 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinux Kernel Configurations at Scale: A Dataset for Performance and Evolution Analysis
May 12, 2025

Configuring the Linux kernel to meet specific requirements, such as binary size, is highly challenging due to its immense complexity-with over 15,000 interdependent options evolving rapidly across different versions. Although several studies have explored sampling strategies and machine learning methods to understand and predict the impact of configuration options, the literature still lacks a comprehensive and large-scale dataset encompassing multiple kernel versions along with detailed quantitative measurements. To bridge this gap, we introduce LinuxData, an accessible collection of kernel configurations spanning several kernel releases, specifically from versions 4.13 to 5.8. This dataset, gathered through automated tools and build processes, comprises over 240,000 kernel configurations systematically labeled with compilation outcomes and binary sizes. By providing detailed records of configuration evolution and capturing the intricate interplay among kernel options, our dataset enables innovative research in feature subset selection, prediction models based on machine learning, and transfer learning across kernel versions. Throughout this paper, we describe how the dataset has been made easily accessible via OpenML and illustrate how it can be leveraged using only a few lines of Python code to evaluate AI-based techniques, such as supervised machine learning. We anticipate that this dataset will significantly enhance reproducibility and foster new insights into configuration-space analysis at a scale that presents unique opportunities and inherent challenges, thereby advancing our understanding of the Linux kernel's configurability and evolution.
Unify and Triumph: Polyglot, Diverse, and Self-Consistent Generation of Unit Tests with LLMs
Mar 20, 2025



Large language model (LLM)-based test generation has gained attention in software engineering, yet most studies evaluate LLMs' ability to generate unit tests in a single attempt for a given language, missing the opportunity to leverage LLM diversity for more robust testing. This paper introduces PolyTest, a novel approach that enhances test generation by exploiting polyglot and temperature-controlled diversity. PolyTest systematically leverages these properties in two complementary ways: (1) Cross-lingual test generation, where tests are generated in multiple languages at zero temperature and then unified; (2) Diverse test sampling, where multiple test sets are generated within the same language at a higher temperature before unification. A key insight is that LLMs can generate diverse yet contradicting tests -- same input, different expected outputs -- across languages and generations. PolyTest mitigates inconsistencies by unifying test sets, fostering self-consistency and improving overall test quality. Unlike single-language or single-attempt approaches, PolyTest enhances testing without requiring on-the-fly execution, making it particularly beneficial for weaker-performing languages. We evaluate PolyTest on Llama3-70B, GPT-4o, and GPT-3.5 using EvalPlus, generating tests in five languages (Java, C, Python, JavaScript, and a CSV-based format) at temperature 0 and sampling multiple sets at temperature 1. We observe that LLMs frequently generate contradicting tests across settings, and that PolyTest significantly improves test quality across all considered metrics -- number of tests, passing rate, statement/branch coverage (up to +9.01%), and mutation score (up to +11.23%). Finally, PolyTest outperforms Pynguin in test generation, passing rate, and mutation score.
Piloting Copilot and Codex: Hot Temperature, Cold Prompts, or Black Magic?
Oct 26, 2022



Language models are promising solutions for tackling increasing complex problems. In software engineering, they recently attracted attention in code assistants, with programs automatically written in a given programming language from a programming task description in natural language. They have the potential to save time and effort when writing code. However, these systems are currently poorly understood, preventing them from being used optimally. In this paper, we investigate the various input parameters of two language models, and conduct a study to understand if variations of these input parameters (e.g. programming task description and the surrounding context, creativity of the language model, number of generated solutions) can have a significant impact on the quality of the generated programs. We design specific operators for varying input parameters and apply them over two code assistants (Copilot and Codex) and two benchmarks representing algorithmic problems (HumanEval and LeetCode). Our results showed that varying the input parameters can significantly improve the performance of language models. However, there is a tight dependency when varying the temperature, the prompt and the number of generated solutions, making potentially hard for developers to properly control the parameters to obtain an optimal result. This work opens opportunities to propose (automated) strategies for improving performance.
