 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Regularization for Diffusion Models
Mar 02, 2026Diffusion models are typically trained using pointwise reconstruction objectives that are agnostic to the spectral and multi-scale structure of natural signals. We propose a loss-level spectral regularization framework that augments standard diffusion training with differentiable Fourier- and wavelet-domain losses, without modifying the diffusion process, model architecture, or sampling procedure. The proposed regularizers act as soft inductive biases that encourage appropriate frequency balance and coherent multi-scale structure in generated samples. Our approach is compatible with DDPM, DDIM, and EDM formulations and introduces negligible computational overhead. Experiments on image and audio generation demonstrate consistent improvements in sample quality, with the largest gains observed on higher-resolution, unconditional datasets where fine-scale structure is most challenging to model.
AD-SAM: Fine-Tuning the Segment Anything Vision Foundation Model for Autonomous Driving Perception
Oct 30, 2025This paper presents the Autonomous Driving Segment Anything Model (AD-SAM), a fine-tuned vision foundation model for semantic segmentation in autonomous driving (AD). AD-SAM extends the Segment Anything Model (SAM) with a dual-encoder and deformable decoder tailored to spatial and geometric complexity of road scenes. The dual-encoder produces multi-scale fused representations by combining global semantic context from SAM's pretrained Vision Transformer (ViT-H) with local spatial detail from a trainable convolutional deep learning backbone (i.e., ResNet-50). A deformable fusion module aligns heterogeneous features across scales and object geometries. The decoder performs progressive multi-stage refinement using deformable attention. Training is guided by a hybrid loss that integrates Focal, Dice, Lovasz-Softmax, and Surface losses, improving semantic class balance, boundary precision, and optimization stability. Experiments on the Cityscapes and Berkeley DeepDrive 100K (BDD100K) benchmarks show that AD-SAM surpasses SAM, Generalized SAM (G-SAM), and a deep learning baseline (DeepLabV3) in segmentation accuracy. It achieves 68.1 mean Intersection over Union (mIoU) on Cityscapes and 59.5 mIoU on BDD100K, outperforming SAM, G-SAM, and DeepLabV3 by margins of up to +22.9 and +19.2 mIoU in structured and diverse road scenes, respectively. AD-SAM demonstrates strong cross-domain generalization with a 0.87 retention score (vs. 0.76 for SAM), and faster, more stable learning dynamics, converging within 30-40 epochs, enjoying double the learning speed of benchmark models. It maintains 0.607 mIoU with only 1000 samples, suggesting data efficiency critical for reducing annotation costs. These results confirm that targeted architectural and optimization enhancements to foundation models enable reliable and scalable AD perception.
Efficiently Generating Multidimensional Calorimeter Data with Tensor Decomposition Parameterization
Aug 26, 2025Producing large complex simulation datasets can often be a time and resource consuming task. Especially when these experiments are very expensive, it is becoming more reasonable to generate synthetic data for downstream tasks. Recently, these methods may include using generative machine learning models such as Generative Adversarial Networks or diffusion models. As these generative models improve efficiency in producing useful data, we introduce an internal tensor decomposition to these generative models to even further reduce costs. More specifically, for multidimensional data, or tensors, we generate the smaller tensor factors instead of the full tensor, in order to significantly reduce the model's output and overall parameters. This reduces the costs of generating complex simulation data, and our experiments show the generated data remains useful. As a result, tensor decomposition has the potential to improve efficiency in generative models, especially when generating multidimensional data, or tensors.
Tensor Completion for Surrogate Modeling of Material Property Prediction
Jan 30, 2025



When designing materials to optimize certain properties, there are often many possible configurations of designs that need to be explored. For example, the materials' composition of elements will affect properties such as strength or conductivity, which are necessary to know when developing new materials. Exploring all combinations of elements to find optimal materials becomes very time consuming, especially when there are more design variables. For this reason, there is growing interest in using machine learning (ML) to predict a material's properties. In this work, we model the optimization of certain material properties as a tensor completion problem, to leverage the structure of our datasets and navigate the vast number of combinations of material configurations. Across a variety of material property prediction tasks, our experiments show tensor completion methods achieving 10-20% decreased error compared with baseline ML models such as GradientBoosting and Multilayer Perceptron (MLP), while maintaining similar training speed.
