 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDAR-EVS: Enhance Extrapolated View Synthesis for 3D Gaussian Splatting with Pseudo-LiDAR Supervision
Mar 16, 20263D Gaussian Splatting (3DGS) has emerged as a powerful technique for real-time LiDAR and camera synthesis in autonomous driving simulation. However, simulating LiDAR with 3DGS remains challenging for extrapolated views beyond the training trajectory, as existing methods are typically trained on single-traversal sensor scans, suffer from severe overfitting and poor generalization to novel ego-vehicle paths. To enable reliable simulation of LiDAR along unseen driving trajectories without external multi-pass data, we present LiDAR-EVS, a lightweight framework for robust extrapolated-view LiDAR simulation in autonomous driving. Designed to be plug-and-play, LiDAR-EVS readily extends to diverse LiDAR sensors and neural rendering baselines with minimal modification. Our framework comprises two key components: (1) pseudo extrapolated-view point cloud supervision with multi-frame LiDAR fusion, view transformation, occlusion curling, and intensity adjustment; (2) spatially-constrained dropout regularization that promotes robustness to diverse trajectory variations encountered in real-world driving. Extensive experiments demonstrate that LiDAR-EVS achieves SOTA performance on extrapolated-view LiDAR synthesis across three datasets, making it a promising tool for data-driven simulation, closed-loop evaluation, and synthetic data generation in autonomous driving systems.
LTM3D: Bridging Token Spaces for Conditional 3D Generation with Auto-Regressive Diffusion Framework
May 30, 2025We present LTM3D, a Latent Token space Modeling framework for conditional 3D shape generation that integrates the strengths of diffusion and auto-regressive (AR) models. While diffusion-based methods effectively model continuous latent spaces and AR models excel at capturing inter-token dependencies, combining these paradigms for 3D shape generation remains a challenge. To address this, LTM3D features a Conditional Distribution Modeling backbone, leveraging a masked autoencoder and a diffusion model to enhance token dependency learning. Additionally, we introduce Prefix Learning, which aligns condition tokens with shape latent tokens during generation, improving flexibility across modalities. We further propose a Latent Token Reconstruction module with Reconstruction-Guided Sampling to reduce uncertainty and enhance structural fidelity in generated shapes. Our approach operates in token space, enabling support for multiple 3D representations, including signed distance fields, point clouds, meshes, and 3D Gaussian Splatting. Extensive experiments on image- and text-conditioned shape generation tasks demonstrate that LTM3D outperforms existing methods in prompt fidelity and structural accuracy while offering a generalizable framework for multi-modal, multi-representation 3D generation.
ResGS: Residual Densification of 3D Gaussian for Efficient Detail Recovery
Dec 10, 2024



Recently, 3D Gaussian Splatting (3D-GS) has prevailed in novel view synthesis, achieving high fidelity and efficiency. However, it often struggles to capture rich details and complete geometry. Our analysis highlights a key limitation of 3D-GS caused by the fixed threshold in densification, which balances geometry coverage against detail recovery as the threshold varies. To address this, we introduce a novel densification method, residual split, which adds a downscaled Gaussian as a residual. Our approach is capable of adaptively retrieving details and complementing missing geometry while enabling progressive refinement. To further support this method, we propose a pipeline named ResGS. Specifically, we integrate a Gaussian image pyramid for progressive supervision and implement a selection scheme that prioritizes the densification of coarse Gaussians over time. Extensive experiments demonstrate that our method achieves SOTA rendering quality. Consistent performance improvements can be achieved by applying our residual split on various 3D-GS variants, underscoring its versatility and potential for broader application in 3D-GS-based applications.
MSSTNet: A Multi-Scale Spatio-Temporal CNN-Transformer Network for Dynamic Facial Expression Recognition
Apr 12, 2024



Unlike typical video action recognition, Dynamic Facial Expression Recognition (DFER) does not involve distinct moving targets but relies on localized changes in facial muscles. Addressing this distinctive attribute, we propose a Multi-Scale Spatio-temporal CNN-Transformer network (MSSTNet). Our approach takes spatial features of different scales extracted by CNN and feeds them into a Multi-scale Embedding Layer (MELayer). The MELayer extracts multi-scale spatial information and encodes these features before sending them into a Temporal Transformer (T-Former). The T-Former simultaneously extracts temporal information while continually integrating multi-scale spatial information. This process culminates in the generation of multi-scale spatio-temporal features that are utilized for the final classification. Our method achieves state-of-the-art results on two in-the-wild datasets. Furthermore, a series of ablation experiments and visualizations provide further validation of our approach's proficiency in leveraging spatio-temporal information within DFER.
