 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into Identify-Emphasize Paradigm for Combating Unknown Bias
Feb 22, 2023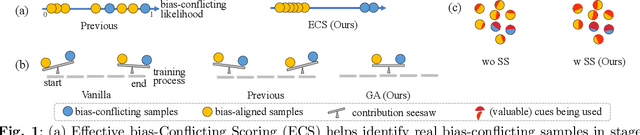

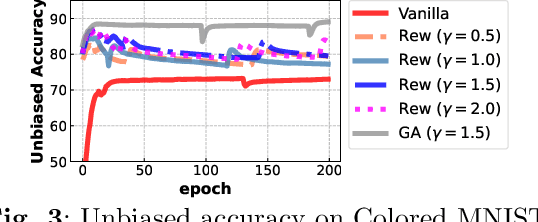

Dataset biases are notoriously detrimental to model robustness and generalization. The identify-emphasize paradigm appears to be effective in dealing with unknown biases. However, we discover that it is still plagued by two challenges: A, the quality of the identified bias-conflicting samples is far from satisfactory; B, the emphasizing strategies only produce suboptimal performance. In this paper, for challenge A, we propose an effective bias-conflicting scoring method (ECS) to boost the identification accuracy, along with two practical strategies -- peer-picking and epoch-ensemble. For challenge B, we point out that the gradient contribution statistics can be a reliable indicator to inspect whether the optimization is dominated by bias-aligned samples. Then, we propose gradient alignment (GA), which employs gradient statistics to balance the contributions of the mined bias-aligned and bias-conflicting samples dynamically throughout the learning process, forcing models to leverage intrinsic features to make fair decisions. Furthermore, we incorporate self-supervised (SS) pretext tasks into training, which enable models to exploit richer features rather than the simple shortcuts, resulting in more robust models. Experiments are conducted on multiple datasets in various settings, demonstrating that the proposed solution can mitigate the impact of unknown biases and achieve state-of-the-art performance.
Transform-Invariant Convolutional Neural Networks for Image Classification and Search
Nov 28, 2019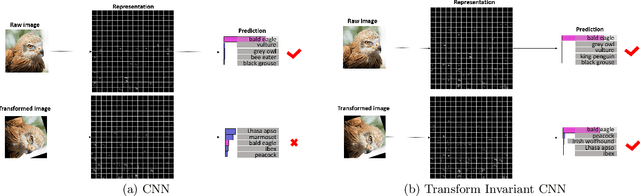
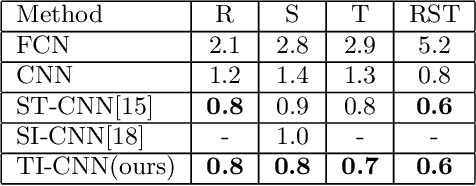
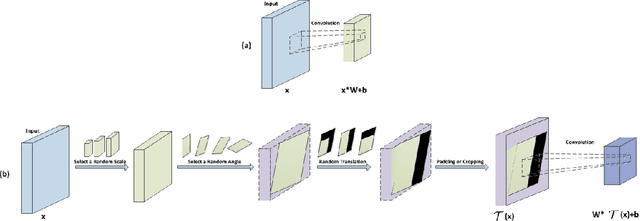

Convolutional neural networks (CNNs) have achieved state-of-the-art results on many visual recognition tasks. However, current CNN models still exhibit a poor ability to be invariant to spatial transformations of images. Intuitively, with sufficient layers and parameters, hierarchical combinations of convolution (matrix multiplication and non-linear activation) and pooling operations should be able to learn a robust mapping from transformed input images to transform-invariant representations. In this paper, we propose randomly transforming (rotation, scale, and translation) feature maps of CNNs during the training stage. This prevents complex dependencies of specific rotation, scale, and translation levels of training images in CNN models. Rather, each convolutional kernel learns to detect a feature that is generally helpful for producing the transform-invariant answer given the combinatorially large variety of transform levels of its input feature maps. In this way, we do not require any extra training supervision or modification to the optimization process and training images. We show that random transformation provides significant improvements of CNNs on many benchmark tasks, including small-scale image recognition, large-scale image recognition, and image retrieval. The code is available at https://github.com/jasonustc/caffe-multigpu/tree/TICNN.
Towards a Better Match in Siamese Network Based Visual Object Tracker
Sep 05, 2018
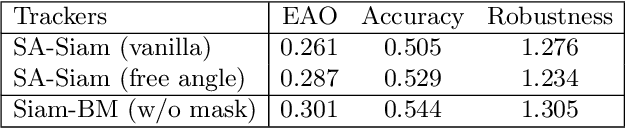