Towards Quality Assurance of Software Product Lines with Adversarial Configurations
Sep 16, 2019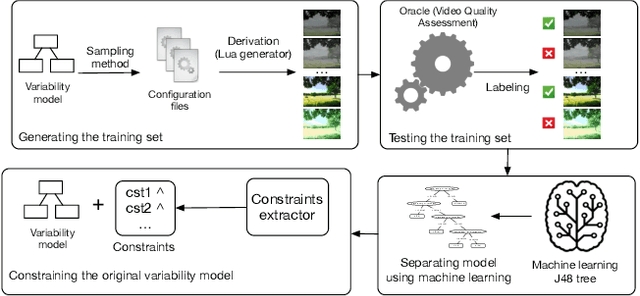
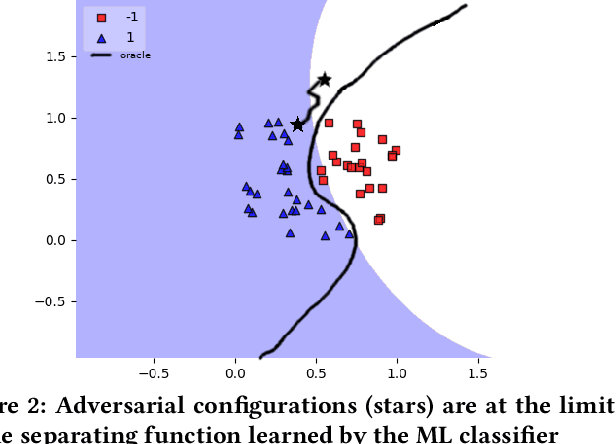

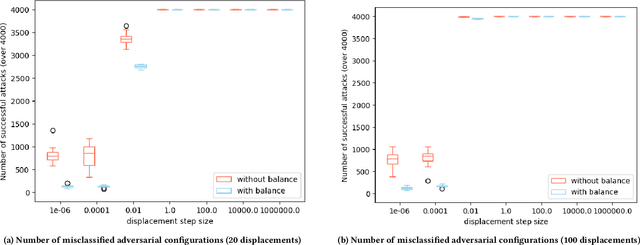
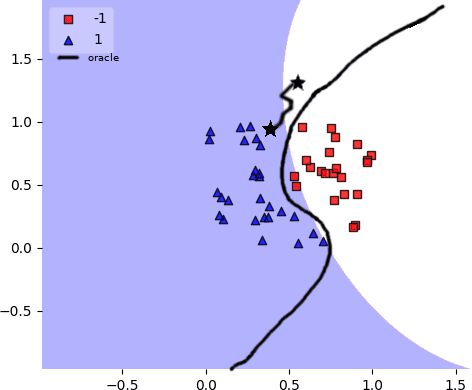
Software product line (SPL) engineers put a lot of effort to ensure that, through the setting of a large number of possible configuration options, products are acceptable and well-tailored to customers' needs. Unfortunately, options and their mutual interactions create a huge configuration space which is intractable to exhaustively explore. Instead of testing all products, machine learning techniques are increasingly employed to approximate the set of acceptable products out of a small training sample of configurations. Machine learning (ML) techniques can refine a software product line through learned constraints and a priori prevent non-acceptable products to be derived. In this paper, we use adversarial ML techniques to generate adversarial configurations fooling ML classifiers and pinpoint incorrect classifications of products (videos) derived from an industrial video generator. Our attacks yield (up to) a 100% misclassification rate and a drop in accuracy of 5%. We discuss the implications these results have on SPL quality assurance.
