 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuxIA: A Lightweight Unitary matriX-based Framework Built on an Iterative Algorithm for Photonic Neural Network Training
Dec 24, 2025PNNs present promising opportunities for accelerating machine learning by leveraging the unique benefits of photonic circuits. However, current state of the art PNN simulation tools face significant scalability challenges when training large-scale PNNs, due to the computational demands of transfer matrix calculations, resulting in high memory and time consumption. To overcome these limitations, we introduce the Slicing method, an efficient transfer matrix computation approach compatible with back-propagation. We integrate this method into LuxIA, a unified simulation and training framework. The Slicing method substantially reduces memory usage and execution time, enabling scalable simulation and training of large PNNs. Experimental evaluations across various photonic architectures and standard datasets, including MNIST, Digits, and Olivetti Faces, show that LuxIA consistently surpasses existing tools in speed and scalability. Our results advance the state of the art in PNN simulation, making it feasible to explore and optimize larger, more complex architectures. By addressing key computational bottlenecks, LuxIA facilitates broader adoption and accelerates innovation in AI hardware through photonic technologies. This work paves the way for more efficient and scalable photonic neural network research and development.
Invited: Neuromorphic architectures based on augmented silicon photonics platforms
Jul 07, 2024


In this work, we discuss our vision for neuromorphic accelerators based on integrated photonics within the framework of the Horizon Europe NEUROPULS project. Augmented integrated photonic architectures that leverage phase-change and III-V materials for optical computing will be presented. A CMOS-compatible platform will be discussed that integrates these materials to fabricate photonic neuromorphic architectures, along with a gem5-based simulation platform to model accelerator operation once it is interfaced with a RISC-V processor. This simulation platform enables accurate system-level accelerator modeling and benchmarking in terms of key metrics such as speed, energy consumption, and footprint.
Integrated Photonic Reservoir Computing with All-Optical Readout
Jun 28, 2023



