 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Road with GPT-4V: Early Explorations of Visual-Language Model on Autonomous Driving
Nov 28, 2023The pursuit of autonomous driving technology hinges on the sophisticated integration of perception, decision-making, and control systems. Traditional approaches, both data-driven and rule-based, have been hindered by their inability to grasp the nuance of complex driving environments and the intentions of other road users. This has been a significant bottleneck, particularly in the development of common sense reasoning and nuanced scene understanding necessary for safe and reliable autonomous driving. The advent of Visual Language Models (VLM) represents a novel frontier in realizing fully autonomous vehicle driving. This report provides an exhaustive evaluation of the latest state-of-the-art VLM, GPT-4V(ision), and its application in autonomous driving scenarios. We explore the model's abilities to understand and reason about driving scenes, make decisions, and ultimately act in the capacity of a driver. Our comprehensive tests span from basic scene recognition to complex causal reasoning and real-time decision-making under varying conditions. Our findings reveal that GPT-4V demonstrates superior performance in scene understanding and causal reasoning compared to existing autonomous systems. It showcases the potential to handle out-of-distribution scenarios, recognize intentions, and make informed decisions in real driving contexts. However, challenges remain, particularly in direction discernment, traffic light recognition, vision grounding, and spatial reasoning tasks. These limitations underscore the need for further research and development. Project is now available on GitHub for interested parties to access and utilize: \url{https://github.com/PJLab-ADG/GPT4V-AD-Exploration}
Transform-Invariant Convolutional Neural Networks for Image Classification and Search
Nov 28, 2019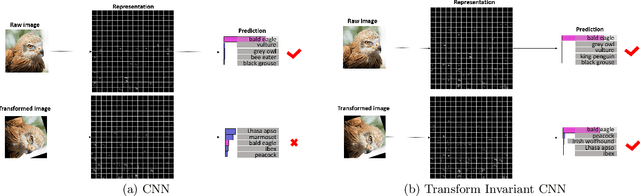
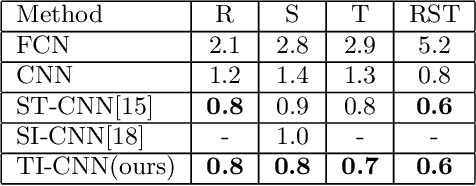

Convolutional neural networks (CNNs) have achieved state-of-the-art results on many visual recognition tasks. However, current CNN models still exhibit a poor ability to be invariant to spatial transformations of images. Intuitively, with sufficient layers and parameters, hierarchical combinations of convolution (matrix multiplication and non-linear activation) and pooling operations should be able to learn a robust mapping from transformed input images to transform-invariant representations. In this paper, we propose randomly transforming (rotation, scale, and translation) feature maps of CNNs during the training stage. This prevents complex dependencies of specific rotation, scale, and translation levels of training images in CNN models. Rather, each convolutional kernel learns to detect a feature that is generally helpful for producing the transform-invariant answer given the combinatorially large variety of transform levels of its input feature maps. In this way, we do not require any extra training supervision or modification to the optimization process and training images. We show that random transformation provides significant improvements of CNNs on many benchmark tasks, including small-scale image recognition, large-scale image recognition, and image retrieval. The code is available at https://github.com/jasonustc/caffe-multigpu/tree/TICNN.
Patch Reordering: a Novel Way to Achieve Rotation and Translation Invariance in Convolutional Neural Networks
Nov 28, 2019
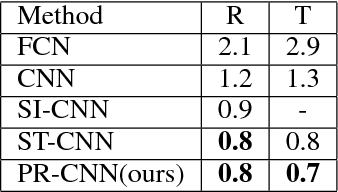
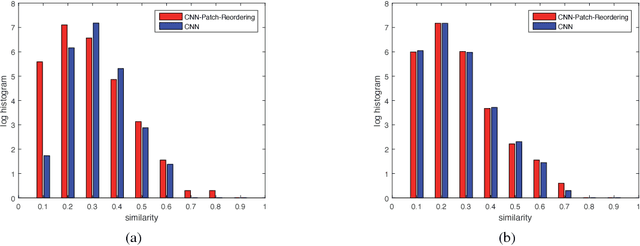
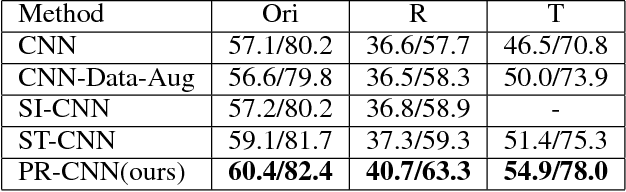
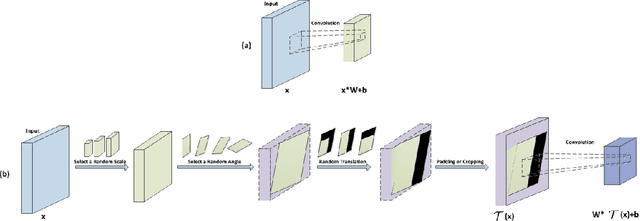
Convolutional Neural Networks (CNNs) have demonstrated state-of-the-art performance on many visual recognition tasks. However, the combination of convolution and pooling operations only shows invariance to small local location changes in meaningful objects in input. Sometimes, such networks are trained using data augmentation to encode this invariance into the parameters, which restricts the capacity of the model to learn the content of these objects. A more efficient use of the parameter budget is to encode rotation or translation invariance into the model architecture, which relieves the model from the need to learn them. To enable the model to focus on learning the content of objects other than their locations, we propose to conduct patch ranking of the feature maps before feeding them into the next layer. When patch ranking is combined with convolution and pooling operations, we obtain consistent representations despite the location of meaningful objects in input. We show that the patch ranking module improves the performance of the CNN on many benchmark tasks, including MNIST digit recognition, large-scale image recognition, and image retrieval. The code is available at https://github.com//jasonustc/caffe-multigpu/tree/TICNN .
Person Re-identification in the Wild
Apr 06, 2017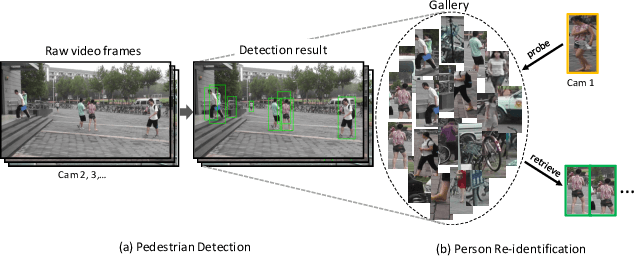



We present a novel large-scale dataset and comprehensive baselines for end-to-end pedestrian detection and person recognition in raw video frames. Our baselines address three issues: the performance of various combinations of detectors and recognizers, mechanisms for pedestrian detection to help improve overall re-identification accuracy and assessing the effectiveness of different detectors for re-identification. We make three distinct contributions. First, a new dataset, PRW, is introduced to evaluate Person Re-identification in the Wild, using videos acquired through six synchronized cameras. It contains 932 identities and 11,816 frames in which pedestrians are annotated with their bounding box positions and identities. Extensive benchmarking results are presented on this dataset. Second, we show that pedestrian detection aids re-identification through two simple yet effective improvements: a discriminatively trained ID-discriminative Embedding (IDE) in the person subspace using convolutional neural network (CNN) features and a Confidence Weighted Similarity (CWS) metric that incorporates detection scores into similarity measurement. Third, we derive insights in evaluating detector performance for the particular scenario of accurate person re-identification.