 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Contractive Dynamical Systems
Jan 17, 2024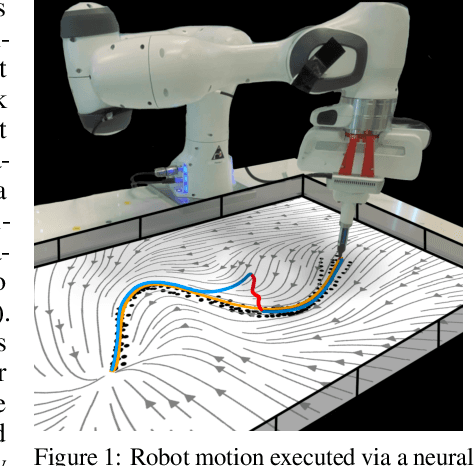


Stability guarantees are crucial when ensuring a fully autonomous robot does not take undesirable or potentially harmful actions. Unfortunately, global stability guarantees are hard to provide in dynamical systems learned from data, especially when the learned dynamics are governed by neural networks. We propose a novel methodology to learn neural contractive dynamical systems, where our neural architecture ensures contraction, and hence, global stability. To efficiently scale the method to high-dimensional dynamical systems, we develop a variant of the variational autoencoder that learns dynamics in a low-dimensional latent representation space while retaining contractive stability after decoding. We further extend our approach to learning contractive systems on the Lie group of rotations to account for full-pose end-effector dynamic motions. The result is the first highly flexible learning architecture that provides contractive stability guarantees with capability to perform obstacle avoidance. Empirically, we demonstrate that our approach encodes the desired dynamics more accurately than the current state-of-the-art, which provides less strong stability guarantees.
Learning Riemannian Stable Dynamical Systems via Diffeomorphisms
Nov 06, 2022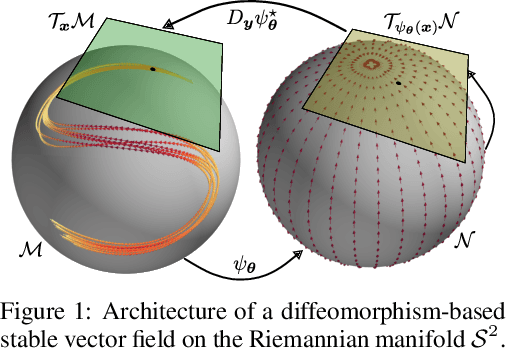

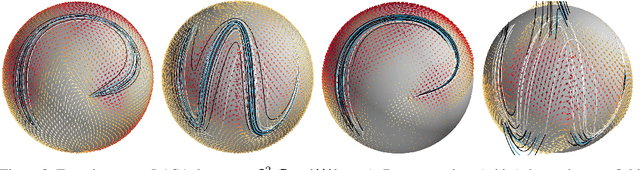
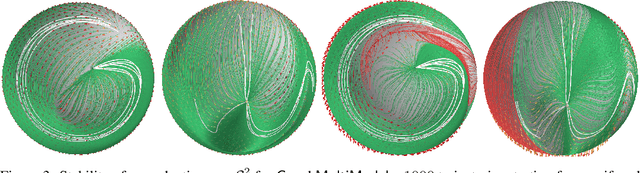
Dexterous and autonomous robots should be capable of executing elaborated dynamical motions skillfully. Learning techniques may be leveraged to build models of such dynamic skills. To accomplish this, the learning model needs to encode a stable vector field that resembles the desired motion dynamics. This is challenging as the robot state does not evolve on a Euclidean space, and therefore the stability guarantees and vector field encoding need to account for the geometry arising from, for example, the orientation representation. To tackle this problem, we propose learning Riemannian stable dynamical systems (RSDS) from demonstrations, allowing us to account for different geometric constraints resulting from the dynamical system state representation. Our approach provides Lyapunov-stability guarantees on Riemannian manifolds that are enforced on the desired motion dynamics via diffeomorphisms built on neural manifold ODEs. We show that our Riemannian approach makes it possible to learn stable dynamical systems displaying complicated vector fields on both illustrative examples and real-world manipulation tasks, where Euclidean approximations fail.