Multivariate Time Series Clustering for Environmental State Characterization of Ground-Based Gravitational-Wave Detectors
Dec 13, 2024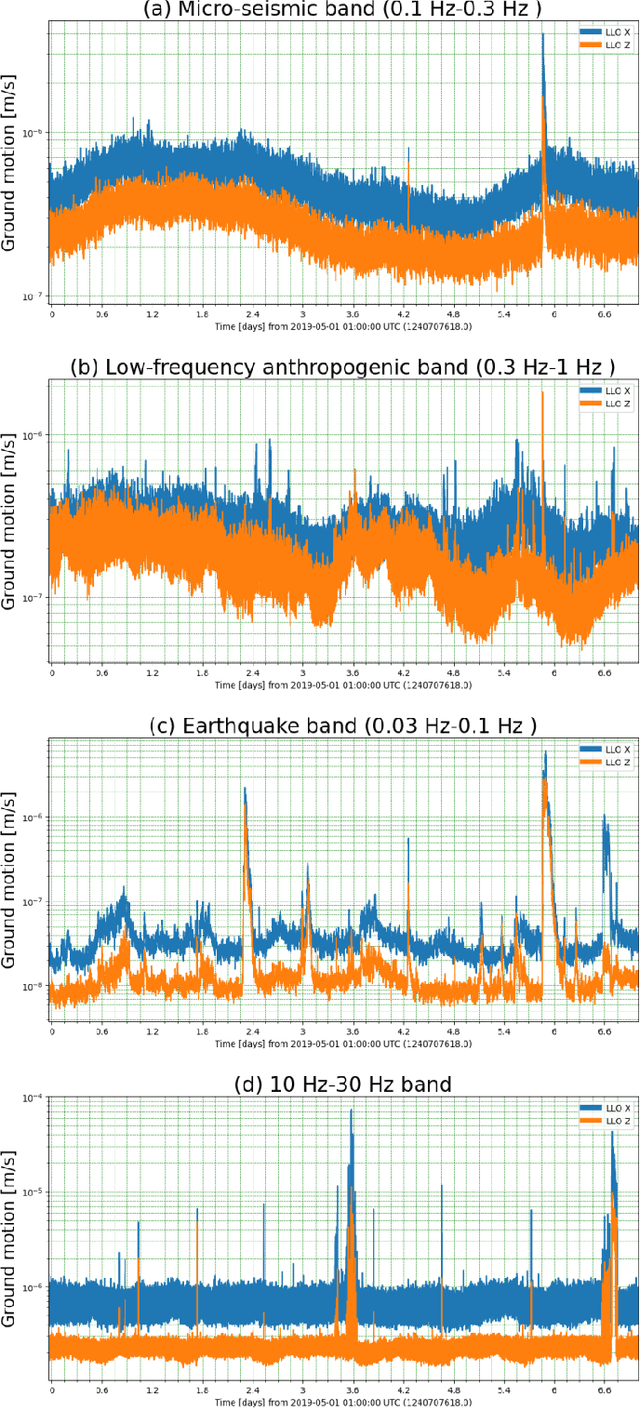
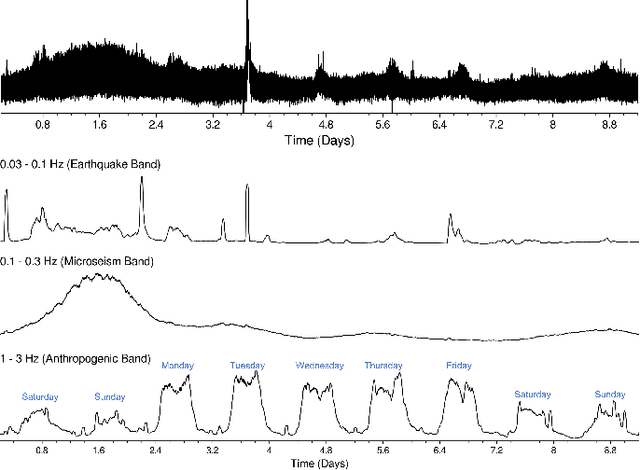
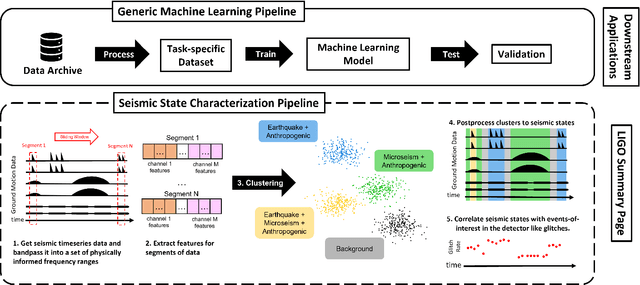
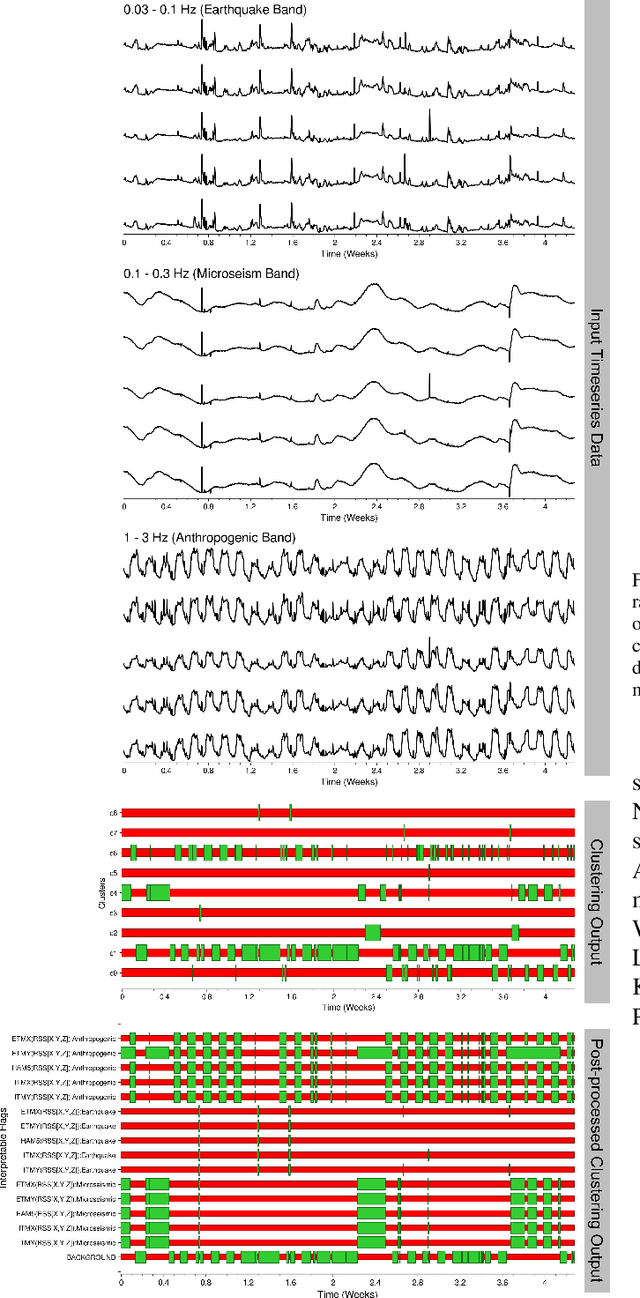
Gravitational-wave observatories like LIGO are large-scale, terrestrial instruments housed in infrastructure that spans a multi-kilometer geographic area and which must be actively controlled to maintain operational stability for long observation periods. Despite exquisite seismic isolation, they remain susceptible to seismic noise and other terrestrial disturbances that can couple undesirable vibrations into the instrumental infrastructure, potentially leading to control instabilities or noise artifacts in the detector output. It is, therefore, critical to characterize the seismic state of these observatories to identify a set of temporal patterns that can inform the detector operators in day-to-day monitoring and diagnostics. On a day-to-day basis, the operators monitor several seismically relevant data streams to diagnose operational instabilities and sources of noise using some simple empirically-determined thresholds. It can be untenable for a human operator to monitor multiple data streams in this manual fashion and thus a distillation of these data-streams into a more human-friendly format is sought. In this paper, we present an end-to-end machine learning pipeline for features-based multivariate time series clustering to achieve this goal and to provide actionable insights to the detector operators by correlating found clusters with events of interest in the detector.