Learning Software Configuration Spaces: A Systematic Literature Review
Jun 07, 2019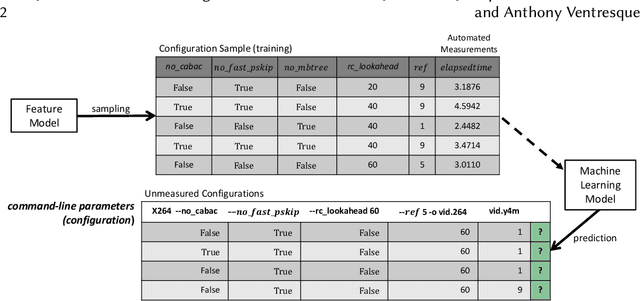

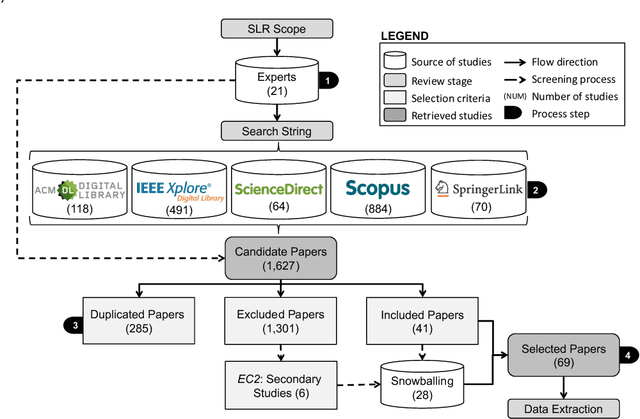
Most modern software systems (operating systems like Linux or Android, Web browsers like Firefox or Chrome, video encoders like ffmpeg, x264 or VLC, mobile and cloud applications, etc.) are highly-configurable. Hundreds of configuration options, features, or plugins can be combined, each potentially with distinct functionality and effects on execution time, security, energy consumption, etc. Due to the combinatorial explosion and the cost of executing software, it is quickly impossible to exhaustively explore the whole configuration space. Hence, numerous works have investigated the idea of learning it from a small sample of configurations' measurements. The pattern "sampling, measuring, learning" has emerged in the literature, with several practical interests for both software developers and end-users of configurable systems. In this survey, we report on the different application objectives (e.g., performance prediction, configuration optimization, constraint mining), use-cases, targeted software systems and application domains. We review the various strategies employed to gather a representative and cost-effective sample. We describe automated software techniques used to measure functional and non-functional properties of configurations. We classify machine learning algorithms and how they relate to the pursued application. Finally, we also describe how researchers evaluate the quality of the learning process. The findings from this systematic review show that the potential application objective is important; there are a vast number of case studies reported in the literature from the basis of several domains and software systems. Yet, the huge variant space of configurable systems is still challenging and calls to further investigate the synergies between artificial intelligence and software engineering.
Towards Adversarial Configurations for Software Product Lines
May 30, 2018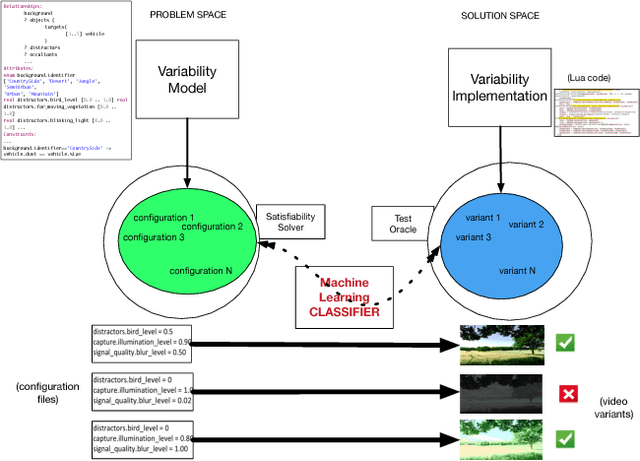

Ensuring that all supposedly valid configurations of a software product line (SPL) lead to well-formed and acceptable products is challenging since it is most of the time impractical to enumerate and test all individual products of an SPL. Machine learning classifiers have been recently used to predict the acceptability of products associated with unseen configurations. For some configurations, a tiny change in their feature values can make them pass from acceptable to non-acceptable regarding users' requirements and vice-versa. In this paper, we introduce the idea of leveraging these specific configurations and their positions in the feature space to improve the classifier and therefore the engineering of an SPL. Starting from a variability model, we propose to use Adversarial Machine Learning techniques to create new, adversarial configurations out of already known configurations by modifying their feature values. Using an industrial video generator we show how adversarial configurations can improve not only the classifier, but also the variability model, the variability implementation, and the testing oracle.
