 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Out-of-Vocabulary Handling in Recommendation Systems
Mar 27, 2024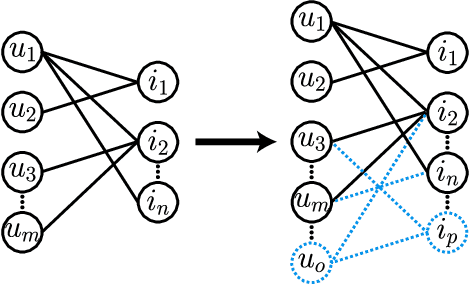


Recommendation systems (RS) are an increasingly relevant area for both academic and industry researchers, given their widespread impact on the daily online experiences of billions of users. One common issue in real RS is the cold-start problem, where users and items may not contain enough information to produce high-quality recommendations. This work focuses on a complementary problem: recommending new users and items unseen (out-of-vocabulary, or OOV) at training time. This setting is known as the inductive setting and is especially problematic for factorization-based models, which rely on encoding only those users/items seen at training time with fixed parameter vectors. Many existing solutions applied in practice are often naive, such as assigning OOV users/items to random buckets. In this work, we tackle this problem and propose approaches that better leverage available user/item features to improve OOV handling at the embedding table level. We discuss general-purpose plug-and-play approaches that are easily applicable to most RS models and improve inductive performance without negatively impacting transductive model performance. We extensively evaluate 9 OOV embedding methods on 5 models across 4 datasets (spanning different domains). One of these datasets is a proprietary production dataset from a prominent RS employed by a large social platform serving hundreds of millions of daily active users. In our experiments, we find that several proposed methods that exploit feature similarity using LSH consistently outperform alternatives on most model-dataset combinations, with the best method showing a mean improvement of 3.74% over the industry standard baseline in inductive performance. We release our code and hope our work helps practitioners make more informed decisions when handling OOV for their RS and further inspires academic research into improving OOV support in RS.
GPT-generated Text Detection: Benchmark Dataset and Tensor-based Detection Method
Mar 12, 2024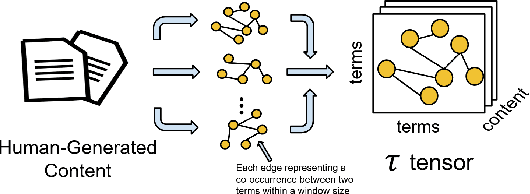
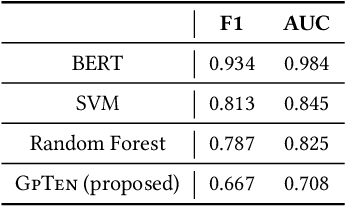
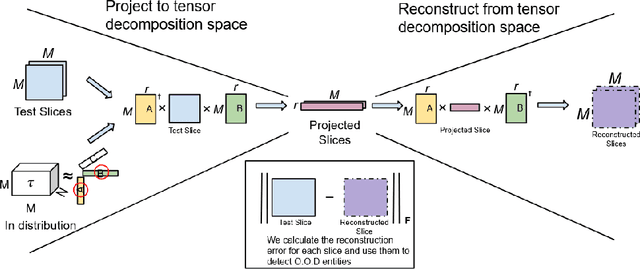
As natural language models like ChatGPT become increasingly prevalent in applications and services, the need for robust and accurate methods to detect their output is of paramount importance. In this paper, we present GPT Reddit Dataset (GRiD), a novel Generative Pretrained Transformer (GPT)-generated text detection dataset designed to assess the performance of detection models in identifying generated responses from ChatGPT. The dataset consists of a diverse collection of context-prompt pairs based on Reddit, with human-generated and ChatGPT-generated responses. We provide an analysis of the dataset's characteristics, including linguistic diversity, context complexity, and response quality. To showcase the dataset's utility, we benchmark several detection methods on it, demonstrating their efficacy in distinguishing between human and ChatGPT-generated responses. This dataset serves as a resource for evaluating and advancing detection techniques in the context of ChatGPT and contributes to the ongoing efforts to ensure responsible and trustworthy AI-driven communication on the internet. Finally, we propose GpTen, a novel tensor-based GPT text detection method that is semi-supervised in nature since it only has access to human-generated text and performs on par with fully-supervised baselines.
