 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Reliability of LLMs Annotations in the Context of Demographic Bias and Model Explanation
Jul 17, 2025
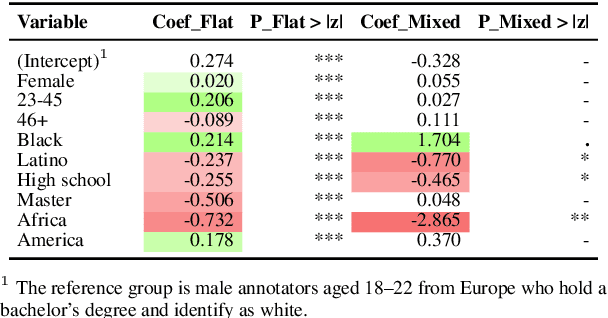
Understanding the sources of variability in annotations is crucial for developing fair NLP systems, especially for tasks like sexism detection where demographic bias is a concern. This study investigates the extent to which annotator demographic features influence labeling decisions compared to text content. Using a Generalized Linear Mixed Model, we quantify this inf luence, finding that while statistically present, demographic factors account for a minor fraction ( 8%) of the observed variance, with tweet content being the dominant factor. We then assess the reliability of Generative AI (GenAI) models as annotators, specifically evaluating if guiding them with demographic personas improves alignment with human judgments. Our results indicate that simplistic persona prompting often fails to enhance, and sometimes degrades, performance compared to baseline models. Furthermore, explainable AI (XAI) techniques reveal that model predictions rely heavily on content-specific tokens related to sexism, rather than correlates of demographic characteristics. We argue that focusing on content-driven explanations and robust annotation protocols offers a more reliable path towards fairness than potentially persona simulation.
Exploring Cultural Variations in Moral Judgments with Large Language Models
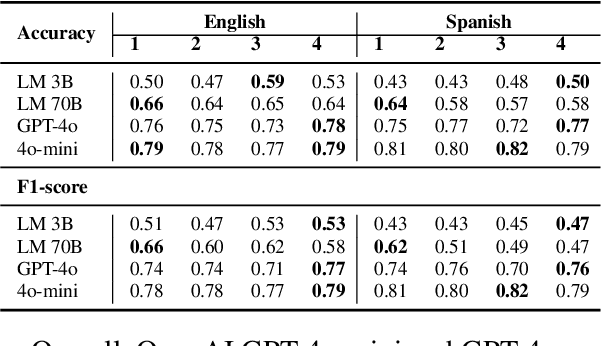
Jun 14, 2025Large Language Models (LLMs) have shown strong performance across many tasks, but their ability to capture culturally diverse moral values remains unclear. In this paper, we examine whether LLMs can mirror variations in moral attitudes reported by two major cross-cultural surveys: the World Values Survey and the PEW Research Center's Global Attitudes Survey. We compare smaller, monolingual, and multilingual models (GPT-2, OPT, BLOOMZ, and Qwen) with more recent instruction-tuned models (GPT-4o, GPT-4o-mini, Gemma-2-9b-it, and Llama-3.3-70B-Instruct). Using log-probability-based moral justifiability scores, we correlate each model's outputs with survey data covering a broad set of ethical topics. Our results show that many earlier or smaller models often produce near-zero or negative correlations with human judgments. In contrast, advanced instruction-tuned models (including GPT-4o and GPT-4o-mini) achieve substantially higher positive correlations, suggesting they better reflect real-world moral attitudes. While scaling up model size and using instruction tuning can improve alignment with cross-cultural moral norms, challenges remain for certain topics and regions. We discuss these findings in relation to bias analysis, training data diversity, and strategies for improving the cultural sensitivity of LLMs.