* Accepted to 2024 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2024)
Integrated Distributed Semantic Communication and Over-the-air Computation for Cooperative Spectrum Sensing
Nov 08, 2023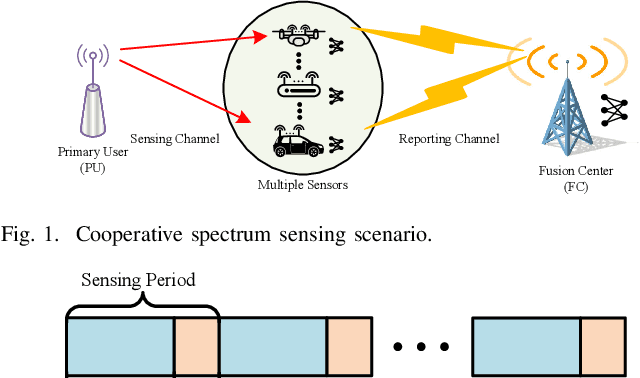
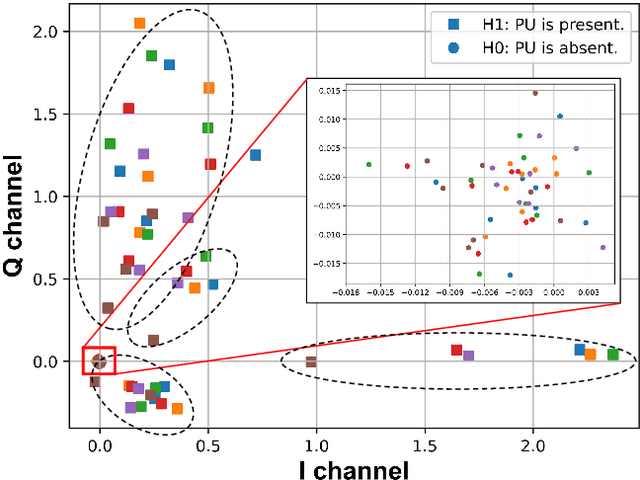
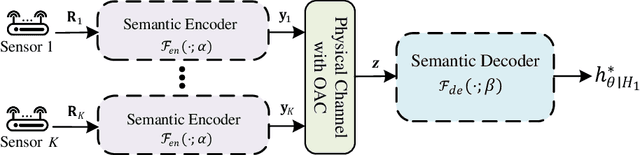
Cooperative spectrum sensing (CSS) is a promising approach to improve the detection of primary users (PUs) using multiple sensors. However, there are several challenges for existing combination methods, i.e., performance degradation and ceiling effect for hard-decision fusion (HDF), as well as significant uploading latency and non-robustness to noise in the reporting channel for soft-data fusion (SDF). To address these issues, in this paper, we propose a novel framework for CSS that integrates communication and computation, namely ICC. Specifically, distributed semantic communication (DSC) jointly optimizes multiple sensors and the fusion center to minimize the transmitted data without degrading detection performance. Moreover, over-the-air computation (AirComp) is utilized to further reduce spectrum occupation in the reporting channel, taking advantage of the characteristics of the wireless channel to enable data aggregation. Under the ICC framework, a particular system, namely ICC-CSS, is designed and implemented, which is theoretically proved to be equivalent to the optimal estimator-correlator (E-C) detector with equal gain SDF when the PU signal samples are independent and identically distributed. Extensive simulations verify the superiority of ICC-CSS compared with various conventional CSS schemes in terms of detection performance, robustness to SNR variations in both the sensing and reporting channels, as well as scalability with respect to the number of samples and sensors.
Deep Learning-Empowered Semantic Communication Systems with a Shared Knowledge Base
Nov 06, 2023Deep learning-empowered semantic communication is regarded as a promising candidate for future 6G networks. Although existing semantic communication systems have achieved superior performance compared to traditional methods, the end-to-end architecture adopted by most semantic communication systems is regarded as a black box, leading to the lack of explainability. To tackle this issue, in this paper, a novel semantic communication system with a shared knowledge base is proposed for text transmissions. Specifically, a textual knowledge base constructed by inherently readable sentences is introduced into our system. With the aid of the shared knowledge base, the proposed system integrates the message and corresponding knowledge from the shared knowledge base to obtain the residual information, which enables the system to transmit fewer symbols without semantic performance degradation. In order to make the proposed system more reliable, the semantic self-information and the source entropy are mathematically defined based on the knowledge base. Furthermore, the knowledge base construction algorithm is developed based on a similarity-comparison method, in which a pre-configured threshold can be leveraged to control the size of the knowledge base. Moreover, the simulation results have demonstrated that the proposed approach outperforms existing baseline methods in terms of transmitted data size and sentence similarity.
