 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyFunc: Accelerating LLM-based Function Calls for Agentic AI through Hybrid-Model Cascade and Dynamic Templating
Feb 14, 2026While agentic AI systems rely on LLMs to translate user intent into structured function calls, this process is fraught with computational redundancy, leading to high inference latency that hinders real-time applications. This paper identifies and addresses three key redundancies: (1) the redundant processing of a large library of function descriptions for every request; (2) the redundant use of a large, slow model to generate an entire, often predictable, token sequence; and (3) the redundant generation of fixed, boilerplate parameter syntax. We introduce HyFunc, a novel framework that systematically eliminates these inefficiencies. HyFunc employs a hybrid-model cascade where a large model distills user intent into a single "soft token." This token guides a lightweight retriever to select relevant functions and directs a smaller, prefix-tuned model to generate the final call, thus avoiding redundant context processing and full-sequence generation by the large model. To eliminate syntactic redundancy, our "dynamic templating" technique injects boilerplate parameter syntax on-the-fly within an extended vLLM engine. To avoid potential limitations in generalization, we evaluate HyFunc on an unseen benchmark dataset, BFCL. Experimental results demonstrate that HyFunc achieves an excellent balance between efficiency and performance. It achieves an inference latency of 0.828 seconds, outperforming all baseline models, and reaches a performance of 80.1%, surpassing all models with a comparable parameter scale. These results suggest that HyFunc offers a more efficient paradigm for agentic AI. Our code is publicly available at https://github.com/MrBlankness/HyFunc.
Evaluating LLM-based Agents for Multi-Turn Conversations: A Survey
Mar 28, 2025This survey examines evaluation methods for large language model (LLM)-based agents in multi-turn conversational settings. Using a PRISMA-inspired framework, we systematically reviewed nearly 250 scholarly sources, capturing the state of the art from various venues of publication, and establishing a solid foundation for our analysis. Our study offers a structured approach by developing two interrelated taxonomy systems: one that defines \emph{what to evaluate} and another that explains \emph{how to evaluate}. The first taxonomy identifies key components of LLM-based agents for multi-turn conversations and their evaluation dimensions, including task completion, response quality, user experience, memory and context retention, as well as planning and tool integration. These components ensure that the performance of conversational agents is assessed in a holistic and meaningful manner. The second taxonomy system focuses on the evaluation methodologies. It categorizes approaches into annotation-based evaluations, automated metrics, hybrid strategies that combine human assessments with quantitative measures, and self-judging methods utilizing LLMs. This framework not only captures traditional metrics derived from language understanding, such as BLEU and ROUGE scores, but also incorporates advanced techniques that reflect the dynamic, interactive nature of multi-turn dialogues.
Re-Reading Improves Reasoning in Language Models
Sep 12, 2023Reasoning presents a significant and challenging issue for Large Language Models (LLMs). The predominant focus of research has revolved around developing diverse prompting strategies to guide and structure the reasoning processes of LLMs. However, these approaches based on decoder-only causal language models often operate the input question in a single forward pass, potentially missing the rich, back-and-forth interactions inherent in human reasoning. Scant attention has been paid to a critical dimension, i.e., the input question itself embedded within the prompts. In response, we introduce a deceptively simple yet highly effective prompting strategy, termed question "re-reading". Drawing inspiration from human learning and problem-solving, re-reading entails revisiting the question information embedded within input prompts. This approach aligns seamlessly with the cognitive principle of reinforcement, enabling LLMs to extract deeper insights, identify intricate patterns, establish more nuanced connections, and ultimately enhance their reasoning capabilities across various tasks. Experiments conducted on a series of reasoning benchmarks serve to underscore the effectiveness and generality of our method. Moreover, our findings demonstrate that our approach seamlessly integrates with various language models, though-eliciting prompting methods, and ensemble techniques, further underscoring its versatility and compatibility in the realm of LLMs.
TAPEX: Table Pre-training via Learning a Neural SQL Executor
Jul 16, 2021


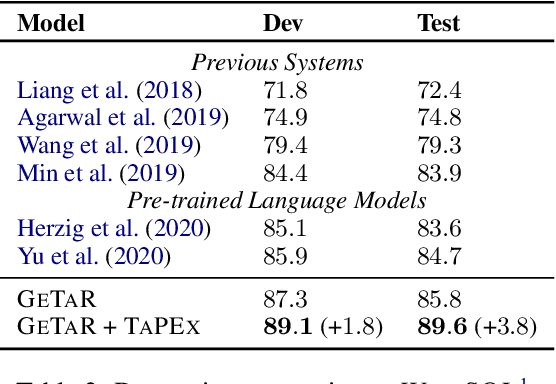
Recent years pre-trained language models hit a success on modeling natural language sentences and (semi-)structured tables. However, existing table pre-training techniques always suffer from low data quality and low pre-training efficiency. In this paper, we show that table pre-training can be realized by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically synthesizing executable SQL queries. By pre-training on the synthetic corpus, our approach TAPEX dramatically improves the performance on downstream tasks, boosting existing language models by at most 19.5%. Meanwhile, TAPEX has remarkably high pre-training efficiency and yields strong results when using a small pre-trained corpus. Experimental results demonstrate that TAPEX outperforms previous table pre-training approaches by a large margin, and our model achieves new state-of-the-art results on four well-known datasets, including improving the WikiSQL denotation accuracy to 89.6% (+4.9%), the WikiTableQuestions denotation accuracy to 57.5% (+4.8%), the SQA denotation accuracy to 74.5% (+3.5%), and the TabFact accuracy to 84.6% (+3.6%). Our work opens the way to reason over structured data by pre-training on synthetic executable programs.