Reactive Motion Generation on Learned Riemannian Manifolds
Mar 15, 2022
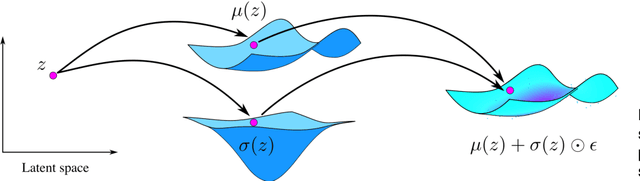
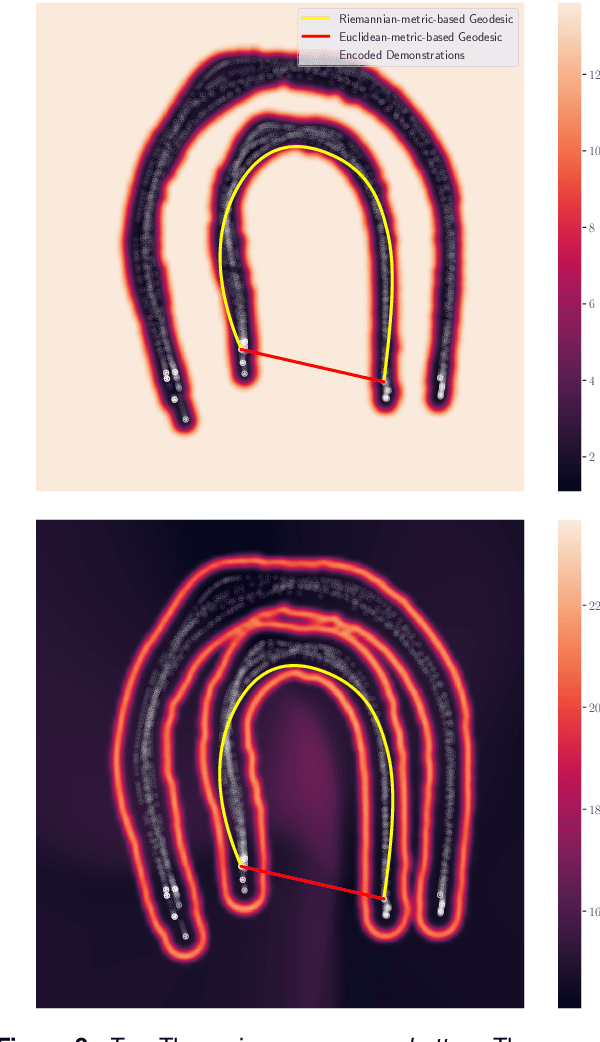
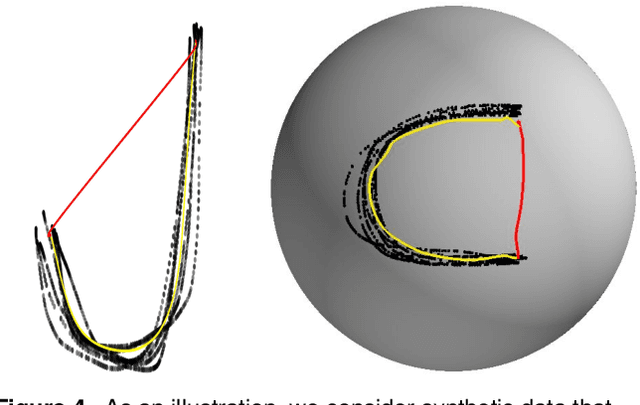
In recent decades, advancements in motion learning have enabled robots to acquire new skills and adapt to unseen conditions in both structured and unstructured environments. In practice, motion learning methods capture relevant patterns and adjust them to new conditions such as dynamic obstacle avoidance or variable targets. In this paper, we investigate the robot motion learning paradigm from a Riemannian manifold perspective. We argue that Riemannian manifolds may be learned via human demonstrations in which geodesics are natural motion skills. The geodesics are generated using a learned Riemannian metric produced by our novel variational autoencoder (VAE), which is especially intended to recover full-pose end-effector states and joint space configurations. In addition, we propose a technique for facilitating on-the-fly end-effector/multiple-limb obstacle avoidance by reshaping the learned manifold using an obstacle-aware ambient metric. The motion generated using these geodesics may naturally result in multiple-solution tasks that have not been explicitly demonstrated previously. We extensively tested our approach in task space and joint space scenarios using a 7-DoF robotic manipulator. We demonstrate that our method is capable of learning and generating motion skills based on complicated motion patterns demonstrated by a human operator. Additionally, we assess several obstacle avoidance strategies and generate trajectories in multiple-mode settings.
