 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap Between Bayesian Deep Learning and Ensemble Weather Forecasts
Nov 18, 2025Weather forecasting is fundamentally challenged by the chaotic nature of the atmosphere, necessitating probabilistic approaches to quantify uncertainty. While traditional ensemble prediction (EPS) addresses this through computationally intensive simulations, recent advances in Bayesian Deep Learning (BDL) offer a promising but often disconnected alternative. We bridge these paradigms through a unified hybrid Bayesian Deep Learning framework for ensemble weather forecasting that explicitly decomposes predictive uncertainty into epistemic and aleatoric components, learned via variational inference and a physics-informed stochastic perturbation scheme modeling flow-dependent atmospheric dynamics, respectively. We further establish a unified theoretical framework that rigorously connects BDL and EPS, providing formal theorems that decompose total predictive uncertainty into epistemic and aleatoric components under the hybrid BDL framework. We validate our framework on the large-scale 40-year ERA5 reanalysis dataset (1979-2019) with 0.25° spatial resolution. Experimental results show that our method not only improves forecast accuracy and yields better-calibrated uncertainty quantification but also achieves superior computational efficiency compared to state-of-the-art probabilistic diffusion models. We commit to making our code open-source upon acceptance of this paper.
Towards AGI in Computer Vision: Lessons Learned from GPT and Large Language Models
Jun 14, 2023



The AI community has been pursuing algorithms known as artificial general intelligence (AGI) that apply to any kind of real-world problem. Recently, chat systems powered by large language models (LLMs) emerge and rapidly become a promising direction to achieve AGI in natural language processing (NLP), but the path towards AGI in computer vision (CV) remains unclear. One may owe the dilemma to the fact that visual signals are more complex than language signals, yet we are interested in finding concrete reasons, as well as absorbing experiences from GPT and LLMs to solve the problem. In this paper, we start with a conceptual definition of AGI and briefly review how NLP solves a wide range of tasks via a chat system. The analysis inspires us that unification is the next important goal of CV. But, despite various efforts in this direction, CV is still far from a system like GPT that naturally integrates all tasks. We point out that the essential weakness of CV lies in lacking a paradigm to learn from environments, yet NLP has accomplished the task in the text world. We then imagine a pipeline that puts a CV algorithm (i.e., an agent) in world-scale, interactable environments, pre-trains it to predict future frames with respect to its action, and then fine-tunes it with instruction to accomplish various tasks. We expect substantial research and engineering efforts to push the idea forward and scale it up, for which we share our perspectives on future research directions.
Pipeline MoE: A Flexible MoE Implementation with Pipeline Parallelism
Apr 22, 2023


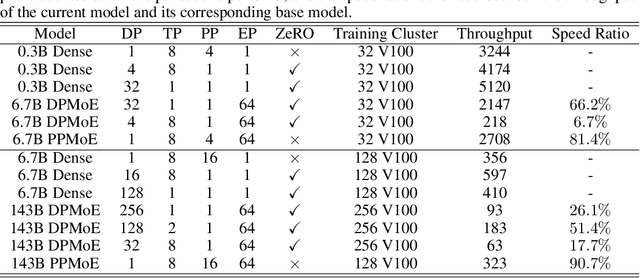
The Mixture of Experts (MoE) model becomes an important choice of large language models nowadays because of its scalability with sublinear computational complexity for training and inference. However, existing MoE models suffer from two critical drawbacks, 1) tremendous inner-node and inter-node communication overhead introduced by all-to-all dispatching and gathering, and 2) limited scalability for the backbone because of the bound data parallel and expert parallel to scale in the expert dimension. In this paper, we systematically analyze these drawbacks in terms of training efficiency in the parallel framework view and propose a novel MoE architecture called Pipeline MoE (PPMoE) to tackle them. PPMoE builds expert parallel incorporating with tensor parallel and replaces communication-intensive all-to-all dispatching and gathering with a simple tensor index slicing and inner-node all-reduce. Besides, it is convenient for PPMoE to integrate pipeline parallel to further scale the backbone due to its flexible parallel architecture. Extensive experiments show that PPMoE not only achieves a more than $1.75\times$ speed up compared to existing MoE architectures but also reaches $90\%$ throughput of its corresponding backbone model that is $20\times$ smaller.
Pangu-Weather: A 3D High-Resolution Model for Fast and Accurate Global Weather Forecast
Nov 03, 2022


