 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability-Based Token Replacement on LLM-Generated Text
Jun 04, 2025Generative models, especially large language models (LLMs), have shown remarkable progress in producing text that appears human-like. However, they often exhibit patterns that make their output easier to detect than text written by humans. In this paper, we investigate how explainable AI (XAI) methods can be used to reduce the detectability of AI-generated text (AIGT) while also introducing a robust ensemble-based detection approach. We begin by training an ensemble classifier to distinguish AIGT from human-written text, then apply SHAP and LIME to identify tokens that most strongly influence its predictions. We propose four explainability-based token replacement strategies to modify these influential tokens. Our findings show that these token replacement approaches can significantly diminish a single classifier's ability to detect AIGT. However, our ensemble classifier maintains strong performance across multiple languages and domains, showing that a multi-model approach can mitigate the impact of token-level manipulations. These results show that XAI methods can make AIGT harder to detect by focusing on the most influential tokens. At the same time, they highlight the need for robust, ensemble-based detection strategies that can adapt to evolving approaches for hiding AIGT.
Explainability in Practice: A Survey of Explainable NLP Across Various Domains
Feb 02, 2025



Natural Language Processing (NLP) has become a cornerstone in many critical sectors, including healthcare, finance, and customer relationship management. This is especially true with the development and use of advanced models such as GPT-based architectures and BERT, which are widely used in decision-making processes. However, the black-box nature of these advanced NLP models has created an urgent need for transparency and explainability. This review explores explainable NLP (XNLP) with a focus on its practical deployment and real-world applications, examining its implementation and the challenges faced in domain-specific contexts. The paper underscores the importance of explainability in NLP and provides a comprehensive perspective on how XNLP can be designed to meet the unique demands of various sectors, from healthcare's need for clear insights to finance's emphasis on fraud detection and risk assessment. Additionally, this review aims to bridge the knowledge gap in XNLP literature by offering a domain-specific exploration and discussing underrepresented areas such as real-world applicability, metric evaluation, and the role of human interaction in model assessment. The paper concludes by suggesting future research directions that could enhance the understanding and broader application of XNLP.
PATCH -- Psychometrics-AssisTed benCHmarking of Large Language Models: A Case Study of Mathematics Proficiency
Apr 02, 2024Many existing benchmarks of large (multimodal) language models (LLMs) focus on measuring LLMs' academic proficiency, often with also an interest in comparing model performance with human test takers. While these benchmarks have proven key to the development of LLMs, they suffer from several limitations, including questionable measurement quality (e.g., Do they measure what they are supposed to in a reliable way?), lack of quality assessment on the item level (e.g., Are some items more important or difficult than others?) and unclear human population reference (e.g., To whom can the model be compared?). In response to these challenges, we propose leveraging knowledge from psychometrics - a field dedicated to the measurement of latent variables like academic proficiency - into LLM benchmarking. We make three primary contributions. First, we introduce PATCH: a novel framework for Psychometrics-AssisTed benCHmarking of LLMs. PATCH addresses the aforementioned limitations, presenting a new direction for LLM benchmark research. Second, we implement PATCH by measuring GPT-4 and Gemini-Pro-Vision's proficiency in 8th grade mathematics against 56 human populations. We show that adopting a psychometrics-based approach yields evaluation outcomes that diverge from those based on existing benchmarking practices. Third, we release 4 datasets to support measuring and comparing LLM proficiency in grade school mathematics and science against human populations.
Designing and Evaluating General-Purpose User Representations Based on Behavioral Logs from a Measurement Process Perspective: A Case Study with Snapchat
Dec 19, 2023In human-computer interaction, understanding user behaviors and tailoring systems accordingly is pivotal. To this end, general-purpose user representation learning based on behavior logs is emerging as a powerful tool in user modeling, offering adaptability to various downstream tasks such as item recommendations and ad conversion prediction, without the need to fine-tune the upstream user model. While this methodology has shown promise in contexts like search engines and e-commerce platforms, its fit for instant messaging apps, a cornerstone of modern digital communication, remains largely uncharted. These apps, with their distinct interaction patterns, data structures, and user expectations, necessitate specialized attention. We explore this user modeling approach with Snapchat data as a case study. Furthermore, we introduce a novel design and evaluation framework rooted in the principles of the Measurement Process Framework from social science research methodology. Using this new framework, we design a Transformer-based user model that can produce high-quality general-purpose user representations for instant messaging platforms like Snapchat.