Cross-Task Defense: Instruction-Tuning LLMs for Content Safety
May 24, 2024



Recent studies reveal that Large Language Models (LLMs) face challenges in balancing safety with utility, particularly when processing long texts for NLP tasks like summarization and translation. Despite defenses against malicious short questions, the ability of LLMs to safely handle dangerous long content, such as manuals teaching illicit activities, remains unclear. Our work aims to develop robust defenses for LLMs in processing malicious documents alongside benign NLP task queries. We introduce a defense dataset comprised of safety-related examples and propose single-task and mixed-task losses for instruction tuning. Our empirical results demonstrate that LLMs can significantly enhance their capacity to safely manage dangerous content with appropriate instruction tuning. Additionally, strengthening the defenses of tasks most susceptible to misuse is effective in protecting LLMs against processing harmful information. We also observe that trade-offs between utility and safety exist in defense strategies, where Llama2, utilizing our proposed approach, displays a significantly better balance compared to Llama1.
Improving Out-of-Vocabulary Handling in Recommendation Systems
Mar 27, 2024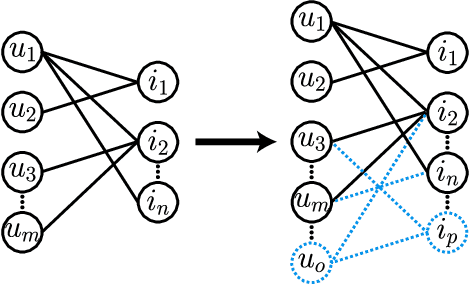

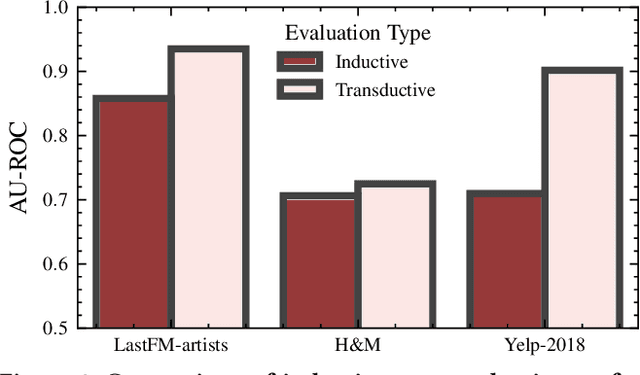

Recommendation systems (RS) are an increasingly relevant area for both academic and industry researchers, given their widespread impact on the daily online experiences of billions of users. One common issue in real RS is the cold-start problem, where users and items may not contain enough information to produce high-quality recommendations. This work focuses on a complementary problem: recommending new users and items unseen (out-of-vocabulary, or OOV) at training time. This setting is known as the inductive setting and is especially problematic for factorization-based models, which rely on encoding only those users/items seen at training time with fixed parameter vectors. Many existing solutions applied in practice are often naive, such as assigning OOV users/items to random buckets. In this work, we tackle this problem and propose approaches that better leverage available user/item features to improve OOV handling at the embedding table level. We discuss general-purpose plug-and-play approaches that are easily applicable to most RS models and improve inductive performance without negatively impacting transductive model performance. We extensively evaluate 9 OOV embedding methods on 5 models across 4 datasets (spanning different domains). One of these datasets is a proprietary production dataset from a prominent RS employed by a large social platform serving hundreds of millions of daily active users. In our experiments, we find that several proposed methods that exploit feature similarity using LSH consistently outperform alternatives on most model-dataset combinations, with the best method showing a mean improvement of 3.74% over the industry standard baseline in inductive performance. We release our code and hope our work helps practitioners make more informed decisions when handling OOV for their RS and further inspires academic research into improving OOV support in RS.