In this paper, we present Pangu-Weather, a deep learning based system for fast and accurate global weather forecast. For this purpose, we establish a data-driven environment by downloading $43$ years of hourly global weather data from the 5th generation of ECMWF reanalysis (ERA5) data and train a few deep neural networks with about $256$ million parameters in total. The spatial resolution of forecast is $0.25^\circ\times0.25^\circ$, comparable to the ECMWF Integrated Forecast Systems (IFS). More importantly, for the first time, an AI-based method outperforms state-of-the-art numerical weather prediction (NWP) methods in terms of accuracy (latitude-weighted RMSE and ACC) of all factors (e.g., geopotential, specific humidity, wind speed, temperature, etc.) and in all time ranges (from one hour to one week). There are two key strategies to improve the prediction accuracy: (i) designing a 3D Earth Specific Transformer (3DEST) architecture that formulates the height (pressure level) information into cubic data, and (ii) applying a hierarchical temporal aggregation algorithm to alleviate cumulative forecast errors. In deterministic forecast, Pangu-Weather shows great advantages for short to medium-range forecast (i.e., forecast time ranges from one hour to one week). Pangu-Weather supports a wide range of downstream forecast scenarios, including extreme weather forecast (e.g., tropical cyclone tracking) and large-member ensemble forecast in real-time. Pangu-Weather not only ends the debate on whether AI-based methods can surpass conventional NWP methods, but also reveals novel directions for improving deep learning weather forecast systems.
Weight-Sharing Neural Architecture Search: A Battle to Shrink the Optimization Gap
Aug 05, 2020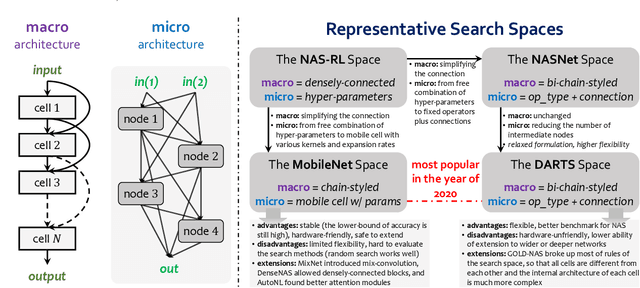
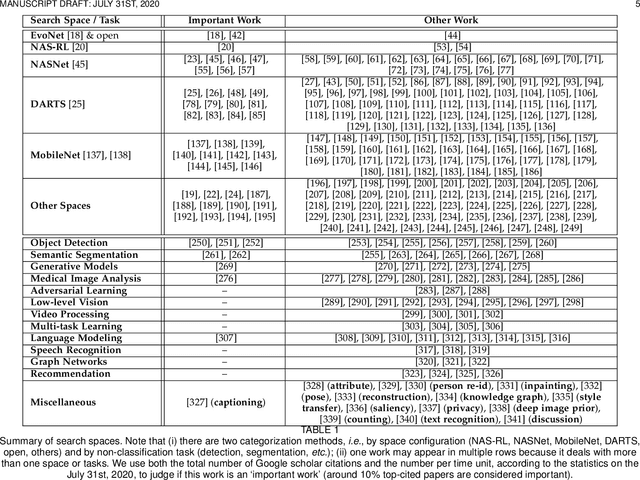
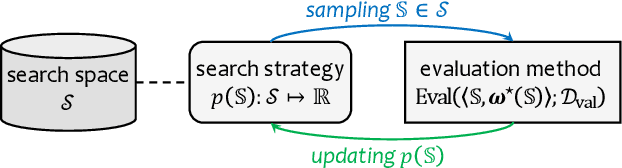
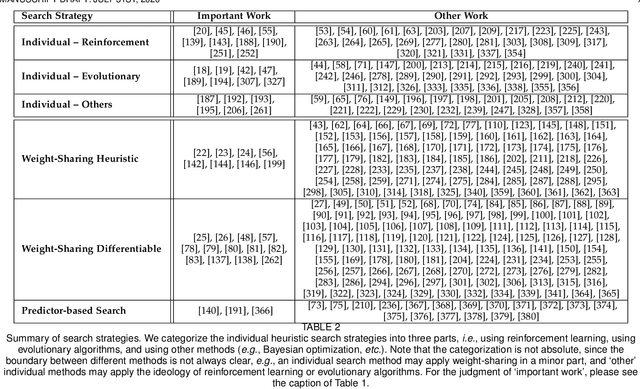
Neural architecture search (NAS) has attracted increasing attentions in both academia and industry. In the early age, researchers mostly applied individual search methods which sample and evaluate the candidate architectures separately and thus incur heavy computational overheads. To alleviate the burden, weight-sharing methods were proposed in which exponentially many architectures share weights in the same super-network, and the costly training procedure is performed only once. These methods, though being much faster, often suffer the issue of instability. This paper provides a literature review on NAS, in particular the weight-sharing methods, and points out that the major challenge comes from the optimization gap between the super-network and the sub-architectures. From this perspective, we summarize existing approaches into several categories according to their efforts in bridging the gap, and analyze both advantages and disadvantages of these methodologies. Finally, we share our opinions on the future directions of NAS and AutoML. Due to the expertise of the authors, this paper mainly focuses on the application of NAS to computer vision problems and may bias towards the work in our group.
GOLD-NAS: Gradual, One-Level, Differentiable
Jul 07, 2020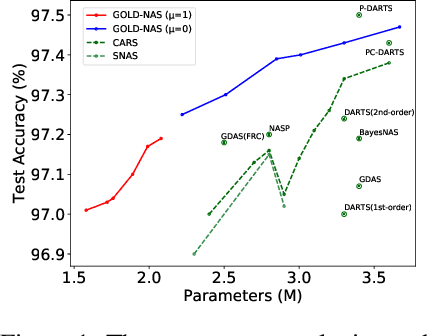