Explainability-Based Token Replacement on LLM-Generated Text
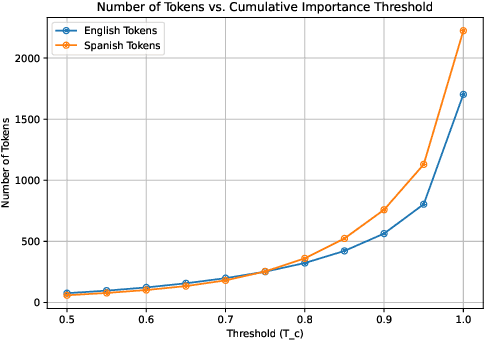
Jun 04, 2025Generative models, especially large language models (LLMs), have shown remarkable progress in producing text that appears human-like. However, they often exhibit patterns that make their output easier to detect than text written by humans. In this paper, we investigate how explainable AI (XAI) methods can be used to reduce the detectability of AI-generated text (AIGT) while also introducing a robust ensemble-based detection approach. We begin by training an ensemble classifier to distinguish AIGT from human-written text, then apply SHAP and LIME to identify tokens that most strongly influence its predictions. We propose four explainability-based token replacement strategies to modify these influential tokens. Our findings show that these token replacement approaches can significantly diminish a single classifier's ability to detect AIGT. However, our ensemble classifier maintains strong performance across multiple languages and domains, showing that a multi-model approach can mitigate the impact of token-level manipulations. These results show that XAI methods can make AIGT harder to detect by focusing on the most influential tokens. At the same time, they highlight the need for robust, ensemble-based detection strategies that can adapt to evolving approaches for hiding AIGT.
Explainability in Practice: A Survey of Explainable NLP Across Various Domains
Feb 02, 2025



Natural Language Processing (NLP) has become a cornerstone in many critical sectors, including healthcare, finance, and customer relationship management. This is especially true with the development and use of advanced models such as GPT-based architectures and BERT, which are widely used in decision-making processes. However, the black-box nature of these advanced NLP models has created an urgent need for transparency and explainability. This review explores explainable NLP (XNLP) with a focus on its practical deployment and real-world applications, examining its implementation and the challenges faced in domain-specific contexts. The paper underscores the importance of explainability in NLP and provides a comprehensive perspective on how XNLP can be designed to meet the unique demands of various sectors, from healthcare's need for clear insights to finance's emphasis on fraud detection and risk assessment. Additionally, this review aims to bridge the knowledge gap in XNLP literature by offering a domain-specific exploration and discussing underrepresented areas such as real-world applicability, metric evaluation, and the role of human interaction in model assessment. The paper concludes by suggesting future research directions that could enhance the understanding and broader application of XNLP.
LLMs as mirrors of societal moral standards: reflection of cultural divergence and agreement across ethical topics
Dec 01, 2024Large language models (LLMs) have become increasingly pivotal in various domains due the recent advancements in their performance capabilities. However, concerns persist regarding biases in LLMs, including gender, racial, and cultural biases derived from their training data. These biases raise critical questions about the ethical deployment and societal impact of LLMs. Acknowledging these concerns, this study investigates whether LLMs accurately reflect cross-cultural variations and similarities in moral perspectives. In assessing whether the chosen LLMs capture patterns of divergence and agreement on moral topics across cultures, three main methods are employed: (1) comparison of model-generated and survey-based moral score variances, (2) cluster alignment analysis to evaluate the correspondence between country clusters derived from model-generated moral scores and those derived from survey data, and (3) probing LLMs with direct comparative prompts. All three methods involve the use of systematic prompts and token pairs designed to assess how well LLMs understand and reflect cultural variations in moral attitudes. The findings of this study indicate overall variable and low performance in reflecting cross-cultural differences and similarities in moral values across the models tested, highlighting the necessity for improving models' accuracy in capturing these nuances effectively. The insights gained from this study aim to inform discussions on the ethical development and deployment of LLMs in global contexts, emphasizing the importance of mitigating biases and promoting fair representation across diverse cultural perspectives.
