 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA density ratio framework for evaluating the utility of synthetic data
Aug 23, 2024Synthetic data generation is a promising technique to facilitate the use of sensitive data while mitigating the risk of privacy breaches. However, for synthetic data to be useful in downstream analysis tasks, it needs to be of sufficient quality. Various methods have been proposed to measure the utility of synthetic data, but their results are often incomplete or even misleading. In this paper, we propose using density ratio estimation to improve quality evaluation for synthetic data, and thereby the quality of synthesized datasets. We show how this framework relates to and builds on existing measures, yielding global and local utility measures that are informative and easy to interpret. We develop an estimator which requires little to no manual tuning due to automatic selection of a nonparametric density ratio model. Through simulations, we find that density ratio estimation yields more accurate estimates of global utility than established procedures. A real-world data application demonstrates how the density ratio can guide refinements of synthesis models and can be used to improve downstream analyses. We conclude that density ratio estimation is a valuable tool in synthetic data generation workflows and provide these methods in the accessible open source R-package densityratio.
On Text-based Personality Computing: Challenges and Future Directions
Dec 14, 2022Text-based personality computing (TPC) has gained many research interests in NLP. In this paper, we describe 15 challenges that we consider deserving the attention of the research community. These challenges are organized by the following topics: personality taxonomies, measurement quality, datasets, performance evaluation, modelling choices, as well as ethics and fairness. When addressing each challenge, not only do we combine perspectives from both NLP and social sciences, but also offer concrete suggestions towards more valid and reliable TPC research.
Fair inference on error-prone outcomes
Mar 17, 2020
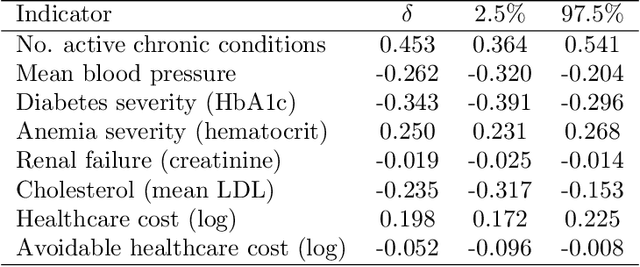
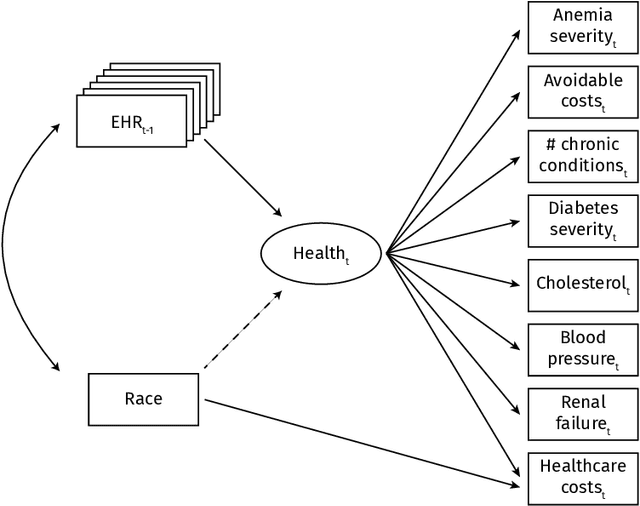
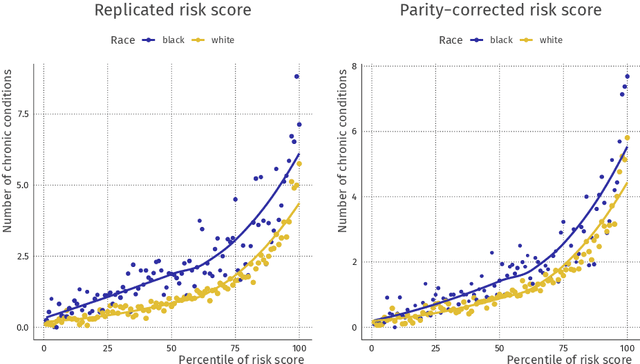
Fair inference in supervised learning is an important and active area of research, yielding a range of useful methods to assess and account for fairness criteria when predicting ground truth targets. As shown in recent work, however, when target labels are error-prone, potential prediction unfairness can arise from measurement error. In this paper, we show that, when an error-prone proxy target is used, existing methods to assess and calibrate fairness criteria do not extend to the true target variable of interest. To remedy this problem, we suggest a framework resulting from the combination of two existing literatures: fair ML methods, such as those found in the counterfactual fairness literature on the one hand, and, on the other, measurement models found in the statistical literature. We discuss these approaches and their connection resulting in our framework. In a healthcare decision problem, we find that using a latent variable model to account for measurement error removes the unfairness detected previously.
