 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Verifier: Collaborative Multimodal Reasoning via Dynamic Process Supervision
Feb 04, 2026Reinforcement Learning (RL) has emerged as a pivotal mechanism for enhancing the complex reasoning capabilities of Multimodal Large Language Models (MLLMs). However, prevailing paradigms typically rely on solitary rollout strategies where the model works alone. This lack of intermediate oversight renders the reasoning process susceptible to error propagation, where early logical deviations cascade into irreversible failures, resulting in noisy optimization signals. In this paper, we propose the \textbf{Guided Verifier} framework to address these structural limitations. Moving beyond passive terminal rewards, we introduce a dynamic verifier that actively co-solves tasks alongside the policy. During the rollout phase, this verifier interacts with the policy model in real-time, detecting inconsistencies and providing directional signals to steer the model toward valid trajectories. To facilitate this, we develop a specialized data synthesis pipeline targeting multimodal hallucinations, constructing \textbf{CoRe} dataset of process-level negatives and \textbf{Co}rrect-guide \textbf{Re}asoning trajectories to train the guided verifier. Extensive experiments on MathVista, MathVerse and MMMU indicate that by allocating compute to collaborative inference and dynamic verification, an 8B-parameter model can achieve strong performance.
MMIDR: Teaching Large Language Model to Interpret Multimodal Misinformation via Knowledge Distillation
Mar 21, 2024Automatic detection of multimodal misinformation has gained a widespread attention recently. However, the potential of powerful Large Language Models (LLMs) for multimodal misinformation detection remains underexplored. Besides, how to teach LLMs to interpret multimodal misinformation in cost-effective and accessible way is still an open question. To address that, we propose MMIDR, a framework designed to teach LLMs in providing fluent and high-quality textual explanations for their decision-making process of multimodal misinformation. To convert multimodal misinformation into an appropriate instruction-following format, we present a data augmentation perspective and pipeline. This pipeline consists of a visual information processing module and an evidence retrieval module. Subsequently, we prompt the proprietary LLMs with processed contents to extract rationales for interpreting the authenticity of multimodal misinformation. Furthermore, we design an efficient knowledge distillation approach to distill the capability of proprietary LLMs in explaining multimodal misinformation into open-source LLMs. To explore several research questions regarding the performance of LLMs in multimodal misinformation detection tasks, we construct an instruction-following multimodal misinformation dataset and conduct comprehensive experiments. The experimental findings reveal that our MMIDR exhibits sufficient detection performance and possesses the capacity to provide compelling rationales to support its assessments.
A Survey on Knowledge Distillation of Large Language Models
Feb 23, 2024
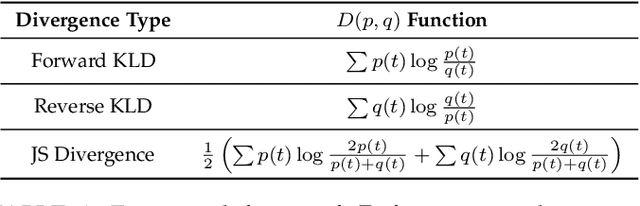
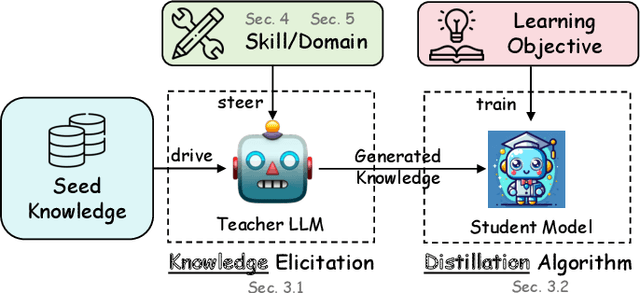

In the era of Large Language Models (LLMs), Knowledge Distillation (KD) emerges as a pivotal methodology for transferring advanced capabilities from leading proprietary LLMs, such as GPT-4, to their open-source counterparts like LLaMA and Mistral. Additionally, as open-source LLMs flourish, KD plays a crucial role in both compressing these models, and facilitating their self-improvement by employing themselves as teachers. This paper presents a comprehensive survey of KD's role within the realm of LLM, highlighting its critical function in imparting advanced knowledge to smaller models and its utility in model compression and self-improvement. Our survey is meticulously structured around three foundational pillars: \textit{algorithm}, \textit{skill}, and \textit{verticalization} -- providing a comprehensive examination of KD mechanisms, the enhancement of specific cognitive abilities, and their practical implications across diverse fields. Crucially, the survey navigates the intricate interplay between data augmentation (DA) and KD, illustrating how DA emerges as a powerful paradigm within the KD framework to bolster LLMs' performance. By leveraging DA to generate context-rich, skill-specific training data, KD transcends traditional boundaries, enabling open-source models to approximate the contextual adeptness, ethical alignment, and deep semantic insights characteristic of their proprietary counterparts. This work aims to provide an insightful guide for researchers and practitioners, offering a detailed overview of current methodologies in KD and proposing future research directions. Importantly, we firmly advocate for compliance with the legal terms that regulate the use of LLMs, ensuring ethical and lawful application of KD of LLMs. An associated Github repository is available at https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs.