Large Language Models as Mirrors of Societal Moral Standards
Dec 01, 2024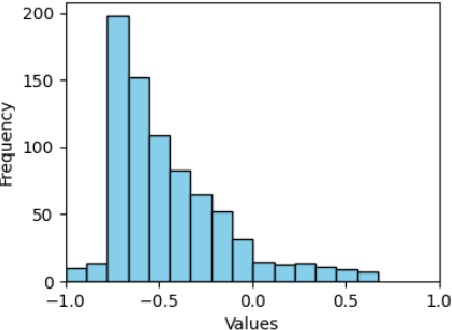
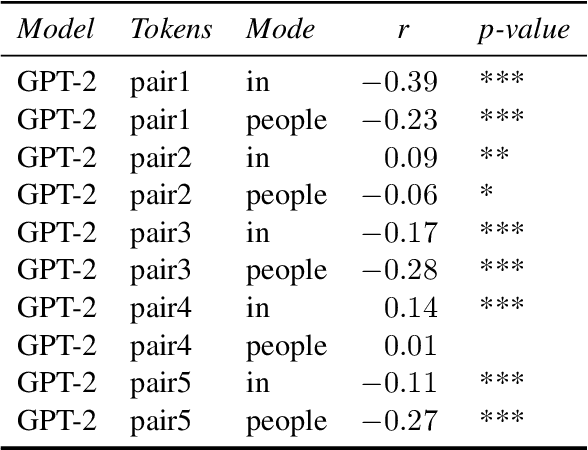
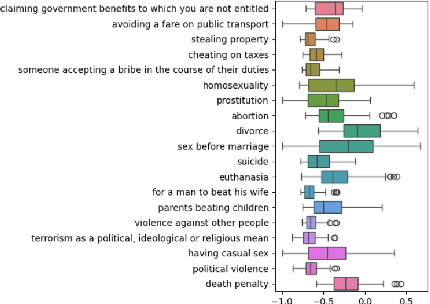
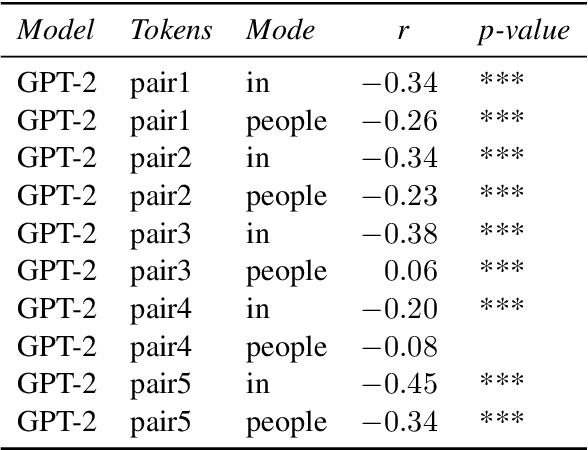
Prior research has demonstrated that language models can, to a limited extent, represent moral norms in a variety of cultural contexts. This research aims to replicate these findings and further explore their validity, concentrating on issues like 'homosexuality' and 'divorce'. This study evaluates the effectiveness of these models using information from two surveys, the WVS and the PEW, that encompass moral perspectives from over 40 countries. The results show that biases exist in both monolingual and multilingual models, and they typically fall short of accurately capturing the moral intricacies of diverse cultures. However, the BLOOM model shows the best performance, exhibiting some positive correlations, but still does not achieve a comprehensive moral understanding. This research underscores the limitations of current PLMs in processing cross-cultural differences in values and highlights the importance of developing culturally aware AI systems that better align with universal human values.
On Text-based Personality Computing: Challenges and Future Directions
Dec 14, 2022Text-based personality computing (TPC) has gained many research interests in NLP. In this paper, we describe 15 challenges that we consider deserving the attention of the research community. These challenges are organized by the following topics: personality taxonomies, measurement quality, datasets, performance evaluation, modelling choices, as well as ethics and fairness. When addressing each challenge, not only do we combine perspectives from both NLP and social sciences, but also offer concrete suggestions towards more valid and reliable TPC research.
Modelling Stance Detection as Textual Entailment Recognition and Leveraging Measurement Knowledge from Social Sciences
Dec 13, 2022
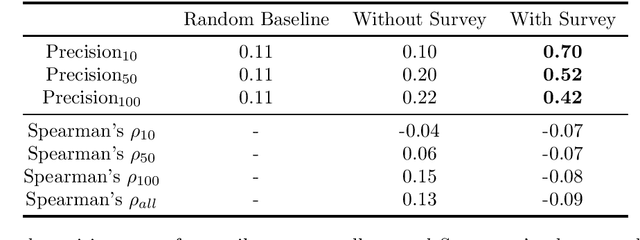
Stance detection (SD) can be considered a special case of textual entailment recognition (TER), a generic natural language task. Modelling SD as TER may offer benefits like more training data and a more general learning scheme. In this paper, we present an initial empirical analysis of this approach. We apply it to a difficult but relevant test case where no existing labelled SD dataset is available, because this is where modelling SD as TER may be especially helpful. We also leverage measurement knowledge from social sciences to improve model performance. We discuss our findings and suggest future research directions.