Integrated photonic reservoir computing has been demonstrated to be able to tackle different problems because of its neural network nature. A key advantage of photonic reservoir computing over other neuromorphic paradigms is its straightforward readout system, which facilitates both rapid training and robust, fabrication variation-insensitive photonic integrated hardware implementation for real-time processing. We present our recent development of a fully-optical, coherent photonic reservoir chip integrated with an optical readout system, capitalizing on these benefits. Alongside the integrated system, we also demonstrate a weight update strategy that is suitable for the integrated optical readout hardware. Using this online training scheme, we successfully solved 3-bit header recognition and delayed XOR tasks at 20 Gbps in real-time, all within the optical domain without excess delays.
NEUROPULS: NEUROmorphic energy-efficient secure accelerators based on Phase change materials aUgmented siLicon photonicS
May 04, 2023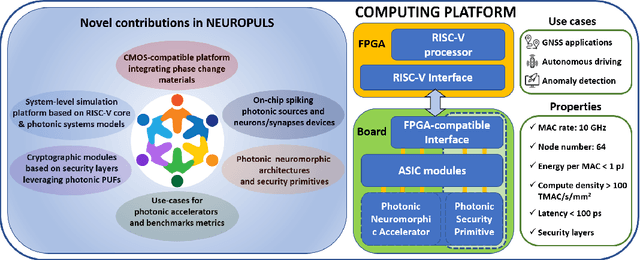
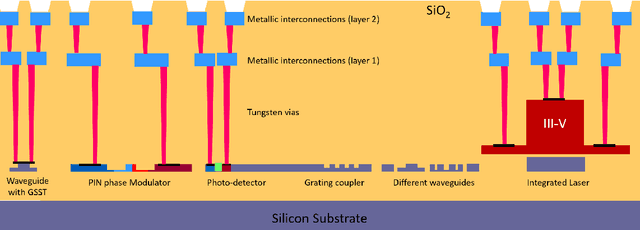
This special session paper introduces the Horizon Europe NEUROPULS project, which targets the development of secure and energy-efficient RISC-V interfaced neuromorphic accelerators using augmented silicon photonics technology. Our approach aims to develop an augmented silicon photonics platform, an FPGA-powered RISC-V-connected computing platform, and a complete simulation platform to demonstrate the neuromorphic accelerator capabilities. In particular, their main advantages and limitations will be addressed concerning the underpinning technology for each platform. Then, we will discuss three targeted use cases for edge-computing applications: Global National Satellite System (GNSS) anti-jamming, autonomous driving, and anomaly detection in edge devices. Finally, we will address the reliability and security aspects of the stand-alone accelerator implementation and the project use cases.
Special Session: Neuromorphic hardware design and reliability from traditional CMOS to emerging technologies
May 02, 2023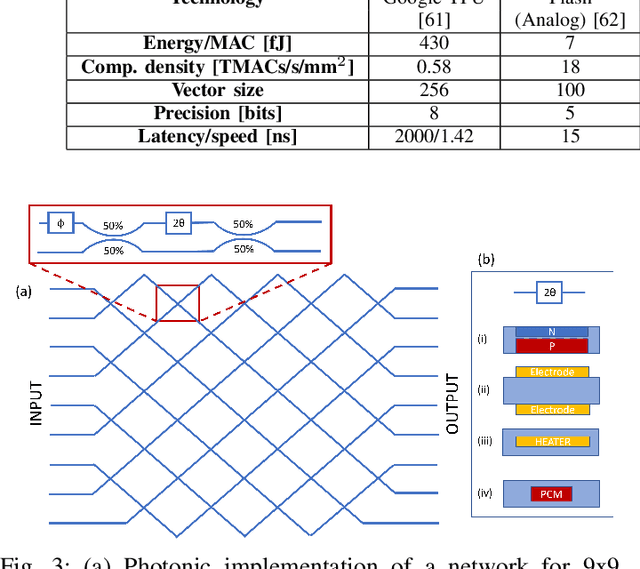
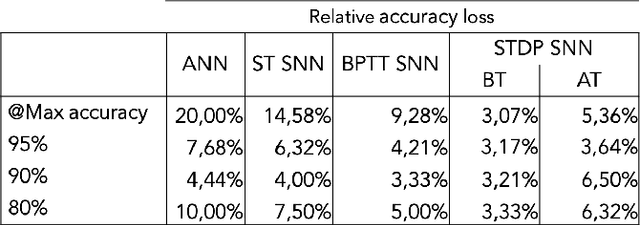
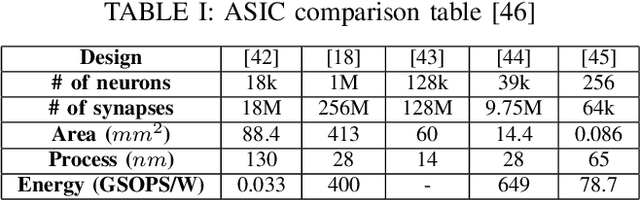
The field of neuromorphic computing has been rapidly evolving in recent years, with an increasing focus on hardware design and reliability. This special session paper provides an overview of the recent developments in neuromorphic computing, focusing on hardware design and reliability. We first review the traditional CMOS-based approaches to neuromorphic hardware design and identify the challenges related to scalability, latency, and power consumption. We then investigate alternative approaches based on emerging technologies, specifically integrated photonics approaches within the NEUROPULS project. Finally, we examine the impact of device variability and aging on the reliability of neuromorphic hardware and present techniques for mitigating these effects. This review is intended to serve as a valuable resource for researchers and practitioners in neuromorphic computing.
Training a spiking neural network on an event-based label-free flow cytometry dataset
Mar 19, 2023

