 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight-Sharing Neural Architecture Search: A Battle to Shrink the Optimization Gap
Aug 05, 2020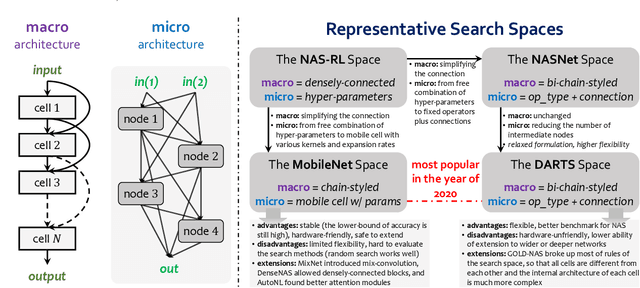
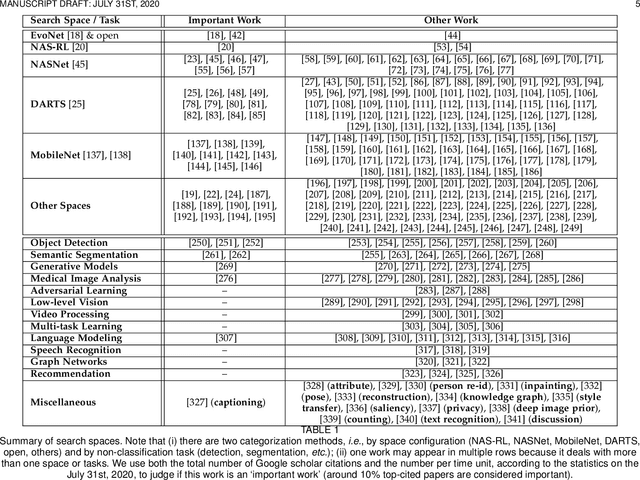
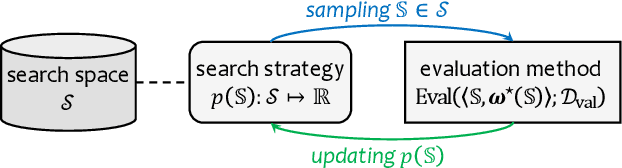
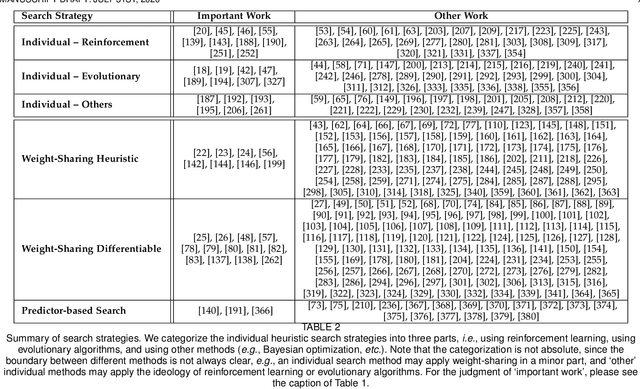
Neural architecture search (NAS) has attracted increasing attentions in both academia and industry. In the early age, researchers mostly applied individual search methods which sample and evaluate the candidate architectures separately and thus incur heavy computational overheads. To alleviate the burden, weight-sharing methods were proposed in which exponentially many architectures share weights in the same super-network, and the costly training procedure is performed only once. These methods, though being much faster, often suffer the issue of instability. This paper provides a literature review on NAS, in particular the weight-sharing methods, and points out that the major challenge comes from the optimization gap between the super-network and the sub-architectures. From this perspective, we summarize existing approaches into several categories according to their efforts in bridging the gap, and analyze both advantages and disadvantages of these methodologies. Finally, we share our opinions on the future directions of NAS and AutoML. Due to the expertise of the authors, this paper mainly focuses on the application of NAS to computer vision problems and may bias towards the work in our group.
Scalable NAS with Factorizable Architectural Parameters
Dec 31, 2019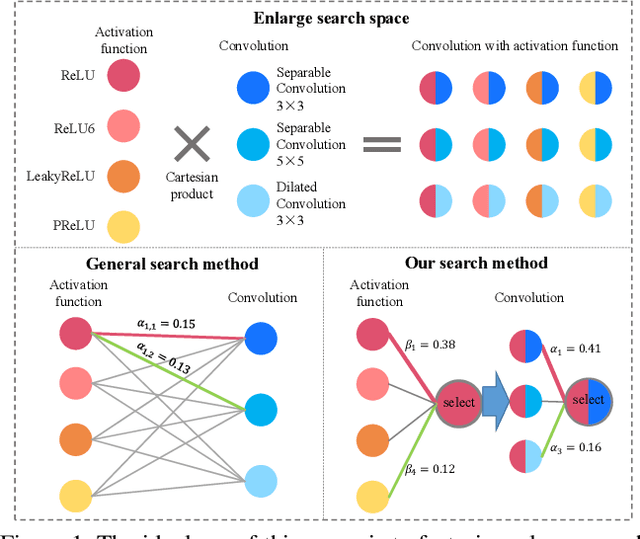


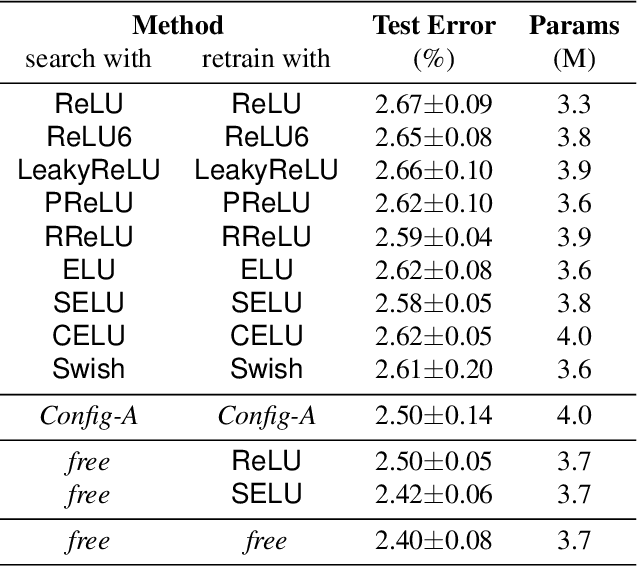
Neural architecture search (NAS) is an emerging topic in machine learning and computer vision. The fundamental ideology of NAS is using an automatic mechanism to replace manual designs for exploring powerful network architectures. One of the key factors of NAS is to scale-up the search space, e.g., increasing the number of operators, so that more possibilities are covered, but existing search algorithms often get lost in a large number of operators. This paper presents a scalable NAS algorithm by designing a factorizable set of architectural parameters, so that the size of the search space goes up quadratically while the burden of optimization increases linearly. As a practical example, we add a set of activation functions to the original set containing convolution, pooling and skip-connect, etc. With a marginal increase in search costs and no extra costs in retraining, we can find interesting architectures that were not explored before and achieve state-of-the-art performance in CIFAR10 and ImageNet, two standard image classification benchmarks.