Neural Networks for Latent Budget Analysis of Compositional Data
Sep 10, 2021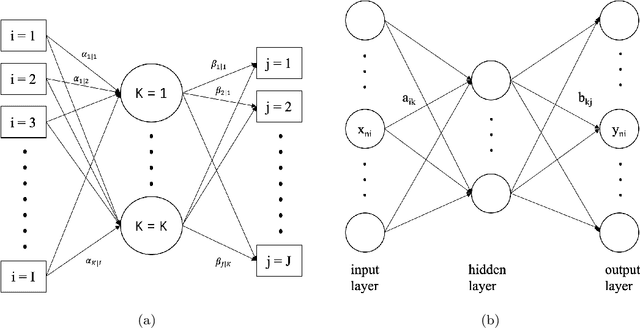
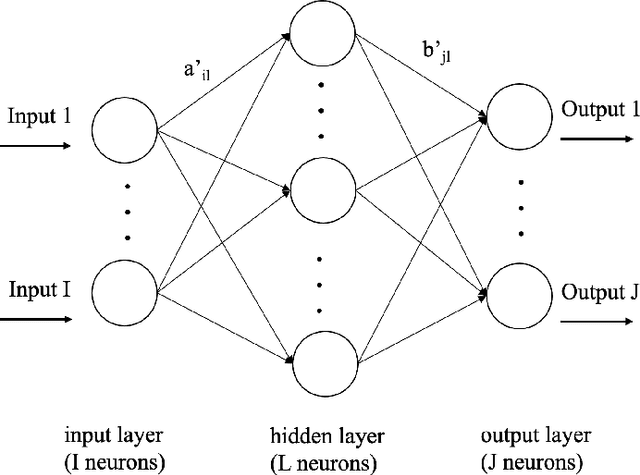
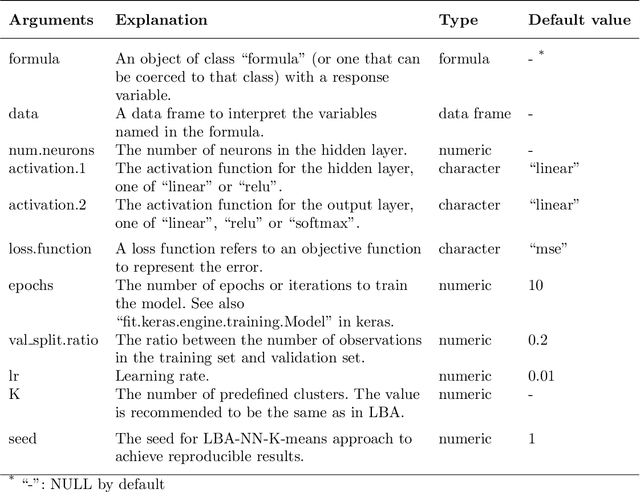
Compositional data are non-negative data collected in a rectangular matrix with a constant row sum. Due to the non-negativity the focus is on conditional proportions that add up to 1 for each row. A row of conditional proportions is called an observed budget. Latent budget analysis (LBA) assumes a mixture of latent budgets that explains the observed budgets. LBA is usually fitted to a contingency table, where the rows are levels of one or more explanatory variables and the columns the levels of a response variable. In prospective studies, there is only knowledge about the explanatory variables of individuals and interest goes out to predicting the response variable. Thus, a form of LBA is needed that has the functionality of prediction. Previous studies proposed a constrained neural network (NN) extension of LBA that was hampered by an unsatisfying prediction ability. Here we propose LBA-NN, a feed forward NN model that yields a similar interpretation to LBA but equips LBA with a better ability of prediction. A stable and plausible interpretation of LBA-NN is obtained through the use of importance plots and table, that show the relative importance of all explanatory variables on the response variable. An LBA-NN-K- means approach that applies K-means clustering on the importance table is used to produce K clusters that are comparable to K latent budgets in LBA. Here we provide different experiments where LBA-NN is implemented and compared with LBA. In our analysis, LBA-NN outperforms LBA in prediction in terms of accuracy, specificity, recall and mean square error. We provide open-source software at GitHub.
