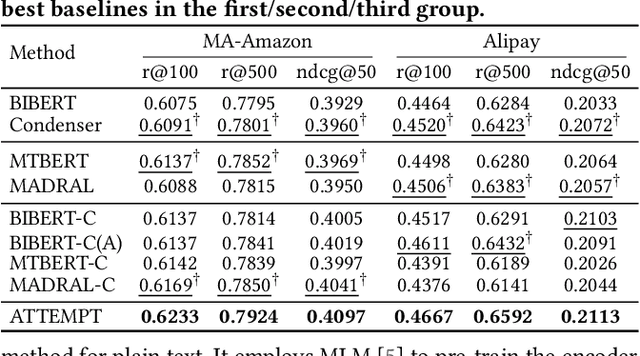
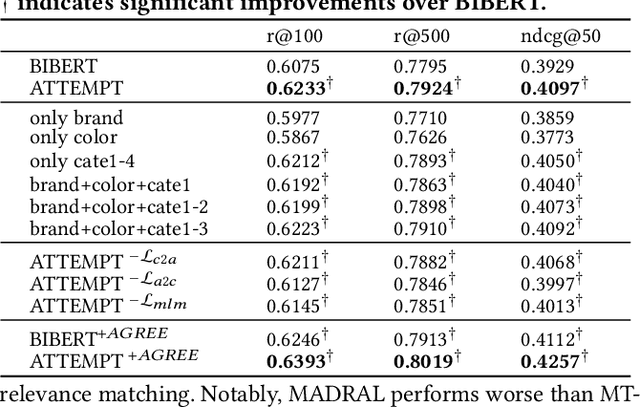
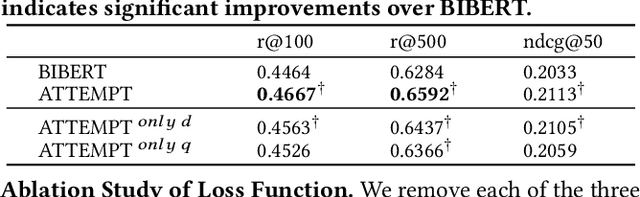
Jan 16, 2024Multi-aspect dense retrieval aims to incorporate aspect information (e.g., brand and category) into dual encoders to facilitate relevance matching. As an early and representative multi-aspect dense retriever, MADRAL learns several extra aspect embeddings and fuses the explicit aspects with an implicit aspect "OTHER" for final representation. MADRAL was evaluated on proprietary data and its code was not released, making it challenging to validate its effectiveness on other datasets. We failed to reproduce its effectiveness on the public MA-Amazon data, motivating us to probe the reasons and re-examine its components. We propose several component alternatives for comparisons, including replacing "OTHER" with "CLS" and representing aspects with the first several content tokens. Through extensive experiments, we confirm that learning "OTHER" from scratch in aspect fusion is harmful. In contrast, our proposed variants can greatly enhance the retrieval performance. Our research not only sheds light on the limitations of MADRAL but also provides valuable insights for future studies on more powerful multi-aspect dense retrieval models. Code will be released at: https://github.com/sunxiaojie99/Reproducibility-for-MADRAL.
A Multi-Granularity-Aware Aspect Learning Model for Multi-Aspect Dense Retrieval
Dec 05, 2023



