 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Bayesian Network Ensembles
Feb 19, 2024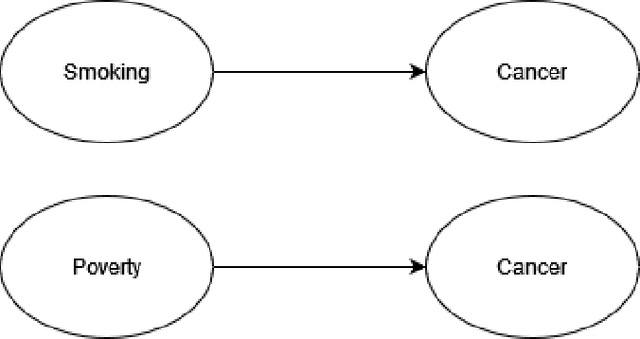
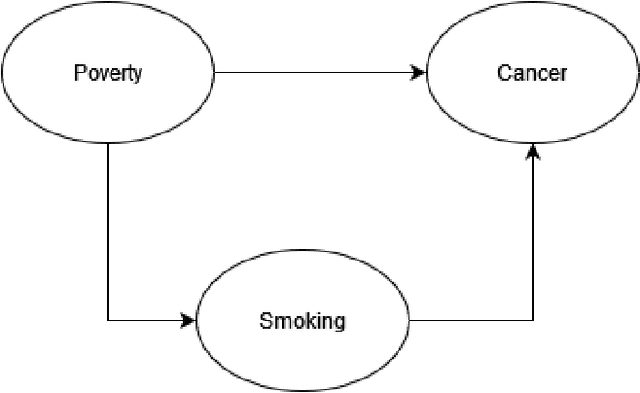
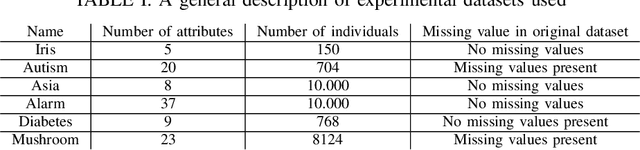
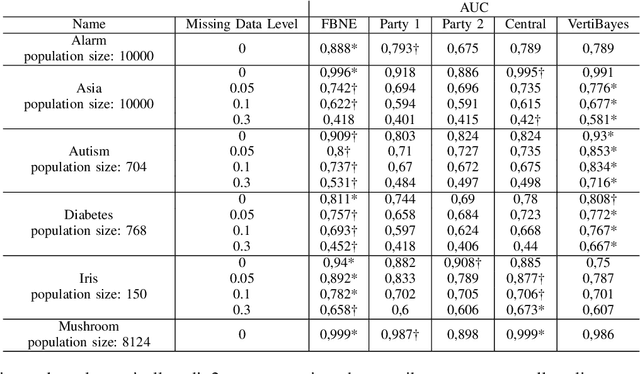
Federated learning allows us to run machine learning algorithms on decentralized data when data sharing is not permitted due to privacy concerns. Ensemble-based learning works by training multiple (weak) classifiers whose output is aggregated. Federated ensembles are ensembles applied to a federated setting, where each classifier in the ensemble is trained on one data location. In this article, we explore the use of federated ensembles of Bayesian networks (FBNE) in a range of experiments and compare their performance with locally trained models and models trained with VertiBayes, a federated learning algorithm to train Bayesian networks from decentralized data. Our results show that FBNE outperforms local models and provides a significant increase in training speed compared with VertiBayes while maintaining a similar performance in most settings, among other advantages. We show that FBNE is a potentially useful tool within the federated learning toolbox, especially when local populations are heavily biased, or there is a strong imbalance in population size across parties. We discuss the advantages and disadvantages of this approach in terms of time complexity, model accuracy, privacy protection, and model interpretability.
VertiBayes: Learning Bayesian network parameters from vertically partitioned data with missing values
Oct 31, 2022Federated learning makes it possible to train a machine learning model on decentralized data. Bayesian networks are probabilistic graphical models that have been widely used in artificial intelligence applications. Their popularity stems from the fact they can be built by combining existing expert knowledge with data and are highly interpretable, which makes them useful for decision support, e.g. in healthcare. While some research has been published on the federated learning of Bayesian networks, publications on Bayesian networks in a vertically partitioned or heterogeneous data setting (where different variables are located in different datasets) are limited, and suffer from important omissions, such as the handling of missing data. In this article, we propose a novel method called VertiBayes to train Bayesian networks (structure and parameters) on vertically partitioned data, which can handle missing values as well as an arbitrary number of parties. For structure learning we adapted the widely used K2 algorithm with a privacy-preserving scalar product protocol. For parameter learning, we use a two-step approach: first, we learn an intermediate model using maximum likelihood by treating missing values as a special value and then we train a model on synthetic data generated by the intermediate model using the EM algorithm. The privacy guarantees of our approach are equivalent to the ones provided by the privacy preserving scalar product protocol used. We experimentally show our approach produces models comparable to those learnt using traditional algorithms and we estimate the increase in complexity in terms of samples, network size, and complexity. Finally, we propose two alternative approaches to estimate the performance of the model using vertically partitioned data and we show in experiments that they lead to reasonably accurate estimates.