Multimodal Learning for Cardiovascular Risk Prediction using EHR Data
Aug 27, 2020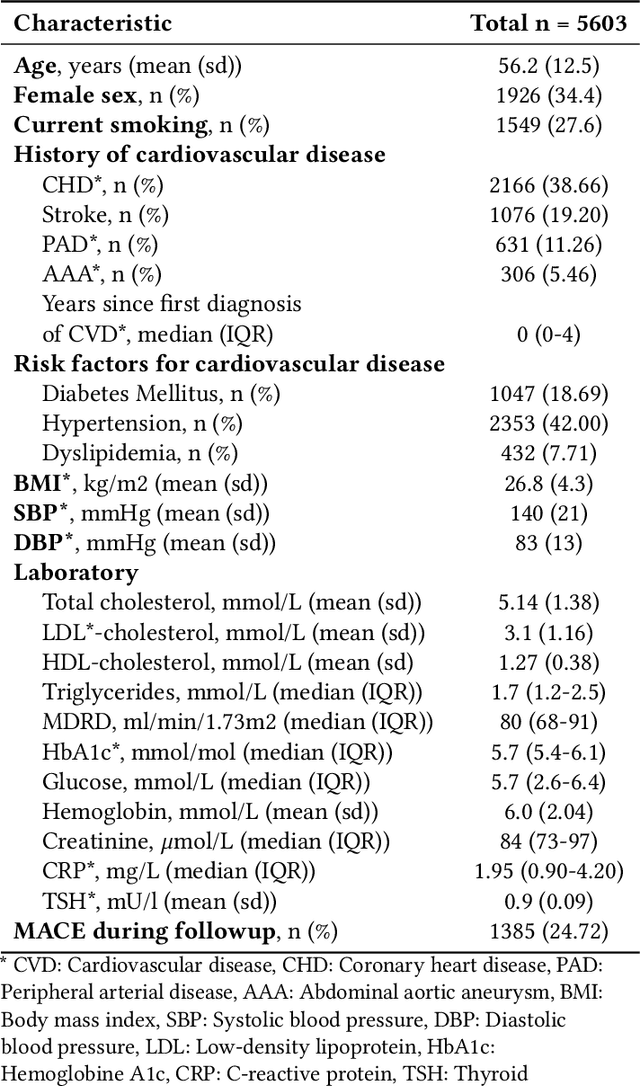
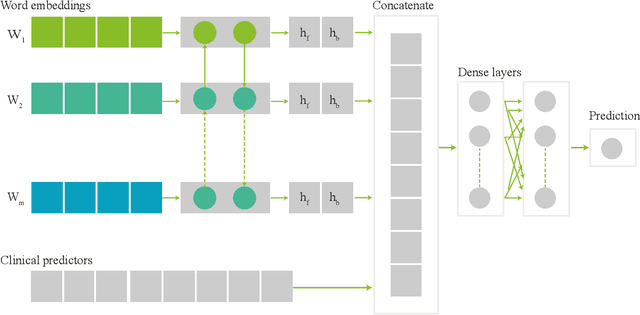
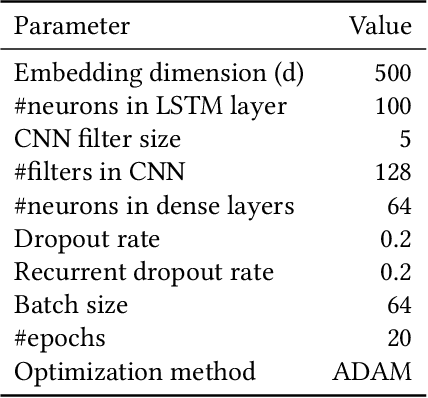
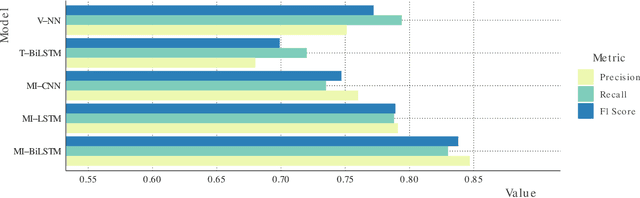
Electronic health records (EHRs) contain structured and unstructured data of significant clinical and research value. Various machine learning approaches have been developed to employ information in EHRs for risk prediction. The majority of these attempts, however, focus on structured EHR fields and lose the vast amount of information in the unstructured texts. To exploit the potential information captured in EHRs, in this study we propose a multimodal recurrent neural network model for cardiovascular risk prediction that integrates both medical texts and structured clinical information. The proposed multimodal bidirectional long short-term memory (BiLSTM) model concatenates word embeddings to classical clinical predictors before applying them to a final fully connected neural network. In the experiments, we compare performance of different deep neural network (DNN) architectures including convolutional neural network and long short-term memory in scenarios of using clinical variables and chest X-ray radiology reports. Evaluated on a data set of real world patients with manifest vascular disease or at high-risk for cardiovascular disease, the proposed BiLSTM model demonstrates state-of-the-art performance and outperforms other DNN baseline architectures.
