 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair inference on error-prone outcomes
Paper and Code
Mar 17, 2020
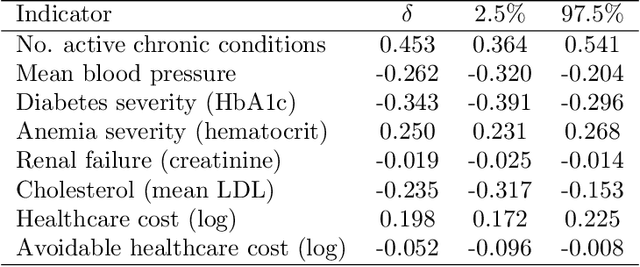
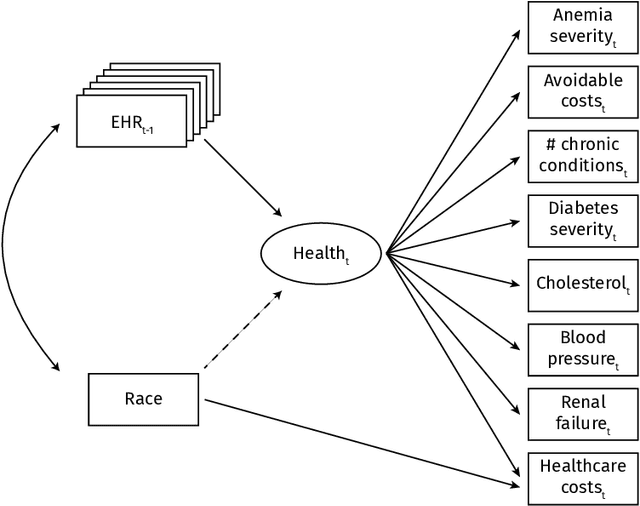
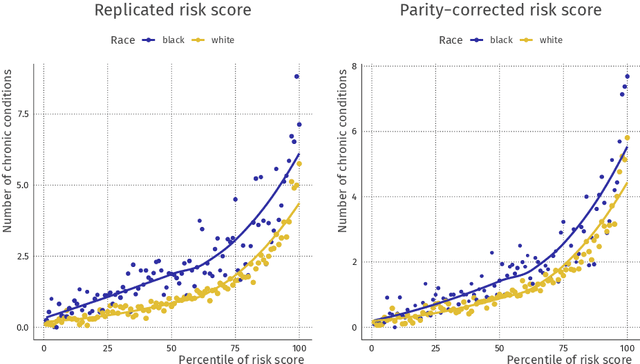
Fair inference in supervised learning is an important and active area of research, yielding a range of useful methods to assess and account for fairness criteria when predicting ground truth targets. As shown in recent work, however, when target labels are error-prone, potential prediction unfairness can arise from measurement error. In this paper, we show that, when an error-prone proxy target is used, existing methods to assess and calibrate fairness criteria do not extend to the true target variable of interest. To remedy this problem, we suggest a framework resulting from the combination of two existing literatures: fair ML methods, such as those found in the counterfactual fairness literature on the one hand, and, on the other, measurement models found in the statistical literature. We discuss these approaches and their connection resulting in our framework. In a healthcare decision problem, we find that using a latent variable model to account for measurement error removes the unfairness detected previously.