Privacy preserving n-party scalar product protocol
Dec 17, 2021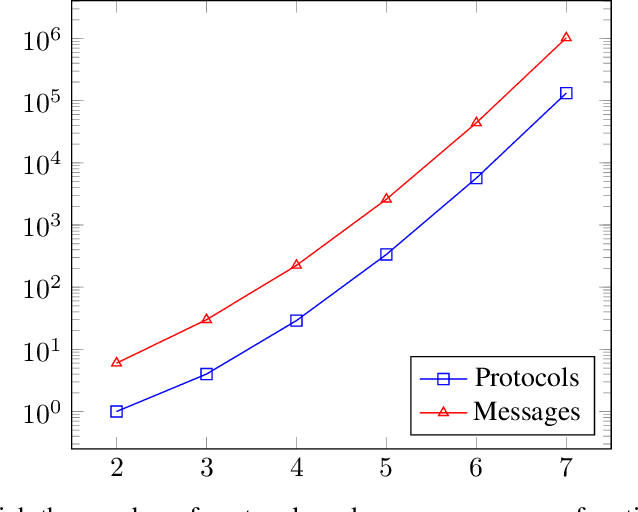
Privacy-preserving machine learning enables the training of models on decentralized datasets without the need to reveal the data, both on horizontal and vertically partitioned data. However, it relies on specialized techniques and algorithms to perform the necessary computations. The privacy preserving scalar product protocol, which enables the dot product of vectors without revealing them, is one popular example for its versatility. Unfortunately, the solutions currently proposed in the literature focus mainly on two-party scenarios, even though scenarios with a higher number of data parties are becoming more relevant. For example when performing analyses that require counting the number of samples which fulfill certain criteria defined across various sites, such as calculating the information gain at a node in a decision tree. In this paper we propose a generalization of the protocol for an arbitrary number of parties, based on an existing two-party method. Our proposed solution relies on a recursive resolution of smaller scalar products. After describing our proposed method, we discuss potential scalability issues. Finally, we describe the privacy guarantees and identify any concerns, as well as comparing the proposed method to the original solution in this aspect.
Privacy-Preserving Generalized Linear Models using Distributed Block Coordinate Descent
Nov 08, 2019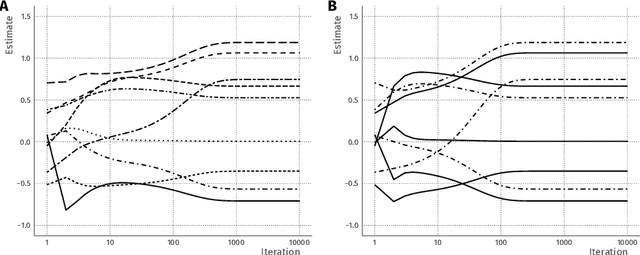

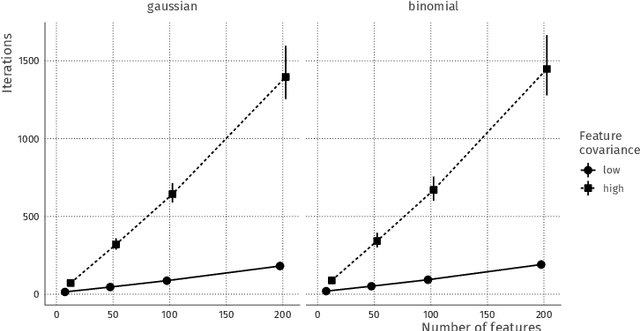
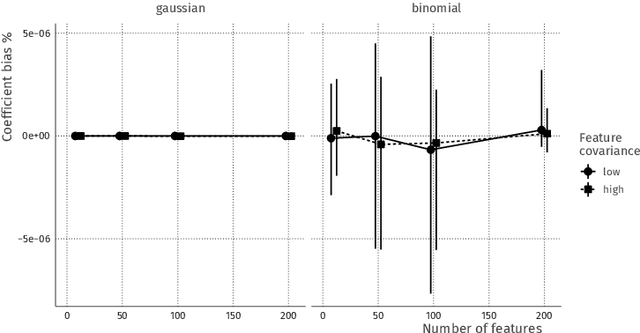
Combining data from varied sources has considerable potential for knowledge discovery: collaborating data parties can mine data in an expanded feature space, allowing them to explore a larger range of scientific questions. However, data sharing among different parties is highly restricted by legal conditions, ethical concerns, and / or data volume. Fueled by these concerns, the fields of cryptography and distributed learning have made great progress towards privacy-preserving and distributed data mining. However, practical implementations have been hampered by the limited scope or computational complexity of these methods. In this paper, we greatly extend the range of analyses available for vertically partitioned data, i.e., data collected by separate parties with different features on the same subjects. To this end, we present a novel approach for privacy-preserving generalized linear models, a fundamental and powerful framework underlying many prediction and classification procedures. We base our method on a distributed block coordinate descent algorithm to obtain parameter estimates, and we develop an extension to compute accurate standard errors without additional communication cost. We critically evaluate the information transfer for semi-honest collaborators and show that our protocol is secure against data reconstruction. Through both simulated and real-world examples we illustrate the functionality of our proposed algorithm. Without leaking information, our method performs as well on vertically partitioned data as existing methods on combined data -- all within mere minutes of computation time. We conclude that our method is a viable approach for vertically partitioned data analysis with a wide range of real-world applications.