Leveraging Large Language Models for NLG Evaluation: A Survey
Jan 13, 2024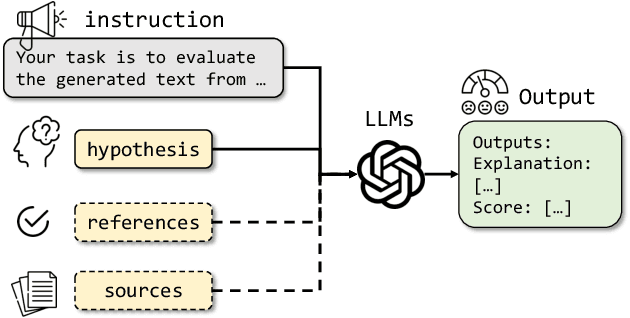
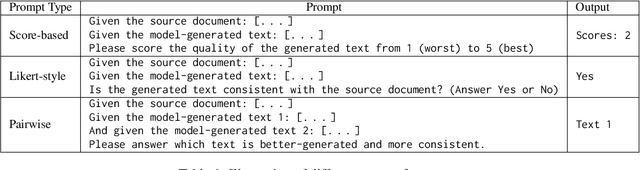
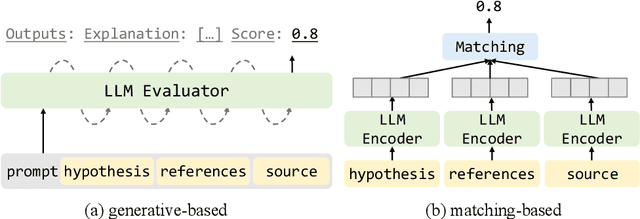
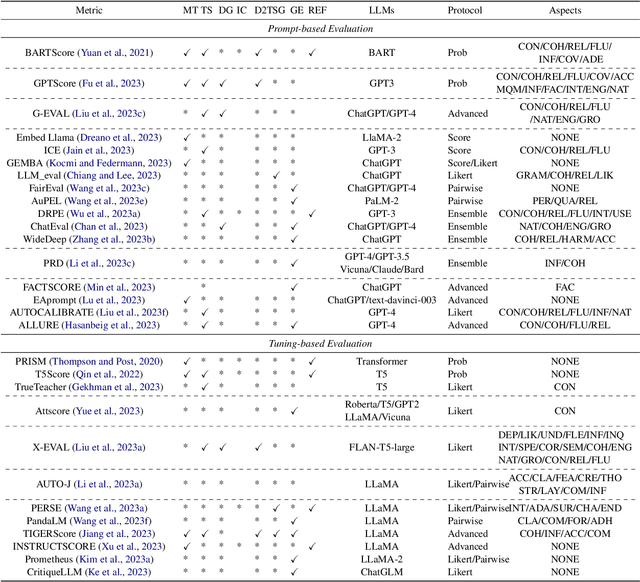
In the rapidly evolving domain of Natural Language Generation (NLG) evaluation, introducing Large Language Models (LLMs) has opened new avenues for assessing generated content quality, e.g., coherence, creativity, and context relevance. This survey aims to provide a thorough overview of leveraging LLMs for NLG evaluation, a burgeoning area that lacks a systematic analysis. We propose a coherent taxonomy for organizing existing LLM-based evaluation metrics, offering a structured framework to understand and compare these methods. Our detailed exploration includes critically assessing various LLM-based methodologies, as well as comparing their strengths and limitations in evaluating NLG outputs. By discussing unresolved challenges, including bias, robustness, domain-specificity, and unified evaluation, this survey seeks to offer insights to researchers and advocate for fairer and more advanced NLG evaluation techniques.