Model Mediated Teleoperation with a Hand-Arm Exoskeleton in Long Time Delays Using Reinforcement Learning
Jul 01, 2021
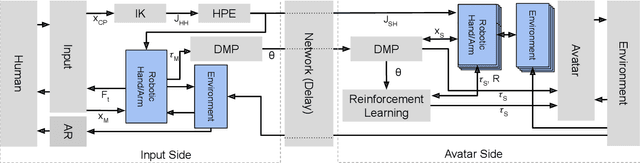
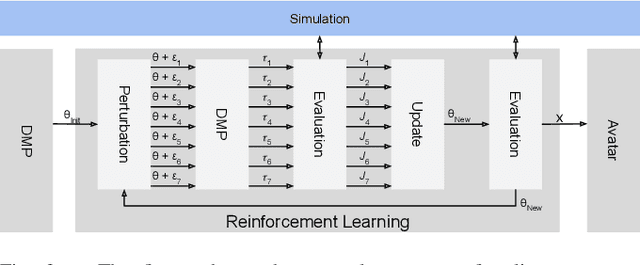
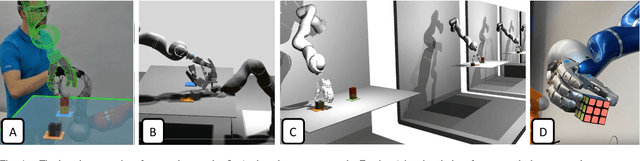
Telerobotic systems must adapt to new environmental conditions and deal with high uncertainty caused by long-time delays. As one of the best alternatives to human-level intelligence, Reinforcement Learning (RL) may offer a solution to cope with these issues. This paper proposes to integrate RL with the Model Mediated Teleoperation (MMT) concept. The teleoperator interacts with a simulated virtual environment, which provides instant feedback. Whereas feedback from the real environment is delayed, feedback from the model is instantaneous, leading to high transparency. The MMT is realized in combination with an intelligent system with two layers. The first layer utilizes Dynamic Movement Primitives (DMP) which accounts for certain changes in the avatar environment. And, the second layer addresses the problems caused by uncertainty in the model using RL methods. Augmented reality was also provided to fuse the avatar device and virtual environment models for the teleoperator. Implemented on DLR's Exodex Adam hand-arm haptic exoskeleton, the results show RL methods are able to find different solutions when changes are applied to the object position after the demonstration. The results also show DMPs to be effective at adapting to new conditions where there is no uncertainty involved.
