 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresenting Signs as Signs: One-Shot ISLR to Facilitate Functional Sign Language Technologies
Feb 27, 2025



Isolated Sign Language Recognition (ISLR) is crucial for scalable sign language technology, yet language-specific approaches limit current models. To address this, we propose a one-shot learning approach that generalises across languages and evolving vocabularies. Our method involves pretraining a model to embed signs based on essential features and using a dense vector search for rapid, accurate recognition of unseen signs. We achieve state-of-the-art results, including 50.8% one-shot MRR on a large dictionary containing 10,235 unique signs from a different language than the training set. Our approach is robust across languages and support sets, offering a scalable, adaptable solution for ISLR. Co-created with the Deaf and Hard of Hearing (DHH) community, this method aligns with real-world needs, and advances scalable sign language recognition.
Towards the extraction of robust sign embeddings for low resource sign language recognition
Jun 30, 2023Isolated Sign Language Recognition (SLR) has mostly been applied on relatively large datasets containing signs executed slowly and clearly by a limited group of signers. In real-world scenarios, however, we are met with challenging visual conditions, coarticulated signing, small datasets, and the need for signer independent models. To tackle this difficult problem, we require a robust feature extractor to process the sign language videos. One could expect human pose estimators to be ideal candidates. However, due to a domain mismatch with their training sets and challenging poses in sign language, they lack robustness on sign language data and image based models often still outperform keypoint based models. Furthermore, whereas the common practice of transfer learning with image based models yields even higher accuracy, keypoint based models are typically trained from scratch on every SLR dataset. These factors limit their usefulness for SLR. From the existing literature, it is also not clear which, if any, pose estimator performs best for SLR. We compare the three most popular pose estimators for SLR: OpenPose, MMPose and MediaPipe. We show that through keypoint normalization, missing keypoint imputation, and learning a pose embedding, we can obtain significantly better results and enable transfer learning. We show that keypoint-based embeddings contain cross-lingual features: they can transfer between sign languages and achieve competitive performance even when fine-tuning only the classifier layer of an SLR model on a target sign language. We furthermore achieve better performance using fine-tuned transferred embeddings than models trained only on the target sign language. The application of these embeddings could prove particularly useful for low resource sign languages in the future.
Machine Translation from Signed to Spoken Languages: State of the Art and Challenges
Feb 07, 2022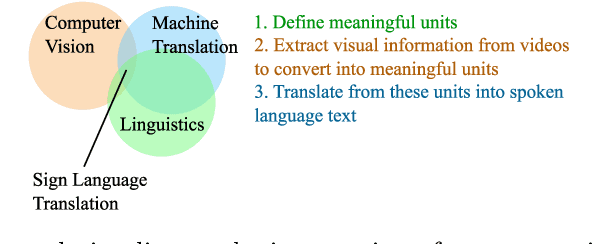
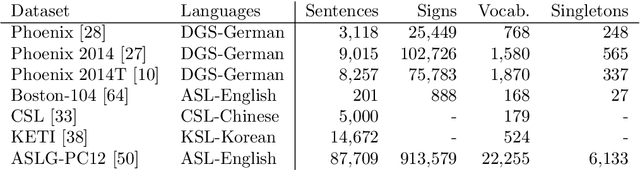

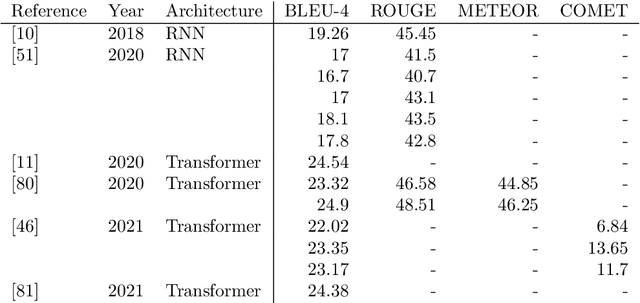
Automatic translation from signed to spoken languages is an interdisciplinary research domain, lying on the intersection of computer vision, machine translation and linguistics. Nevertheless, research in this domain is performed mostly by computer scientists in isolation. As the domain is becoming increasingly popular - the majority of scientific papers on the topic of sign language translation have been published in the past three years - we provide an overview of the state of the art as well as some required background in the different related disciplines. We give a high-level introduction to sign language linguistics and machine translation to illustrate the requirements of automatic sign language translation. We present a systematic literature review to illustrate the state of the art in the domain and then, harking back to the requirements, lay out several challenges for future research. We find that significant advances have been made on the shoulders of spoken language machine translation research. However, current approaches are often not linguistically motivated or are not adapted to the different input modality of sign languages. We explore challenges related to the representation of sign language data, the collection of datasets, the need for interdisciplinary research and requirements for moving beyond research, towards applications. Based on our findings, we advocate for interdisciplinary research and to base future research on linguistic analysis of sign languages. Furthermore, the inclusion of deaf and hearing end users of sign language translation applications in use case identification, data collection and evaluation is of the utmost importance in the creation of useful sign language translation models. We recommend iterative, human-in-the-loop, design and development of sign language translation models.