The effect of measurement error on clustering algorithms
May 24, 2020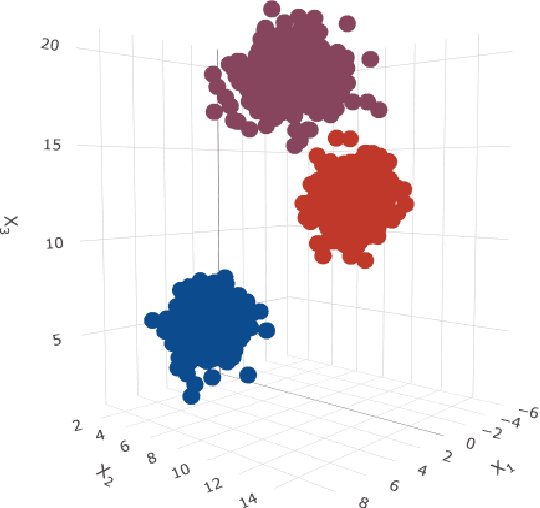
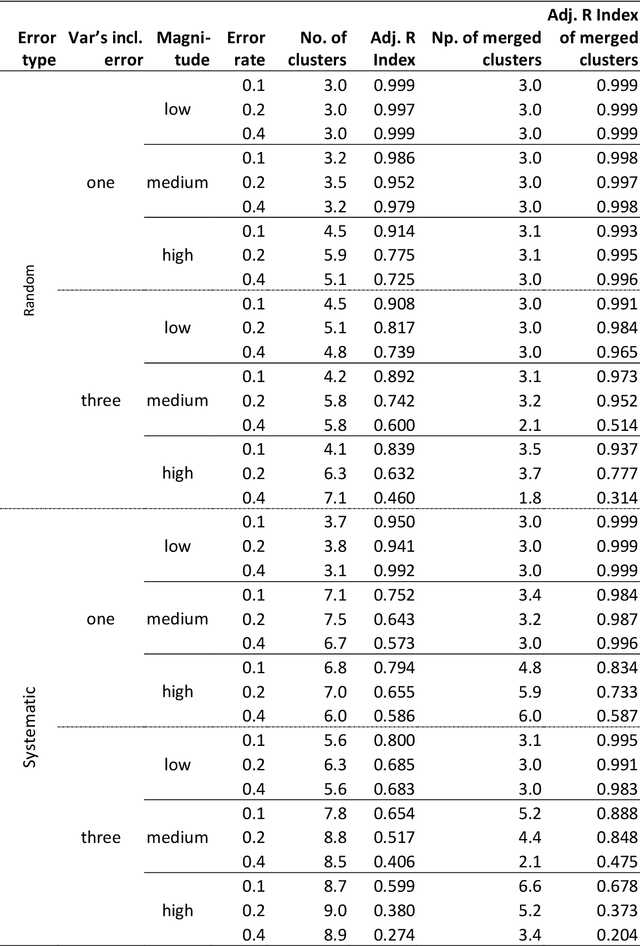
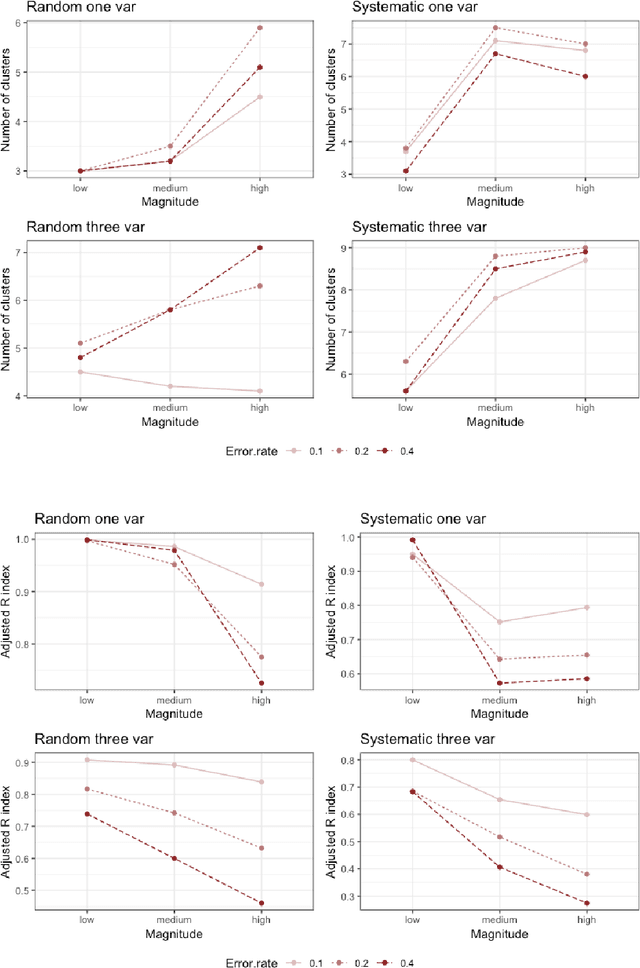

Clustering consists of a popular set of techniques used to separate data into interesting groups for further analysis. Many data sources on which clustering is performed are well-known to contain random and systematic measurement errors. Such errors may adversely affect clustering. While several techniques have been developed to deal with this problem, little is known about the effectiveness of these solutions. Moreover, no work to-date has examined the effect of systematic errors on clustering solutions. In this paper, we perform a Monte Carlo study to investigate the sensitivity of two common clustering algorithms, GMMs with merging and DBSCAN, to random and systematic error. We find that measurement error is particularly problematic when it is systematic and when it affects all variables in the dataset. For the conditions considered here, we also find that the partition-based GMM with merged components is less sensitive to measurement error than the density-based DBSCAN procedure.
Fair inference on error-prone outcomes