Privacy-Preserving Generalized Linear Models using Distributed Block Coordinate Descent
Nov 08, 2019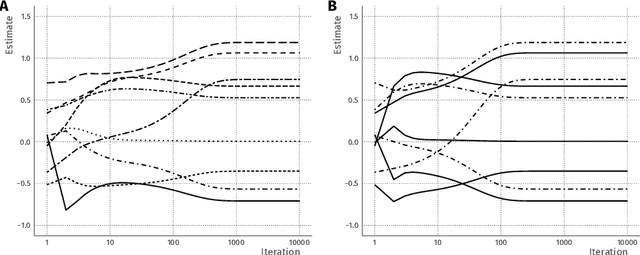

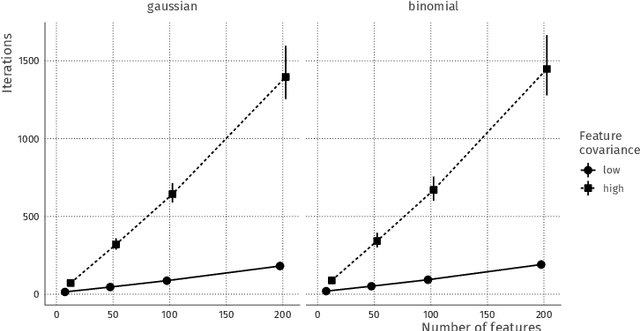
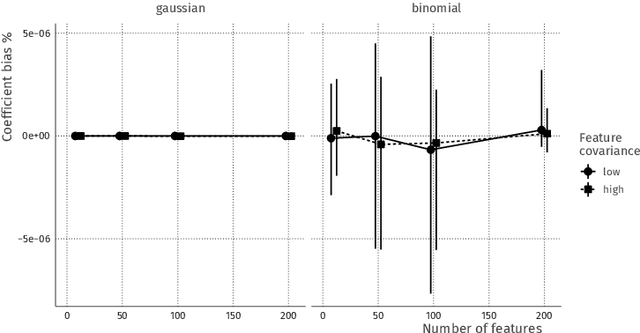
Combining data from varied sources has considerable potential for knowledge discovery: collaborating data parties can mine data in an expanded feature space, allowing them to explore a larger range of scientific questions. However, data sharing among different parties is highly restricted by legal conditions, ethical concerns, and / or data volume. Fueled by these concerns, the fields of cryptography and distributed learning have made great progress towards privacy-preserving and distributed data mining. However, practical implementations have been hampered by the limited scope or computational complexity of these methods. In this paper, we greatly extend the range of analyses available for vertically partitioned data, i.e., data collected by separate parties with different features on the same subjects. To this end, we present a novel approach for privacy-preserving generalized linear models, a fundamental and powerful framework underlying many prediction and classification procedures. We base our method on a distributed block coordinate descent algorithm to obtain parameter estimates, and we develop an extension to compute accurate standard errors without additional communication cost. We critically evaluate the information transfer for semi-honest collaborators and show that our protocol is secure against data reconstruction. Through both simulated and real-world examples we illustrate the functionality of our proposed algorithm. Without leaking information, our method performs as well on vertically partitioned data as existing methods on combined data -- all within mere minutes of computation time. We conclude that our method is a viable approach for vertically partitioned data analysis with a wide range of real-world applications.