Large-scale Analysis of Chess Games with Chess Engines: A Preliminary Report
Apr 28, 2016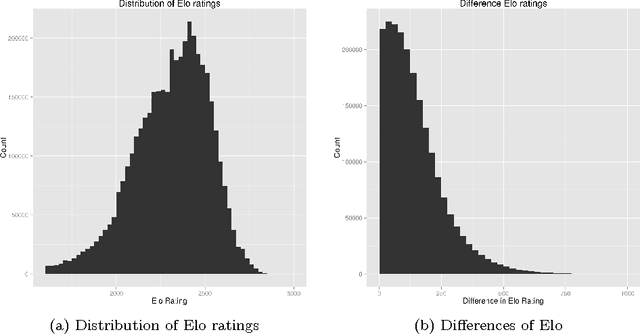
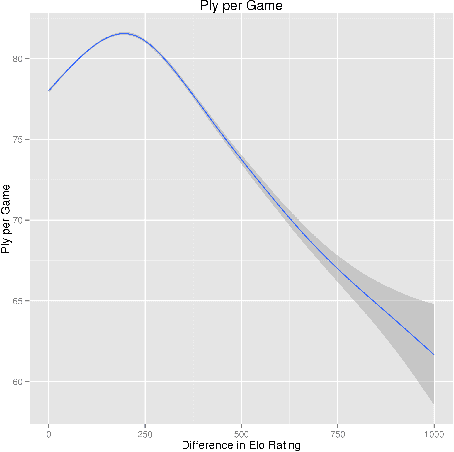
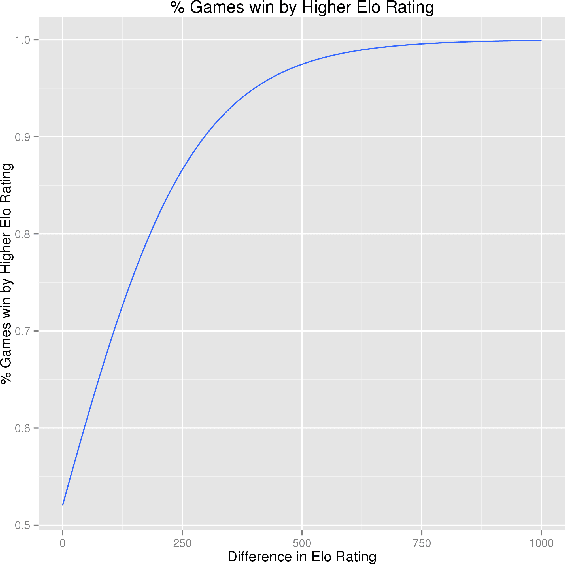
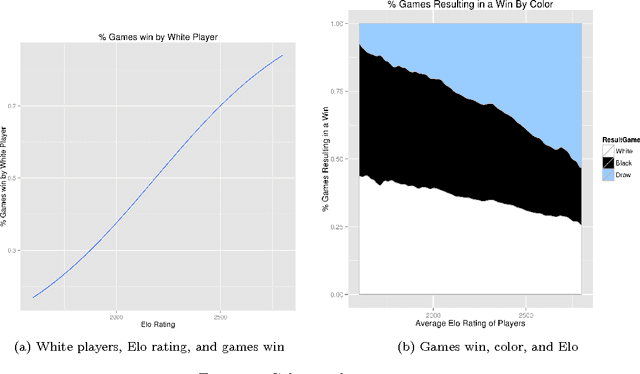
The strength of chess engines together with the availability of numerous chess games have attracted the attention of chess players, data scientists, and researchers during the last decades. State-of-the-art engines now provide an authoritative judgement that can be used in many applications like cheating detection, intrinsic ratings computation, skill assessment, or the study of human decision-making. A key issue for the research community is to gather a large dataset of chess games together with the judgement of chess engines. Unfortunately the analysis of each move takes lots of times. In this paper, we report our effort to analyse almost 5 millions chess games with a computing grid. During summer 2015, we processed 270 millions unique played positions using the Stockfish engine with a quite high depth (20). We populated a database of 1+ tera-octets of chess evaluations, representing an estimated time of 50 years of computation on a single machine. Our effort is a first step towards the replication of research results, the supply of open data and procedures for exploring new directions, and the investigation of software engineering/scalability issues when computing billions of moves.