Mar 17, 2020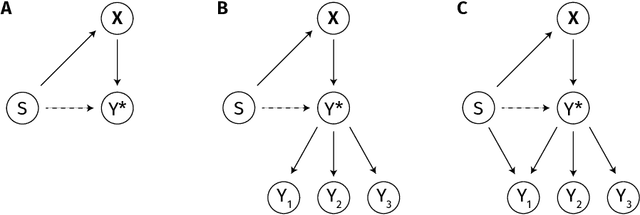
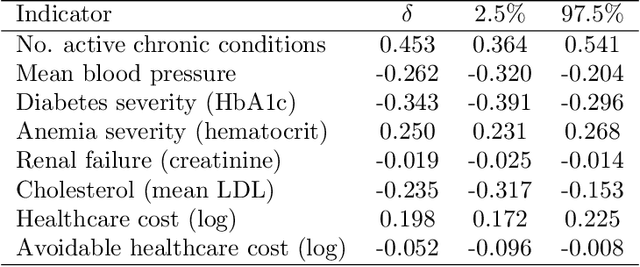
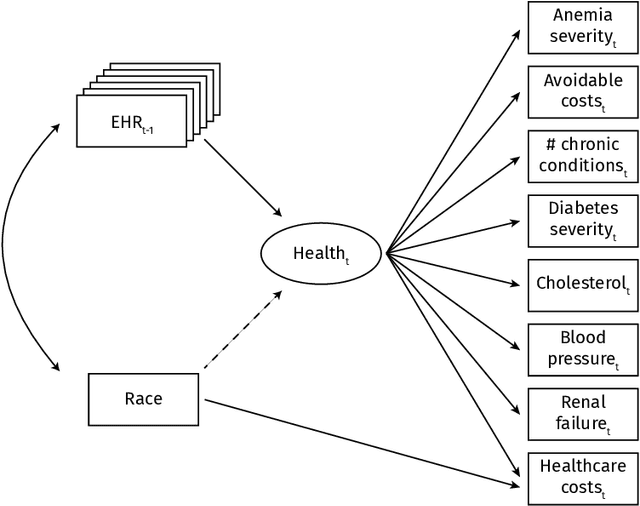
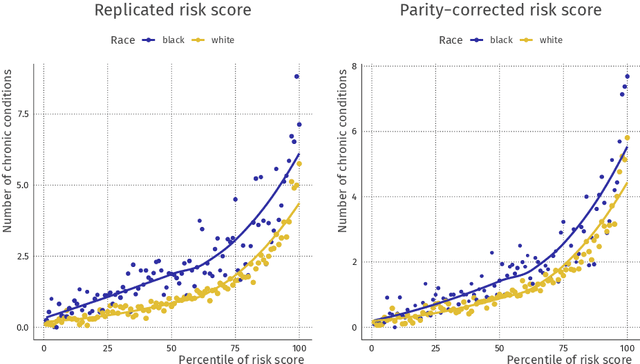
Fair inference in supervised learning is an important and active area of research, yielding a range of useful methods to assess and account for fairness criteria when predicting ground truth targets. As shown in recent work, however, when target labels are error-prone, potential prediction unfairness can arise from measurement error. In this paper, we show that, when an error-prone proxy target is used, existing methods to assess and calibrate fairness criteria do not extend to the true target variable of interest. To remedy this problem, we suggest a framework resulting from the combination of two existing literatures: fair ML methods, such as those found in the counterfactual fairness literature on the one hand, and, on the other, measurement models found in the statistical literature. We discuss these approaches and their connection resulting in our framework. In a healthcare decision problem, we find that using a latent variable model to account for measurement error removes the unfairness detected previously.