Learning Riemannian Manifolds for Geodesic Motion Skills
Jun 08, 2021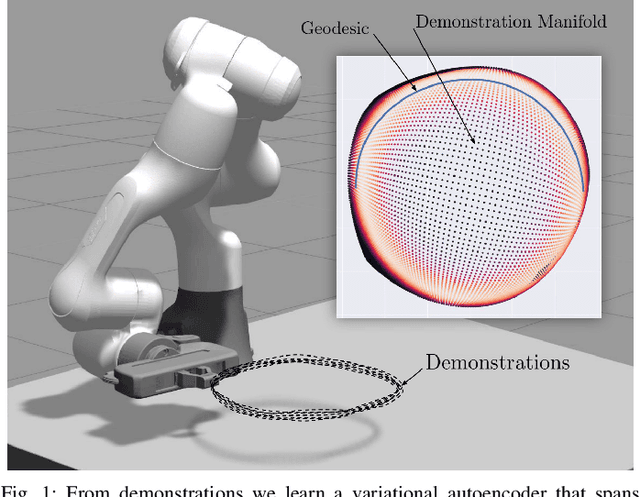


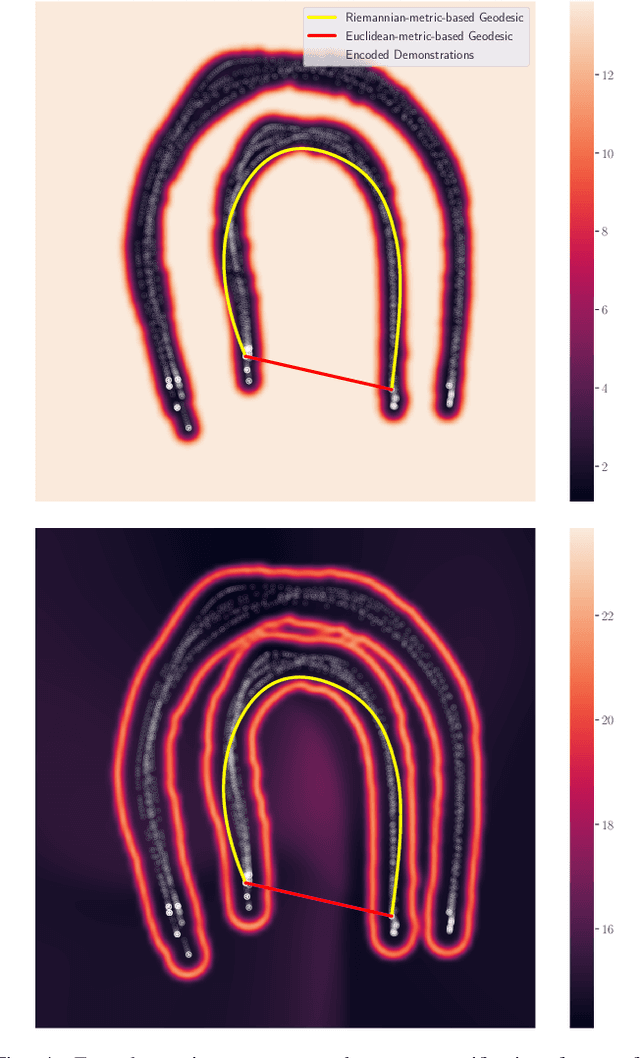
For robots to work alongside humans and perform in unstructured environments, they must learn new motion skills and adapt them to unseen situations on the fly. This demands learning models that capture relevant motion patterns, while offering enough flexibility to adapt the encoded skills to new requirements, such as dynamic obstacle avoidance. We introduce a Riemannian manifold perspective on this problem, and propose to learn a Riemannian manifold from human demonstrations on which geodesics are natural motion skills. We realize this with a variational autoencoder (VAE) over the space of position and orientations of the robot end-effector. Geodesic motion skills let a robot plan movements from and to arbitrary points on the data manifold. They also provide a straightforward method to avoid obstacles by redefining the ambient metric in an online fashion. Moreover, geodesics naturally exploit the manifold resulting from multiple--mode tasks to design motions that were not explicitly demonstrated previously. We test our learning framework using a 7-DoF robotic manipulator, where the robot satisfactorily learns and reproduces realistic skills featuring elaborated motion patterns, avoids previously unseen obstacles, and generates novel movements in multiple-mode settings.