 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining the Strengths of Dutch Survey and Register Data in a Data Challenge to Predict Fertility
Feb 01, 2024



The social sciences have produced an impressive body of research on determinants of fertility outcomes, or whether and when people have children. However, the strength of these determinants and underlying theories are rarely evaluated on their predictive ability on new data. This prevents us from systematically comparing studies, hindering the evaluation and accumulation of knowledge. In this paper, we present two datasets which can be used to study the predictability of fertility outcomes in the Netherlands. One dataset is based on the LISS panel, a longitudinal survey which includes thousands of variables on a wide range of topics, including individual preferences and values. The other is based on the Dutch register data which lacks attitudinal data but includes detailed information about the life courses of millions of Dutch residents. We provide information about the datasets and the samples, and describe the fertility outcome of interest. We also introduce the fertility prediction data challenge PreFer which is based on these datasets and will start in Spring 2024. We outline the ways in which measuring the predictability of fertility outcomes using these datasets and combining their strengths in the data challenge can advance our understanding of fertility behaviour and computational social science. We further provide details for participants on how to take part in the data challenge.
The effect of measurement error on clustering algorithms
May 24, 2020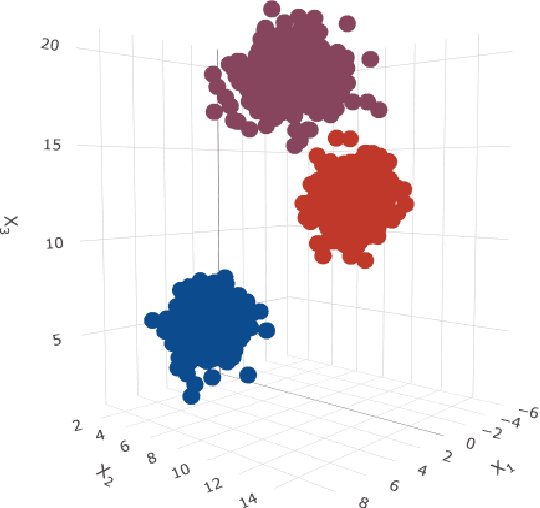
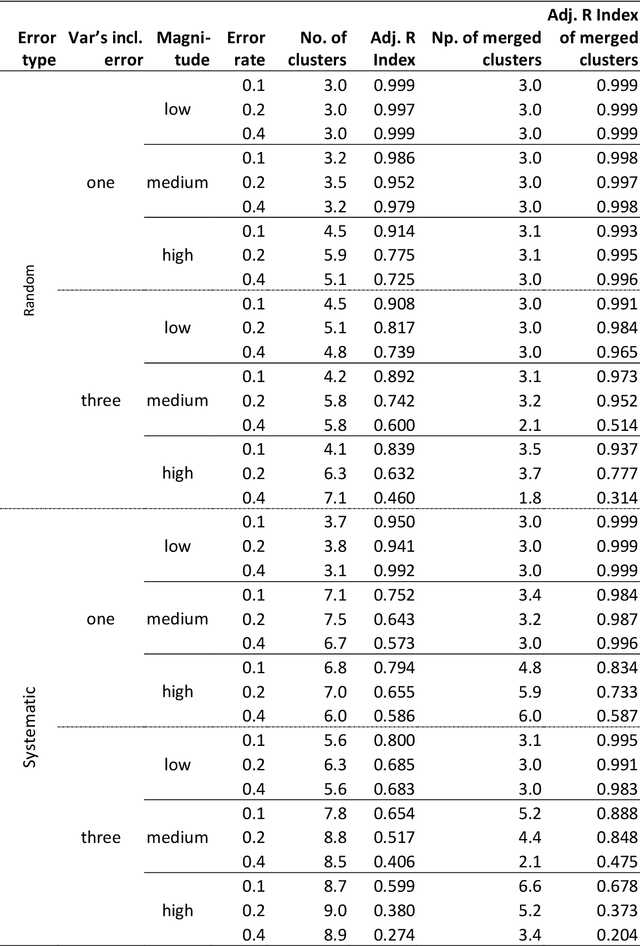
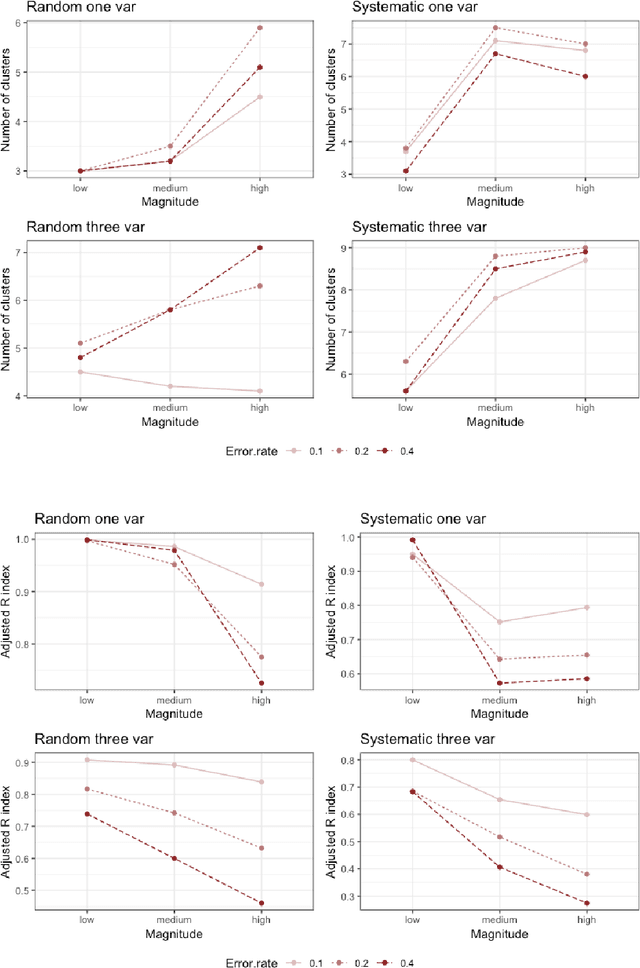

Clustering consists of a popular set of techniques used to separate data into interesting groups for further analysis. Many data sources on which clustering is performed are well-known to contain random and systematic measurement errors. Such errors may adversely affect clustering. While several techniques have been developed to deal with this problem, little is known about the effectiveness of these solutions. Moreover, no work to-date has examined the effect of systematic errors on clustering solutions. In this paper, we perform a Monte Carlo study to investigate the sensitivity of two common clustering algorithms, GMMs with merging and DBSCAN, to random and systematic error. We find that measurement error is particularly problematic when it is systematic and when it affects all variables in the dataset. For the conditions considered here, we also find that the partition-based GMM with merged components is less sensitive to measurement error than the density-based DBSCAN procedure.