Privacy-Preserving Generalized Linear Models using Distributed Block Coordinate Descent
Nov 08, 2019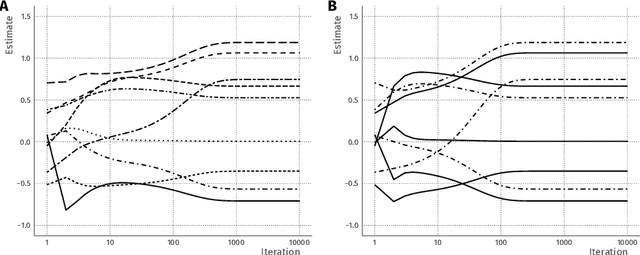

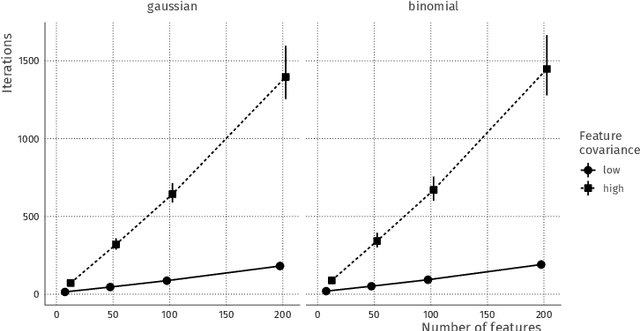
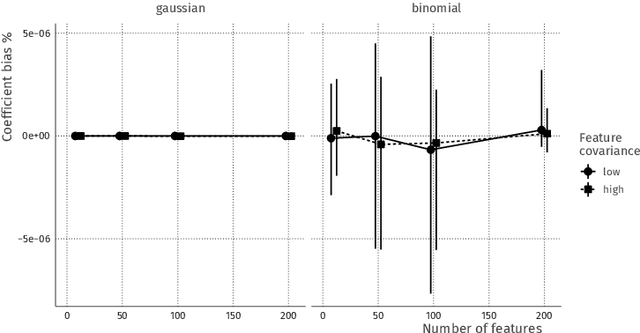
Combining data from varied sources has considerable potential for knowledge discovery: collaborating data parties can mine data in an expanded feature space, allowing them to explore a larger range of scientific questions. However, data sharing among different parties is highly restricted by legal conditions, ethical concerns, and / or data volume. Fueled by these concerns, the fields of cryptography and distributed learning have made great progress towards privacy-preserving and distributed data mining. However, practical implementations have been hampered by the limited scope or computational complexity of these methods. In this paper, we greatly extend the range of analyses available for vertically partitioned data, i.e., data collected by separate parties with different features on the same subjects. To this end, we present a novel approach for privacy-preserving generalized linear models, a fundamental and powerful framework underlying many prediction and classification procedures. We base our method on a distributed block coordinate descent algorithm to obtain parameter estimates, and we develop an extension to compute accurate standard errors without additional communication cost. We critically evaluate the information transfer for semi-honest collaborators and show that our protocol is secure against data reconstruction. Through both simulated and real-world examples we illustrate the functionality of our proposed algorithm. Without leaking information, our method performs as well on vertically partitioned data as existing methods on combined data -- all within mere minutes of computation time. We conclude that our method is a viable approach for vertically partitioned data analysis with a wide range of real-world applications.