Multimodal Learning for Cardiovascular Risk Prediction using EHR Data
Aug 27, 2020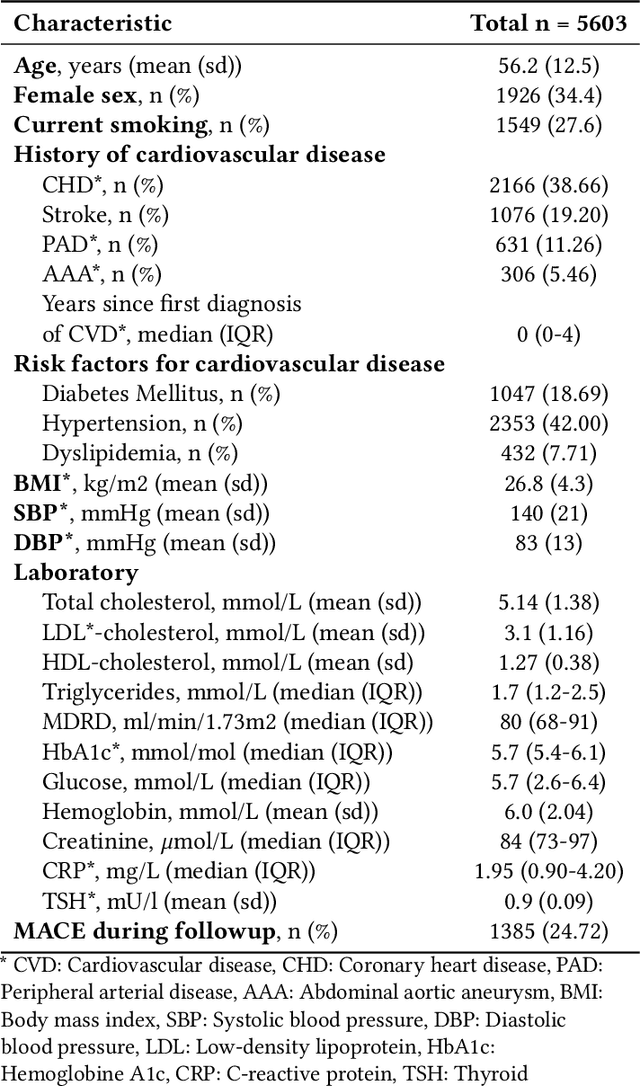
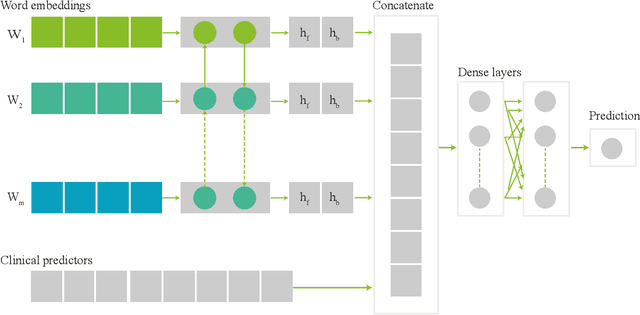
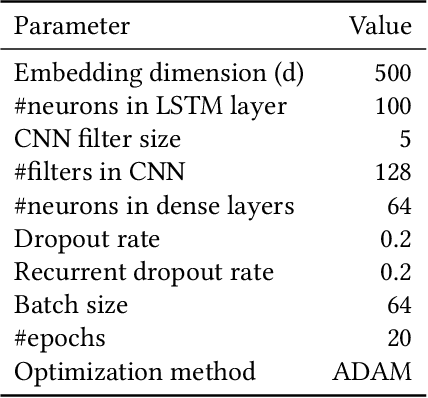
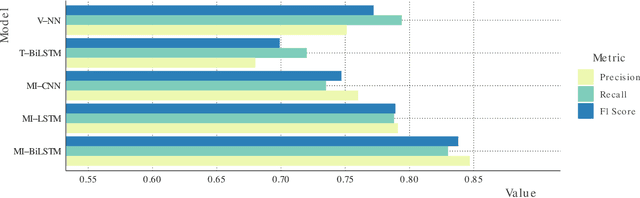
Electronic health records (EHRs) contain structured and unstructured data of significant clinical and research value. Various machine learning approaches have been developed to employ information in EHRs for risk prediction. The majority of these attempts, however, focus on structured EHR fields and lose the vast amount of information in the unstructured texts. To exploit the potential information captured in EHRs, in this study we propose a multimodal recurrent neural network model for cardiovascular risk prediction that integrates both medical texts and structured clinical information. The proposed multimodal bidirectional long short-term memory (BiLSTM) model concatenates word embeddings to classical clinical predictors before applying them to a final fully connected neural network. In the experiments, we compare performance of different deep neural network (DNN) architectures including convolutional neural network and long short-term memory in scenarios of using clinical variables and chest X-ray radiology reports. Evaluated on a data set of real world patients with manifest vascular disease or at high-risk for cardiovascular disease, the proposed BiLSTM model demonstrates state-of-the-art performance and outperforms other DNN baseline architectures.