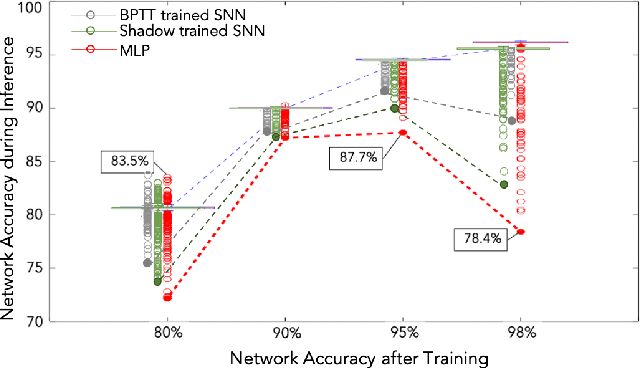
Imaging flow cytometry systems aim to analyze a huge number of cells or micro-particles based on their physical characteristics. The vast majority of current systems acquire a large amount of images which are used to train deep artificial neural networks. However, this approach increases both the latency and power consumption of the final apparatus. In this work-in-progress, we combine an event-based camera with a free-space optical setup to obtain spikes for each particle passing in a microfluidic channel. A spiking neural network is trained on the collected dataset, resulting in 97.7% mean training accuracy and 93.5% mean testing accuracy for the fully event-based classification pipeline.
Towards Deep Physical Reservoir Computing Through Automatic Task Decomposition And Mapping
Oct 25, 2019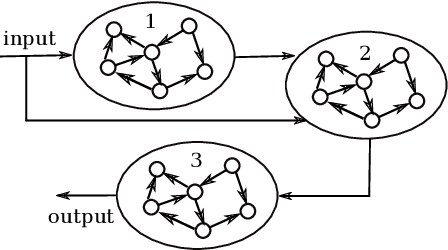

Photonic reservoir computing is a promising candidate for low-energy computing at high bandwidths. Despite recent successes, there are bounds to what one can achieve simply by making photonic reservoirs larger. Therefore, a switch from single-reservoir computing to multi-reservoir and even deep physical reservoir computing is desirable. Given that backpropagation can not be used directly to train multi-reservoir systems in our targeted setting, we propose an alternative approach that still uses its power to derive intermediate targets. In this work we report our findings on a conducted experiment to evaluate the general feasibility of our approach by training a network of 3 Echo State Networks to perform the well-known NARMA-10 task using targets derived through backpropagation. Our results indicate that our proposed method is well-suited to train multi-reservoir systems in a efficient way.
Training Passive Photonic Reservoirs with Integrated Optical Readout
Oct 08, 2018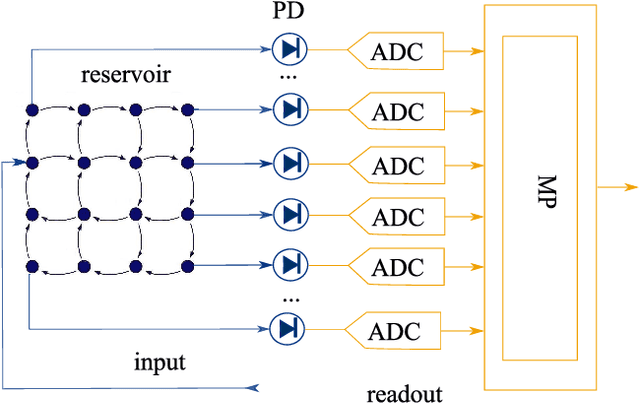