Re-Reading Improves Reasoning in Language Models
Sep 12, 2023Reasoning presents a significant and challenging issue for Large Language Models (LLMs). The predominant focus of research has revolved around developing diverse prompting strategies to guide and structure the reasoning processes of LLMs. However, these approaches based on decoder-only causal language models often operate the input question in a single forward pass, potentially missing the rich, back-and-forth interactions inherent in human reasoning. Scant attention has been paid to a critical dimension, i.e., the input question itself embedded within the prompts. In response, we introduce a deceptively simple yet highly effective prompting strategy, termed question "re-reading". Drawing inspiration from human learning and problem-solving, re-reading entails revisiting the question information embedded within input prompts. This approach aligns seamlessly with the cognitive principle of reinforcement, enabling LLMs to extract deeper insights, identify intricate patterns, establish more nuanced connections, and ultimately enhance their reasoning capabilities across various tasks. Experiments conducted on a series of reasoning benchmarks serve to underscore the effectiveness and generality of our method. Moreover, our findings demonstrate that our approach seamlessly integrates with various language models, though-eliciting prompting methods, and ensemble techniques, further underscoring its versatility and compatibility in the realm of LLMs.
Cross-modal Contrastive Learning for Multimodal Fake News Detection
Feb 25, 2023Automatic detection of multimodal fake news has gained a widespread attention recently. Many existing approaches seek to fuse unimodal features to produce multimodal news representations. However, the potential of powerful cross-modal contrastive learning methods for fake news detection has not been well exploited. Besides, how to aggregate features from different modalities to boost the performance of the decision-making process is still an open question. To address that, we propose COOLANT, a cross-modal contrastive learning framework for multimodal fake news detection, aiming to achieve more accurate image-text alignment. To further improve the alignment precision, we leverage an auxiliary task to soften the loss term of negative samples during the contrast process. A cross-modal fusion module is developed to learn the cross-modality correlations. An attention mechanism with an attention guidance module is implemented to help effectively and interpretably aggregate the aligned unimodal representations and the cross-modality correlations. Finally, we evaluate the COOLANT and conduct a comparative study on two widely used datasets, Twitter and Weibo. The experimental results demonstrate that our COOLANT outperforms previous approaches by a large margin and achieves new state-of-the-art results on the two datasets.
PoKE: Prior Knowledge Enhanced Emotional Support Conversation with Latent Variable
Oct 23, 2022



Emotional support conversation (ESC) task can utilize various support strategies to help people relieve emotional distress and overcome the problem they face, which have attracted much attention in these years. The emotional support is a critical communication skill that should be trained into dialogue systems. Most existing studies predict support strategy according to current context and provide corresponding emotional support in response. However, these works ignore two significant characteristics of ESC. (a) Abundant prior knowledge exists in historical conversations, such as the responses to similar cases and the general order of support strategies, which has a great reference value for current conversation. (b) There is a one-to-many mapping relationship between context and support strategy, i.e.multiple strategies are reasonable for a single context. It lays a better foundation for the diversity of generations. To take into account these two key factors, we Prior Knowledge Enhanced emotional support conversation with latent variable model, PoKE. The proposed model fully taps the potential of prior knowledge in terms of exemplars and strategy sequence and then utilizes a latent variable to model the one-to-many relationship of support strategy. Furthermore, we introduce a memory schema to effectively incorporate encoded knowledge into decoder. Experiment results on benchmark dataset~(i.e., ESConv) show that our PoKE outperforms existing baselines on both automatic evaluation and human evaluation. Further experiments prove that abundant prior knowledge is conducive to high-quality emotional support, and a well-learned latent variable is critical to the diversity of generations.