Node Duplication Improves Cold-start Link Prediction
Feb 15, 2024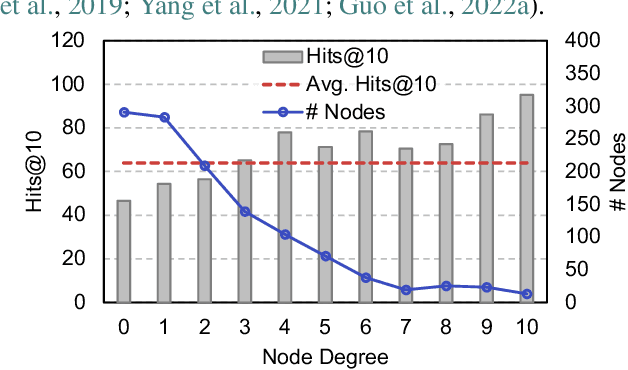
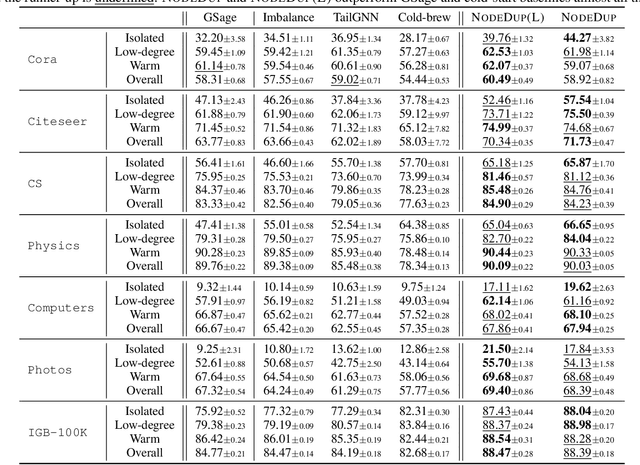
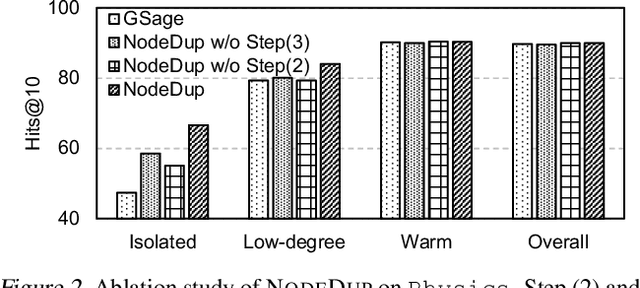
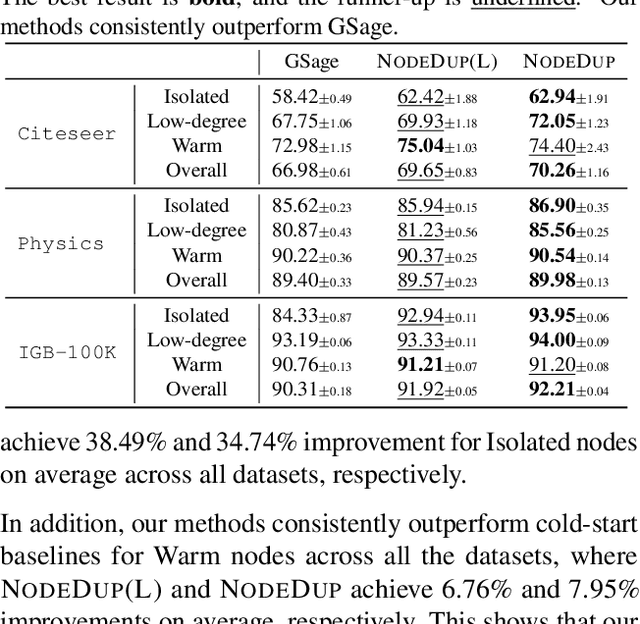
Graph Neural Networks (GNNs) are prominent in graph machine learning and have shown state-of-the-art performance in Link Prediction (LP) tasks. Nonetheless, recent studies show that GNNs struggle to produce good results on low-degree nodes despite their overall strong performance. In practical applications of LP, like recommendation systems, improving performance on low-degree nodes is critical, as it amounts to tackling the cold-start problem of improving the experiences of users with few observed interactions. In this paper, we investigate improving GNNs' LP performance on low-degree nodes while preserving their performance on high-degree nodes and propose a simple yet surprisingly effective augmentation technique called NodeDup. Specifically, NodeDup duplicates low-degree nodes and creates links between nodes and their own duplicates before following the standard supervised LP training scheme. By leveraging a ''multi-view'' perspective for low-degree nodes, NodeDup shows significant LP performance improvements on low-degree nodes without compromising any performance on high-degree nodes. Additionally, as a plug-and-play augmentation module, NodeDup can be easily applied to existing GNNs with very light computational cost. Extensive experiments show that NodeDup achieves 38.49%, 13.34%, and 6.76% improvements on isolated, low-degree, and warm nodes, respectively, on average across all datasets compared to GNNs and state-of-the-art cold-start methods.