Region-Enhanced Feature Learning for Scene Semantic Segmentation
Apr 18, 2023



Semantic segmentation in complex scenes not only relies on local object appearance but also on object locations and the surrounding environment. Nonetheless, it is difficult to model long-range context in the format of pairwise point correlations due to its huge computational cost for large-scale point clouds. In this paper, we propose to use regions as the intermediate representation of point clouds instead of fine-grained points or voxels to reduce the computational burden. We introduce a novel Region-Enhanced Feature Learning network (REFL-Net) that leverages region correlations to enhance the features of ambiguous points. We design a Region-based Feature Enhancement module (RFE) which consists of a Semantic-Spatial Region Extraction (SSRE) stage and a Region Dependency Modeling (RDM) stage. In the SSRE stage, we group the input points into a set of regions according to the point distances in both semantic and spatial space. In the RDM part, we explore region-wise semantic and spatial relationships via a self-attention block on region features and fuse point features with the region features to obtain more discriminative representations. Our proposed RFE module is a plug-and-play module that can be integrated with common semantic segmentation backbones. We conduct extensive experiments on ScanNetv2 and S3DIS datasets, and evaluate our RFE module with different segmentation backbones. Our REFL-Net achieves 1.8% mIoU gain on ScanNetv2 and 1.0% mIoU gain on S3DIS respectively with negligible computational cost compared to the backbone networks. Both quantitative and qualitative results show the powerful long-range context modeling ability and strong generalization ability of our REFL-Net.
Optimization for Master-UAV-powered Auxiliary-Aerial-IRS-assisted IoT Networks: An Option-based Multi-agent Hierarchical Deep Reinforcement Learning Approach
Dec 20, 2021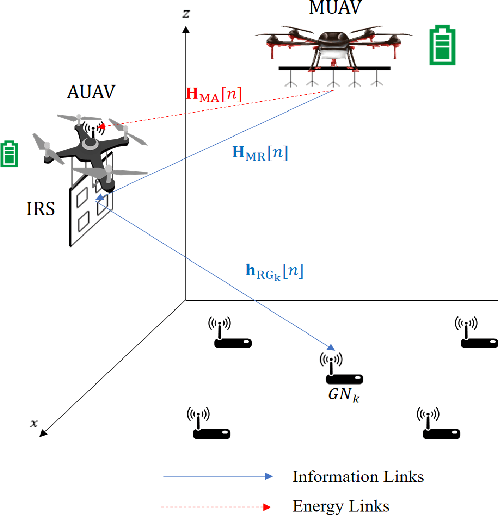
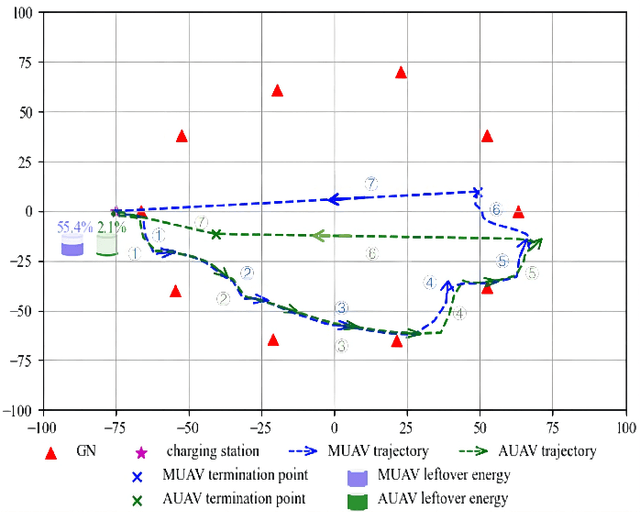
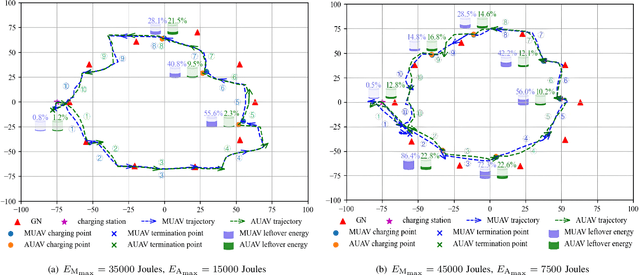
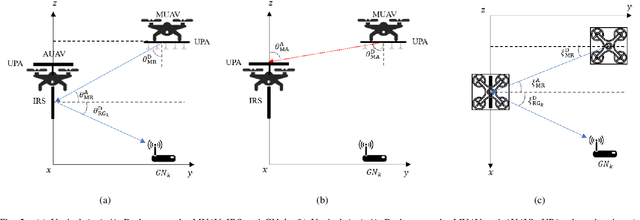
This paper investigates a master unmanned aerial vehicle (MUAV)-powered Internet of Things (IoT) network, in which we propose using a rechargeable auxiliary UAV (AUAV) equipped with an intelligent reflecting surface (IRS) to enhance the communication signals from the MUAV and also leverage the MUAV as a recharging power source. Under the proposed model, we investigate the optimal collaboration strategy of these energy-limited UAVs to maximize the accumulated throughput of the IoT network. Depending on whether there is charging between the two UAVs, two optimization problems are formulated. To solve them, two multi-agent deep reinforcement learning (DRL) approaches are proposed, which are centralized training multi-agent deep deterministic policy gradient (CT-MADDPG) and multi-agent deep deterministic policy option critic (MADDPOC). It is shown that the CT-MADDPG can greatly reduce the requirement on the computing capability of the UAV hardware, and the proposed MADDPOC is able to support low-level multi-agent cooperative learning in the continuous action domains, which has great advantages over the existing option-based hierarchical DRL that only support single-agent learning and discrete actions.