Dense retrieval methods have been mostly focused on unstructured text and less attention has been drawn to structured data with various aspects, e.g., products with aspects such as category and brand. Recent work has proposed two approaches to incorporate the aspect information into item representations for effective retrieval by predicting the values associated with the item aspects. Despite their efficacy, they treat the values as isolated classes (e.g., "Smart Homes", "Home, Garden & Tools", and "Beauty & Health") and ignore their fine-grained semantic relation. Furthermore, they either enforce the learning of aspects into the CLS token, which could confuse it from its designated use for representing the entire content semantics, or learn extra aspect embeddings only with the value prediction objective, which could be insufficient especially when there are no annotated values for an item aspect. Aware of these limitations, we propose a MUlti-granulaRity-aware Aspect Learning model (MURAL) for multi-aspect dense retrieval. It leverages aspect information across various granularities to capture both coarse and fine-grained semantic relations between values. Moreover, MURAL incorporates separate aspect embeddings as input to transformer encoders so that the masked language model objective can assist implicit aspect learning even without aspect-value annotations. Extensive experiments on two real-world datasets of products and mini-programs show that MURAL outperforms state-of-the-art baselines significantly.
Pre-training with Aspect-Content Text Mutual Prediction for Multi-Aspect Dense Retrieval
Aug 22, 2023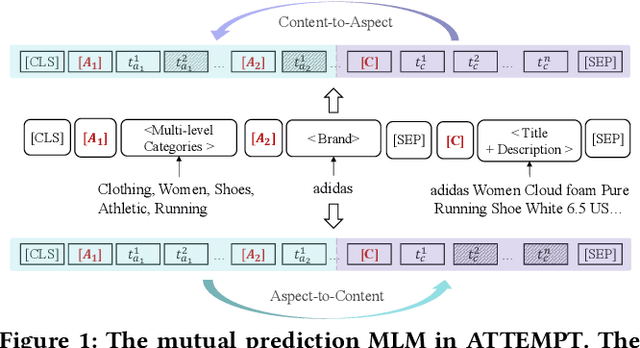
Grounded on pre-trained language models (PLMs), dense retrieval has been studied extensively on plain text. In contrast, there has been little research on retrieving data with multiple aspects using dense models. In the scenarios such as product search, the aspect information plays an essential role in relevance matching, e.g., category: Electronics, Computers, and Pet Supplies. A common way of leveraging aspect information for multi-aspect retrieval is to introduce an auxiliary classification objective, i.e., using item contents to predict the annotated value IDs of item aspects. However, by learning the value embeddings from scratch, this approach may not capture the various semantic similarities between the values sufficiently. To address this limitation, we leverage the aspect information as text strings rather than class IDs during pre-training so that their semantic similarities can be naturally captured in the PLMs. To facilitate effective retrieval with the aspect strings, we propose mutual prediction objectives between the text of the item aspect and content. In this way, our model makes more sufficient use of aspect information than conducting undifferentiated masked language modeling (MLM) on the concatenated text of aspects and content. Extensive experiments on two real-world datasets (product and mini-program search) show that our approach can outperform competitive baselines both treating aspect values as classes and conducting the same MLM for aspect and content strings. Code and related dataset will be available at the URL \footnote{https://github.com/sunxiaojie99/ATTEMPT}.
Ensemble Ranking Model with Multiple Pretraining Strategies for Web Search
Feb 18, 2023


An effective ranking model usually requires a large amount of training data to learn the relevance between documents and queries. User clicks are often used as training data since they can indicate relevance and are cheap to collect, but they contain substantial bias and noise. There has been some work on mitigating various types of bias in simulated user clicks to train effective learning-to-rank models based on multiple features. However, how to effectively use such methods on large-scale pre-trained models with real-world click data is unknown. To alleviate the data bias in the real world, we incorporate heuristic-based features, refine the ranking objective, add random negatives, and calibrate the propensity calculation in the pre-training stage. Then we fine-tune several pre-trained models and train an ensemble model to aggregate all the predictions from various pre-trained models with human-annotation data in the fine-tuning stage. Our approaches won 3rd place in the "Pre-training for Web Search" task in WSDM Cup 2023 and are 22.6% better than the 4th-ranked team.
Feature-Enhanced Network with Hybrid Debiasing Strategies for Unbiased Learning to Rank
Feb 15, 2023


Unbiased learning to rank (ULTR) aims to mitigate various biases existing in user clicks, such as position bias, trust bias, presentation bias, and learn an effective ranker. In this paper, we introduce our winning approach for the "Unbiased Learning to Rank" task in WSDM Cup 2023. We find that the provided data is severely biased so neural models trained directly with the top 10 results with click information are unsatisfactory. So we extract multiple heuristic-based features for multi-fields of the results, adjust the click labels, add true negatives, and re-weight the samples during model training. Since the propensities learned by existing ULTR methods are not decreasing w.r.t. positions, we also calibrate the propensities according to the click ratios and ensemble the models trained in two different ways. Our method won the 3rd prize with a DCG@10 score of 9.80, which is 1.1% worse than the 2nd and 25.3% higher than the 4th.