CARL-G: Clustering-Accelerated Representation Learning on Graphs
Jun 12, 2023
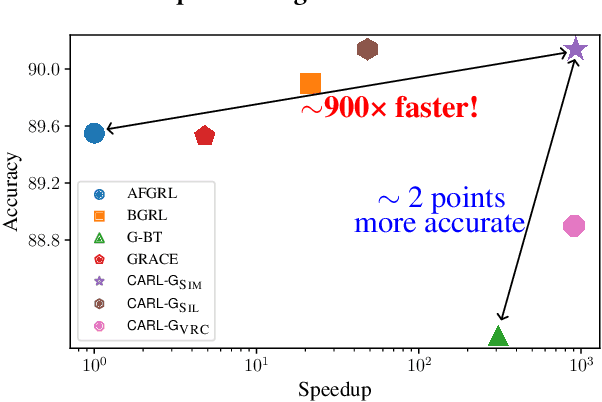
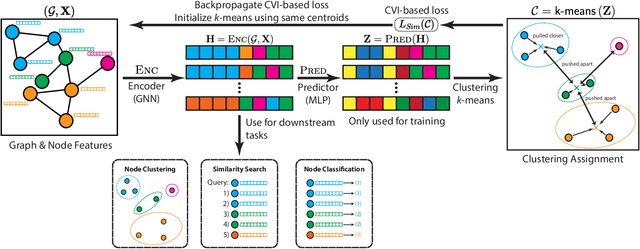
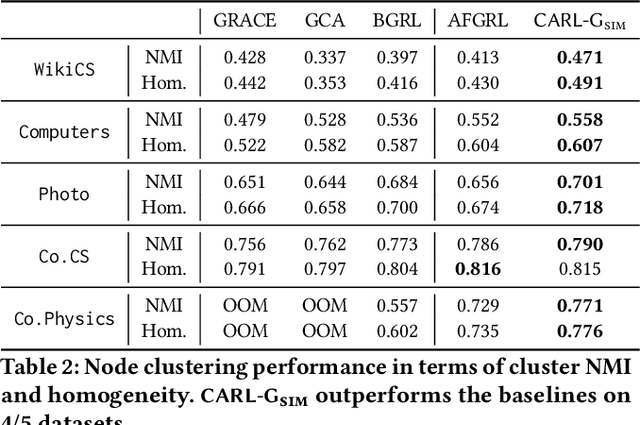
Self-supervised learning on graphs has made large strides in achieving great performance in various downstream tasks. However, many state-of-the-art methods suffer from a number of impediments, which prevent them from realizing their full potential. For instance, contrastive methods typically require negative sampling, which is often computationally costly. While non-contrastive methods avoid this expensive step, most existing methods either rely on overly complex architectures or dataset-specific augmentations. In this paper, we ask: Can we borrow from classical unsupervised machine learning literature in order to overcome those obstacles? Guided by our key insight that the goal of distance-based clustering closely resembles that of contrastive learning: both attempt to pull representations of similar items together and dissimilar items apart. As a result, we propose CARL-G - a novel clustering-based framework for graph representation learning that uses a loss inspired by Cluster Validation Indices (CVIs), i.e., internal measures of cluster quality (no ground truth required). CARL-G is adaptable to different clustering methods and CVIs, and we show that with the right choice of clustering method and CVI, CARL-G outperforms node classification baselines on 4/5 datasets with up to a 79x training speedup compared to the best-performing baseline. CARL-G also performs at par or better than baselines in node clustering and similarity search tasks, training up to 1,500x faster than the best-performing baseline. Finally, we also provide theoretical foundations for the use of CVI-inspired losses in graph representation learning.
