 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiGL: Large-Scale Graph Neural Networks at Snapchat
Feb 20, 2025Recent advances in graph machine learning (ML) with the introduction of Graph Neural Networks (GNNs) have led to a widespread interest in applying these approaches to business applications at scale. GNNs enable differentiable end-to-end (E2E) learning of model parameters given graph structure which enables optimization towards popular node, edge (link) and graph-level tasks. While the research innovation in new GNN layers and training strategies has been rapid, industrial adoption and utility of GNNs has lagged considerably due to the unique scale challenges that large-scale graph ML problems create. In this work, we share our approach to training, inference, and utilization of GNNs at Snapchat. To this end, we present GiGL (Gigantic Graph Learning), an open-source library to enable large-scale distributed graph ML to the benefit of researchers, ML engineers, and practitioners. We use GiGL internally at Snapchat to manage the heavy lifting of GNN workflows, including graph data preprocessing from relational DBs, subgraph sampling, distributed training, inference, and orchestration. GiGL is designed to interface cleanly with open-source GNN modeling libraries prominent in academia like PyTorch Geometric (PyG), while handling scaling and productionization challenges that make it easier for internal practitioners to focus on modeling. GiGL is used in multiple production settings, and has powered over 35 launches across multiple business domains in the last 2 years in the contexts of friend recommendation, content recommendation and advertising. This work details high-level design and tools the library provides, scaling properties, case studies in diverse business settings with industry-scale graphs, and several key lessons learned in employing graph ML at scale on large social data. GiGL is open-sourced at https://github.com/snap-research/GiGL.
Slow manifolds in recurrent networks encode working memory efficiently and robustly
Jan 08, 2021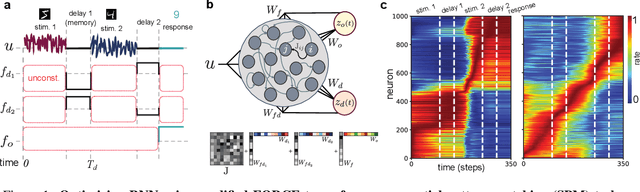
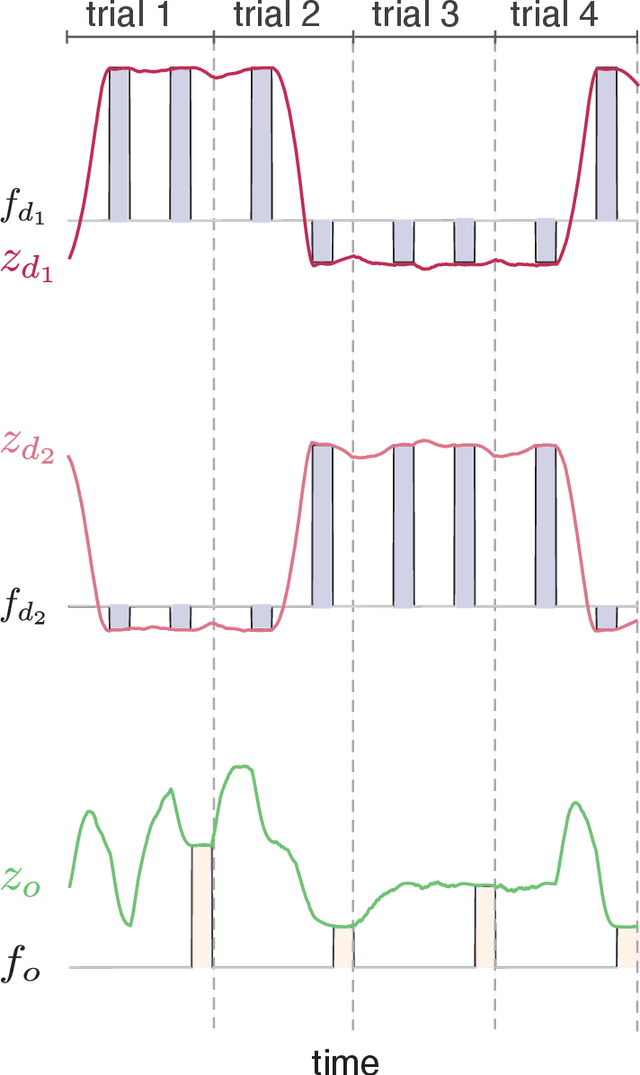
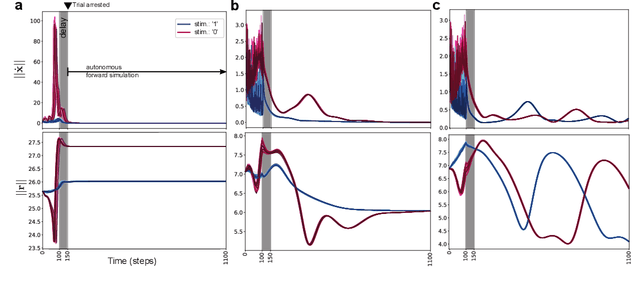
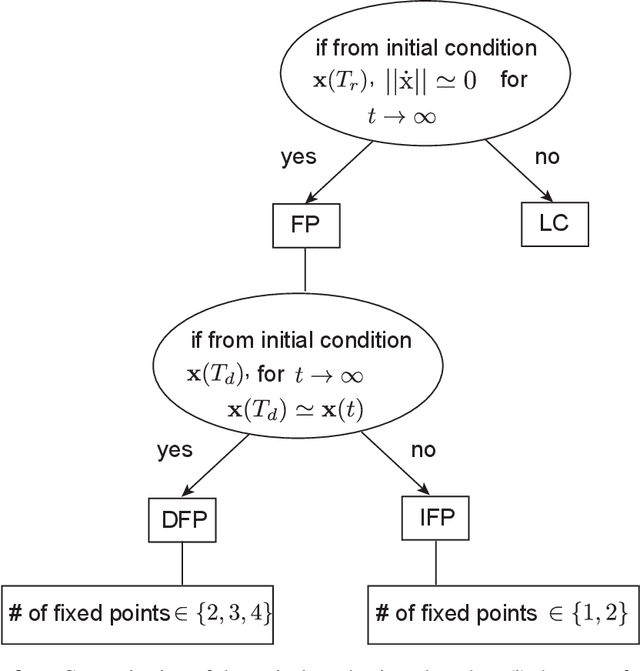
Working memory is a cognitive function involving the storage and manipulation of latent information over brief intervals of time, thus making it crucial for context-dependent computation. Here, we use a top-down modeling approach to examine network-level mechanisms of working memory, an enigmatic issue and central topic of study in neuroscience and machine intelligence. We train thousands of recurrent neural networks on a working memory task and then perform dynamical systems analysis on the ensuing optimized networks, wherein we find that four distinct dynamical mechanisms can emerge. In particular, we show the prevalence of a mechanism in which memories are encoded along slow stable manifolds in the network state space, leading to a phasic neuronal activation profile during memory periods. In contrast to mechanisms in which memories are directly encoded at stable attractors, these networks naturally forget stimuli over time. Despite this seeming functional disadvantage, they are more efficient in terms of how they leverage their attractor landscape and paradoxically, are considerably more robust to noise. Our results provide new dynamical hypotheses regarding how working memory function is encoded in both natural and artificial neural networks.