Subgraph Neighboring Relations Infomax for Inductive Link Prediction on Knowledge Graphs
Jul 28, 2022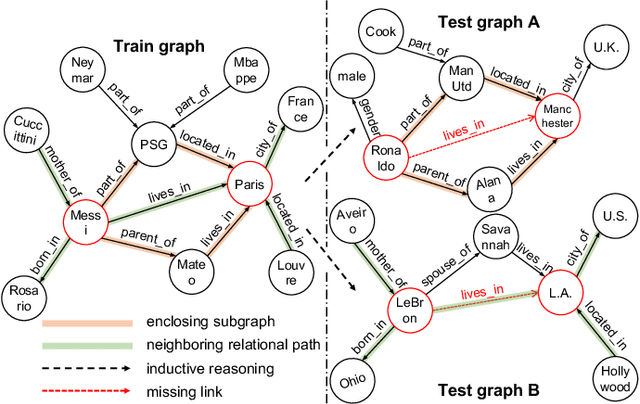

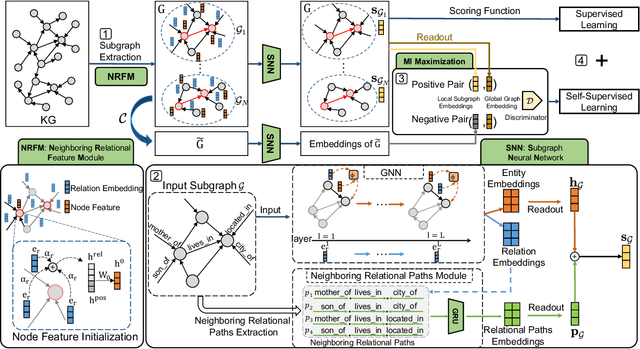
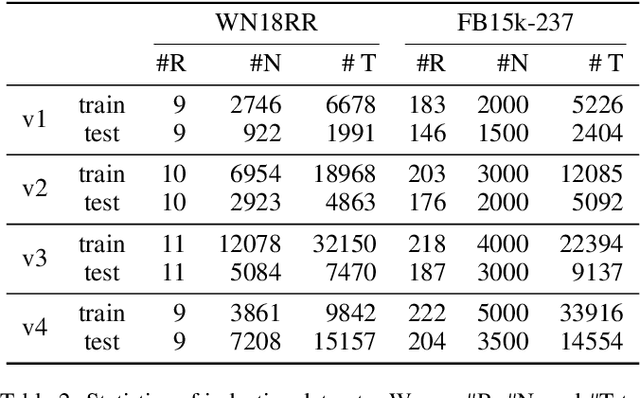
Inductive link prediction for knowledge graph aims at predicting missing links between unseen entities, those not shown in training stage. Most previous works learn entity-specific embeddings of entities, which cannot handle unseen entities. Recent several methods utilize enclosing subgraph to obtain inductive ability. However, all these works only consider the enclosing part of subgraph without complete neighboring relations, which leads to the issue that partial neighboring relations are neglected, and sparse subgraphs are hard to be handled. To address that, we propose Subgraph Neighboring Relations Infomax, SNRI, which sufficiently exploits complete neighboring relations from two aspects: neighboring relational feature for node feature and neighboring relational path for sparse subgraph. To further model neighboring relations in a global way, we innovatively apply mutual information (MI) maximization for knowledge graph. Experiments show that SNRI outperforms existing state-of-art methods by a large margin on inductive link prediction task, and verify the effectiveness of exploring complete neighboring relations in a global way to characterize node features and reason on sparse subgraphs.