Link Prediction with Non-Contrastive Learning
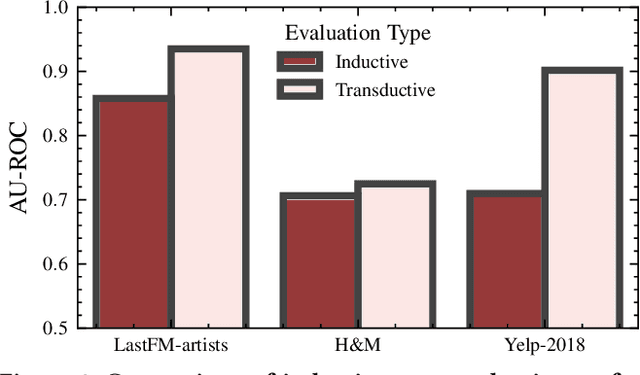
Nov 25, 2022A recent focal area in the space of graph neural networks (GNNs) is graph self-supervised learning (SSL), which aims to derive useful node representations without labeled data. Notably, many state-of-the-art graph SSL methods are contrastive methods, which use a combination of positive and negative samples to learn node representations. Owing to challenges in negative sampling (slowness and model sensitivity), recent literature introduced non-contrastive methods, which instead only use positive samples. Though such methods have shown promising performance in node-level tasks, their suitability for link prediction tasks, which are concerned with predicting link existence between pairs of nodes (and have broad applicability to recommendation systems contexts) is yet unexplored. In this work, we extensively evaluate the performance of existing non-contrastive methods for link prediction in both transductive and inductive settings. While most existing non-contrastive methods perform poorly overall, we find that, surprisingly, BGRL generally performs well in transductive settings. However, it performs poorly in the more realistic inductive settings where the model has to generalize to links to/from unseen nodes. We find that non-contrastive models tend to overfit to the training graph and use this analysis to propose T-BGRL, a novel non-contrastive framework that incorporates cheap corruptions to improve the generalization ability of the model. This simple modification strongly improves inductive performance in 5/6 of our datasets, with up to a 120% improvement in Hits@50--all with comparable speed to other non-contrastive baselines and up to 14x faster than the best-performing contrastive baseline. Our work imparts interesting findings about non-contrastive learning for link prediction and paves the way for future researchers to further expand upon this area.
Linkless Link Prediction via Relational Distillation
Oct 19, 2022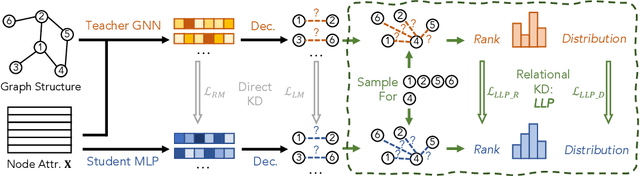
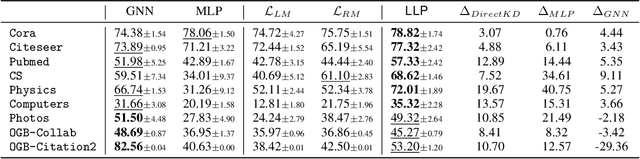
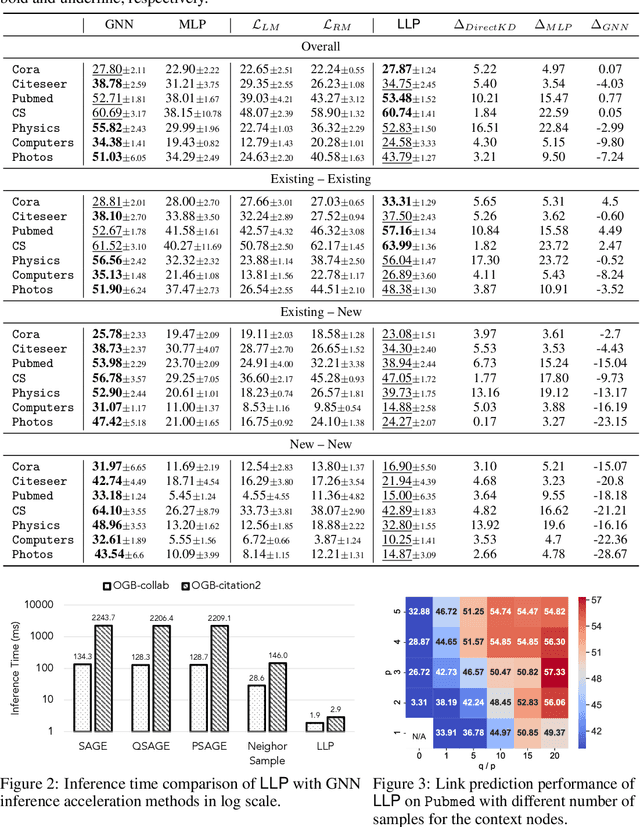
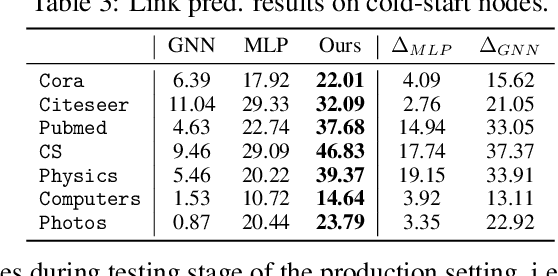