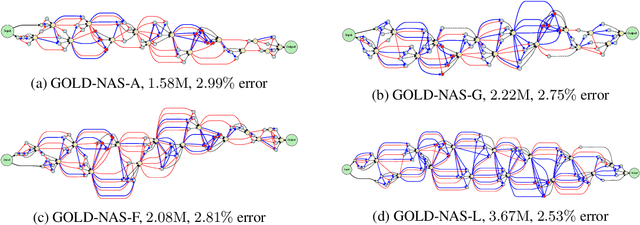
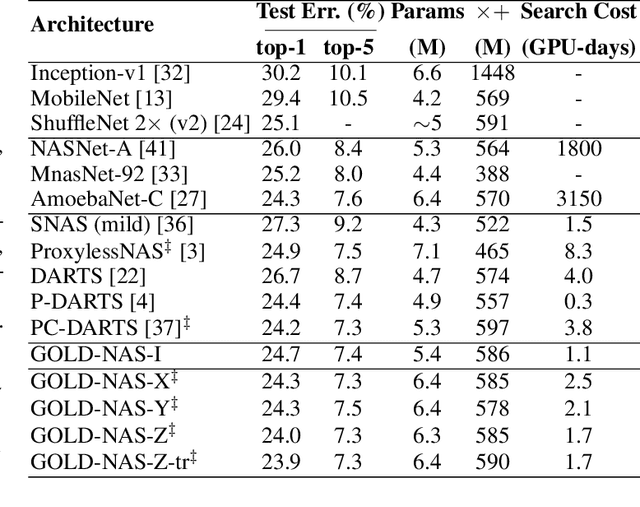
There has been a large literature of neural architecture search, but most existing work made use of heuristic rules that largely constrained the search flexibility. In this paper, we first relax these manually designed constraints and enlarge the search space to contain more than $10^{160}$ candidates. In the new space, most existing differentiable search methods can fail dramatically. We then propose a novel algorithm named Gradual One-Level Differentiable Neural Architecture Search (GOLD-NAS) which introduces a variable resource constraint to one-level optimization so that the weak operators are gradually pruned out from the super-network. In standard image classification benchmarks, GOLD-NAS can find a series of Pareto-optimal architectures within a single search procedure. Most of the discovered architectures were never studied before, yet they achieve a nice tradeoff between recognition accuracy and model complexity. We believe the new space and search algorithm can advance the search of differentiable NAS.
Stabilizing DARTS with Amended Gradient Estimation on Architectural Parameters
Nov 11, 2019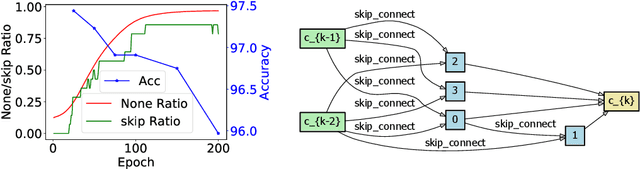



Differentiable neural architecture search has been a popular methodology of exploring architectures for deep learning. Despite the great advantage of search efficiency, it often suffers weak stability, which obstacles it from being applied to a large search space or being flexibly adjusted to different scenarios. This paper investigates DARTS, the currently most popular differentiable search algorithm, and points out an important factor of instability, which lies in its approximation on the gradients of architectural parameters. In the current status, the optimization algorithm can converge to another point which results in dramatic inaccuracy in the re-training process. Based on this analysis, we propose an amending term for computing architectural gradients by making use of a direct property of the optimality of network parameter optimization. Our approach mathematically guarantees that gradient estimation follows a roughly correct direction, which leads the search stage to converge on reasonable architectures. In practice, our algorithm is easily implemented and added to DARTS-based approaches efficiently. Experiments on CIFAR and ImageNet demonstrate that our approach enjoys accuracy gain and, more importantly, enables DARTS-based approaches to explore much larger search spaces that have not been studied before.