Recently, Siamese network based trackers have received tremendous interest for their fast tracking speed and high performance. Despite the great success, this tracking framework still suffers from several limitations. First, it cannot properly handle large object rotation. Second, tracking gets easily distracted when the background contains salient objects. In this paper, we propose two simple yet effective mechanisms, namely angle estimation and spatial masking, to address these issues. The objective is to extract more representative features so that a better match can be obtained between the same object from different frames. The resulting tracker, named Siam-BM, not only significantly improves the tracking performance, but more importantly maintains the realtime capability. Evaluations on the VOT2017 dataset show that Siam-BM achieves an EAO of 0.335, which makes it the best-performing realtime tracker to date.
A Twofold Siamese Network for Real-Time Object Tracking
Feb 24, 2018
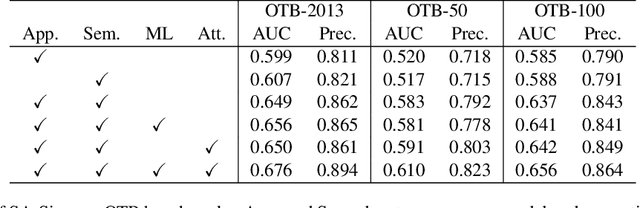
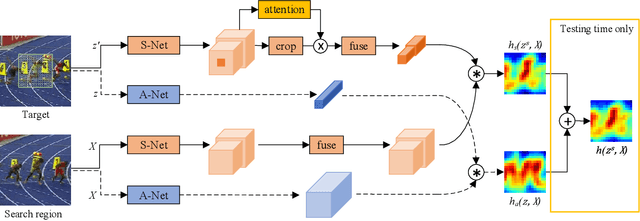
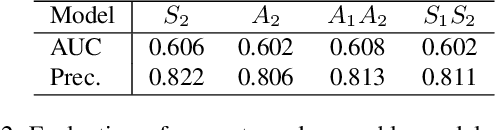
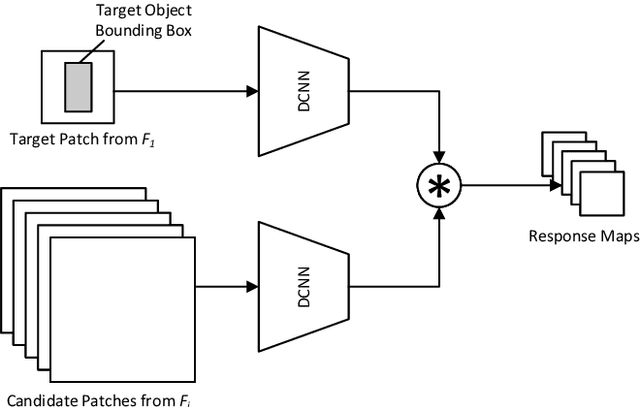
Observing that Semantic features learned in an image classification task and Appearance features learned in a similarity matching task complement each other, we build a twofold Siamese network, named SA-Siam, for real-time object tracking. SA-Siam is composed of a semantic branch and an appearance branch. Each branch is a similarity-learning Siamese network. An important design choice in SA-Siam is to separately train the two branches to keep the heterogeneity of the two types of features. In addition, we propose a channel attention mechanism for the semantic branch. Channel-wise weights are computed according to the channel activations around the target position. While the inherited architecture from SiamFC \cite{SiamFC} allows our tracker to operate beyond real-time, the twofold design and the attention mechanism significantly improve the tracking performance. The proposed SA-Siam outperforms all other real-time trackers by a large margin on OTB-2013/50/100 benchmarks.