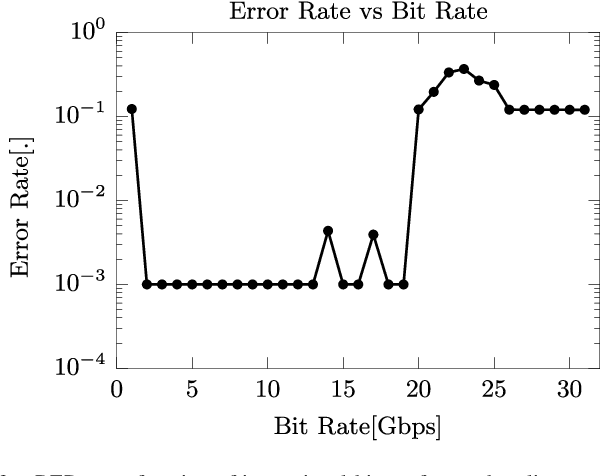

As Moore's law comes to an end, neuromorphic approaches to computing are on the rise. One of these, passive photonic reservoir computing, is a strong candidate for computing at high bitrates (> 10 Gbps) and with low energy consumption. Currently though, both benefits are limited by the necessity to perform training and readout operations in the electrical domain. Thus, efforts are currently underway in the photonic community to design an integrated optical readout, which allows to perform all operations in the optical domain. In addition to the technological challenge of designing such a readout, new algorithms have to be designed in order to train it. Foremost, suitable algorithms need to be able to deal with the fact that the actual on-chip reservoir states are not directly observable. In this work, we investigate several options for such a training algorithm and propose a solution in which the complex states of the reservoir can be observed by appropriately setting the readout weights, while iterating over a predefined input sequence. We perform numerical simulations in order to compare our method with an ideal baseline requiring full observability as well as with an established black-box optimization approach (CMA-ES).
Photonic Delay Systems as Machine Learning Implementations
Jan 12, 2015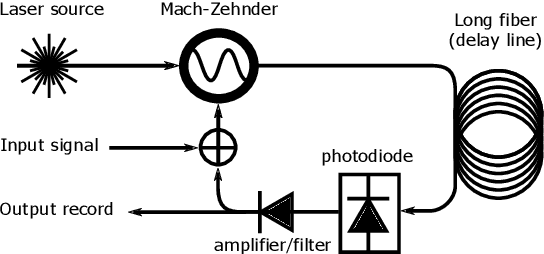
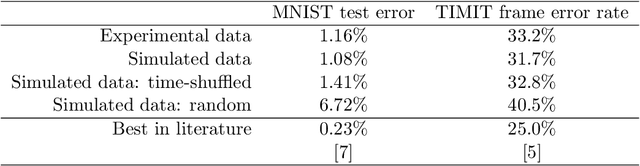
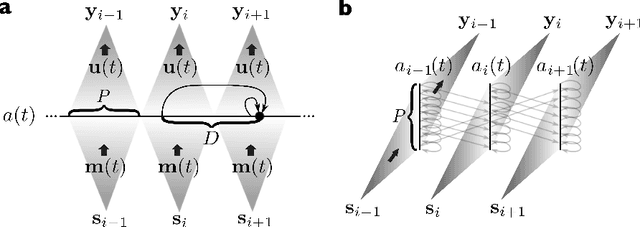

Nonlinear photonic delay systems present interesting implementation platforms for machine learning models. They can be extremely fast, offer great degrees of parallelism and potentially consume far less power than digital processors. So far they have been successfully employed for signal processing using the Reservoir Computing paradigm. In this paper we show that their range of applicability can be greatly extended if we use gradient descent with backpropagation through time on a model of the system to optimize the input encoding of such systems. We perform physical experiments that demonstrate that the obtained input encodings work well in reality, and we show that optimized systems perform significantly better than the common Reservoir Computing approach. The results presented here demonstrate that common gradient descent techniques from machine learning may well be applicable on physical neuro-inspired analog computers.
Trainable and Dynamic Computing: Error Backpropagation through Physical Media
Jul 24, 2014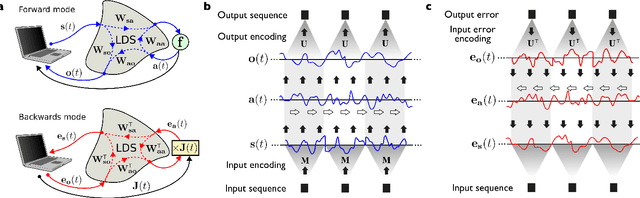


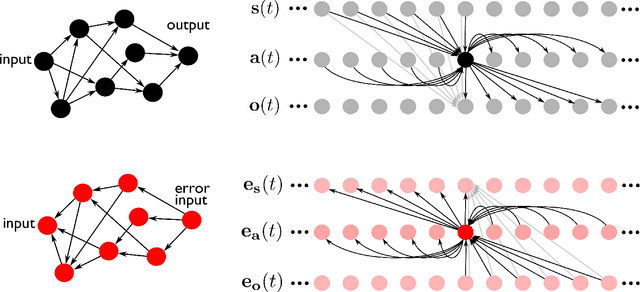
Machine learning algorithms, and more in particular neural networks, arguably experience a revolution in terms of performance. Currently, the best systems we have for speech recognition, computer vision and similar problems are based on neural networks, trained using the half-century old backpropagation algorithm. Despite the fact that neural networks are a form of analog computers, they are still implemented digitally for reasons of convenience and availability. In this paper we demonstrate how we can design physical linear dynamic systems with non-linear feedback as a generic platform for dynamic, neuro-inspired analog computing. We show that a crucial advantage of this setup is that the error backpropagation can be performed physically as well, which greatly speeds up the optimisation process. As we show in this paper, using one experimentally validated and one conceptual example, such systems may be the key to providing a relatively straightforward mechanism for constructing highly scalable, fully dynamic analog computers.