 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthical Adversaries: Towards Mitigating Unfairness with Adversarial Machine Learning
May 14, 2020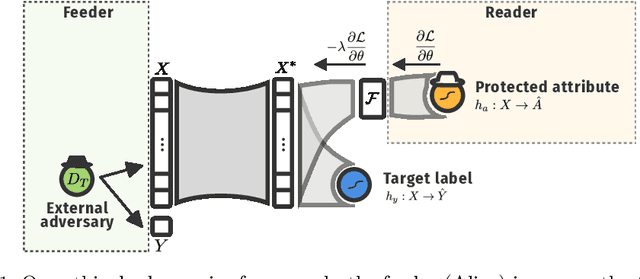
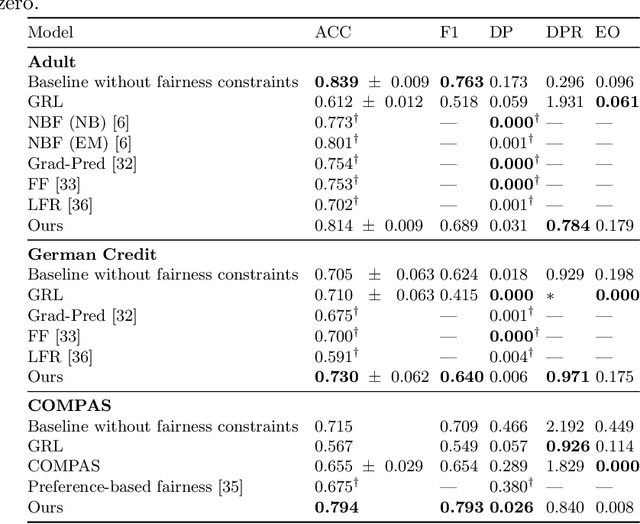
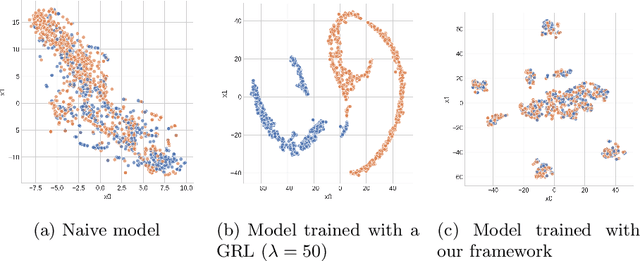
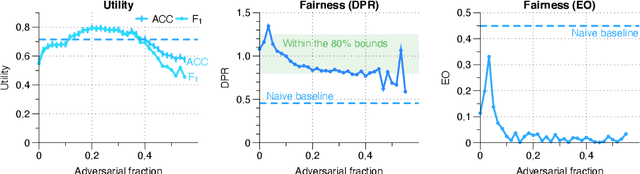
Machine learning is being integrated into a growing number of critical systems with far-reaching impacts on society. Unexpected behaviour and unfair decision processes are coming under increasing scrutiny due to this widespread use and also due to theoretical considerations. Individuals, as well as organisations, notice, test, and criticize unfair results to hold model designers and deployers accountable. This requires transparency and the possibility to describe, measure and, ideally, prove the 'fairness' of a system. This involves concepts such as fairness, transparency and accountability that will hopefully make machine learning more amenable to criticism and improvement proposals towards the fulfilment of societal goals. We concentrate on fairness, taking into account that both the transparency of the neural networks and accountability of actors and systems will require further methods. We offer a new framework that assists in mitigating unfair representations in the dataset used for training. Our framework relies on adversaries to improve fairness. First, it evaluates a model for unfairness w.r.t. protected attributes and ensures that an adversary cannot guess such attributes for a given outcome, by optimizing the model's parameters for fairness while limiting utility losses. Second, the framework leverages evasion attacks from adversarial machine learning to perform adversarial retraining with new examples unseen by the model. These two steps are iteratively applied until a significant improvement in fairness is obtained. We evaluated our framework on well-studied datasets in the fairness literature-including COMPAS-where it can surpass other approaches concerning demographic parity, equality of opportunity and also the model's utility. We also illustrate our findings on the subtle difficulties when mitigating unfairness and highlight how our framework can help model designers.
Towards Quality Assurance of Software Product Lines with Adversarial Configurations
Sep 16, 2019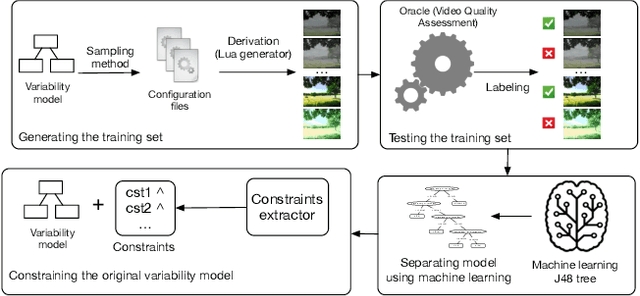
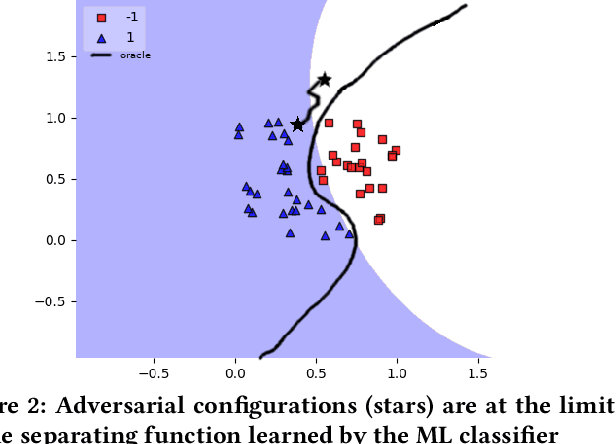

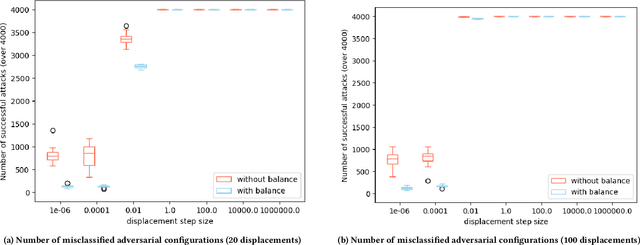
Software product line (SPL) engineers put a lot of effort to ensure that, through the setting of a large number of possible configuration options, products are acceptable and well-tailored to customers' needs. Unfortunately, options and their mutual interactions create a huge configuration space which is intractable to exhaustively explore. Instead of testing all products, machine learning techniques are increasingly employed to approximate the set of acceptable products out of a small training sample of configurations. Machine learning (ML) techniques can refine a software product line through learned constraints and a priori prevent non-acceptable products to be derived. In this paper, we use adversarial ML techniques to generate adversarial configurations fooling ML classifiers and pinpoint incorrect classifications of products (videos) derived from an industrial video generator. Our attacks yield (up to) a 100% misclassification rate and a drop in accuracy of 5%. We discuss the implications these results have on SPL quality assurance.