Graph Neural Networks (GNNs) have been widely used on graph data and have shown exceptional performance in the task of link prediction. Despite their effectiveness, GNNs often suffer from high latency due to non-trivial neighborhood data dependency in practical deployments. To address this issue, researchers have proposed methods based on knowledge distillation (KD) to transfer the knowledge from teacher GNNs to student MLPs, which are known to be efficient even with industrial scale data, and have shown promising results on node classification. Nonetheless, using KD to accelerate link prediction is still unexplored. In this work, we start with exploring two direct analogs of traditional KD for link prediction, i.e., predicted logit-based matching and node representation-based matching. Upon observing direct KD analogs do not perform well for link prediction, we propose a relational KD framework, Linkless Link Prediction (LLP). Unlike simple KD methods that match independent link logits or node representations, LLP distills relational knowledge that is centered around each (anchor) node to the student MLP. Specifically, we propose two matching strategies that complement each other: rank-based matching and distribution-based matching. Extensive experiments demonstrate that LLP boosts the link prediction performance of MLPs with significant margins, and even outperforms the teacher GNNs on 6 out of 9 benchmarks. LLP also achieves a 776.37x speedup in link prediction inference compared to GNNs on the large scale OGB-Citation2 dataset.
FRAPPE: $\underline{\text{F}}$ast $\underline{\text{Ra}}$nk $\underline{\text{App}}$roximation with $\underline{\text{E}}$xplainable Features for Tensors
Jun 19, 2022Tensor decompositions have proven to be effective in analyzing the structure of multidimensional data. However, most of these methods require a key parameter: the number of desired components. In the case of the CANDECOMP/PARAFAC decomposition (CPD), this value is known as the canonical rank and greatly affects the quality of the results. Existing methods use heuristics or Bayesian methods to estimate this value by repeatedly calculating the CPD, making them extremely computationally expensive. In this work, we propose FRAPPE and Self-FRAPPE: a cheaply supervised and a self-supervised method to estimate the canonical rank of a tensor without ever having to compute the CPD. We call FRAPPE cheaply supervised because it uses a fully synthetic training set without requiring real-world examples. We evaluate these methods on synthetic tensors, real tensors of known rank, and the weight tensor of a convolutional neural network. We show that FRAPPE and Self-FRAPPE offer large improvements in both effectiveness and speed, with a respective $15\%$ and $10\%$ improvement in MAPE and an $4000\times$ and $13\times$ improvement in evaluation speed over the best-performing baseline.