Can SAM recognize crops? Quantifying the zero-shot performance of a semantic segmentation foundation model on generating crop-type maps using satellite imagery for precision agriculture
Dec 04, 2023Climate change is increasingly disrupting worldwide agriculture, making global food production less reliable. To tackle the growing challenges in feeding the planet, cutting-edge management strategies, such as precision agriculture, empower farmers and decision-makers with rich and actionable information to increase the efficiency and sustainability of their farming practices. Crop-type maps are key information for decision-support tools but are challenging and costly to generate. We investigate the capabilities of Meta AI's Segment Anything Model (SAM) for crop-map prediction task, acknowledging its recent successes at zero-shot image segmentation. However, SAM being limited to up-to 3 channel inputs and its zero-shot usage being class-agnostic in nature pose unique challenges in using it directly for crop-type mapping. We propose using clustering consensus metrics to assess SAM's zero-shot performance in segmenting satellite imagery and producing crop-type maps. Although direct crop-type mapping is challenging using SAM in zero-shot setting, experiments reveal SAM's potential for swiftly and accurately outlining fields in satellite images, serving as a foundation for subsequent crop classification. This paper attempts to highlight a use-case of state-of-the-art image segmentation models like SAM for crop-type mapping and related specific needs of the agriculture industry, offering a potential avenue for automatic, efficient, and cost-effective data products for precision agriculture practices.
tHoops: A Multi-Aspect Analytical Framework Spatio-Temporal Basketball Data
Aug 23, 2018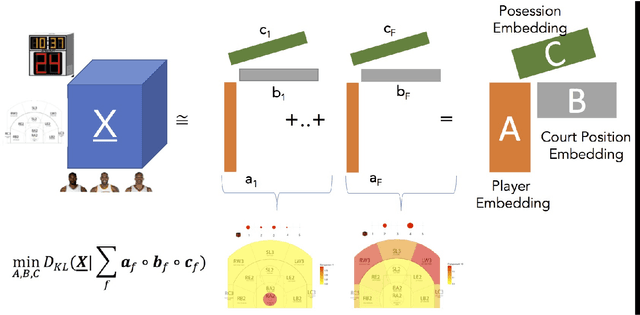
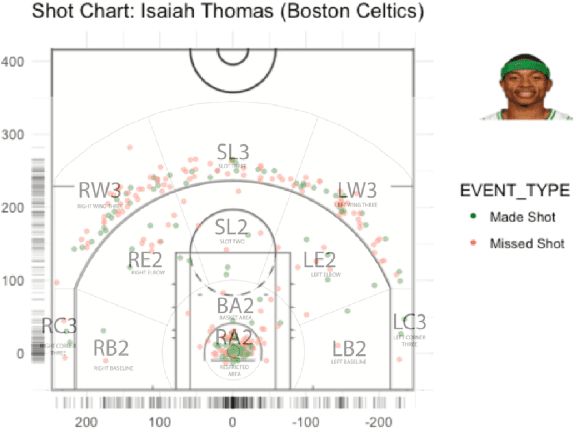
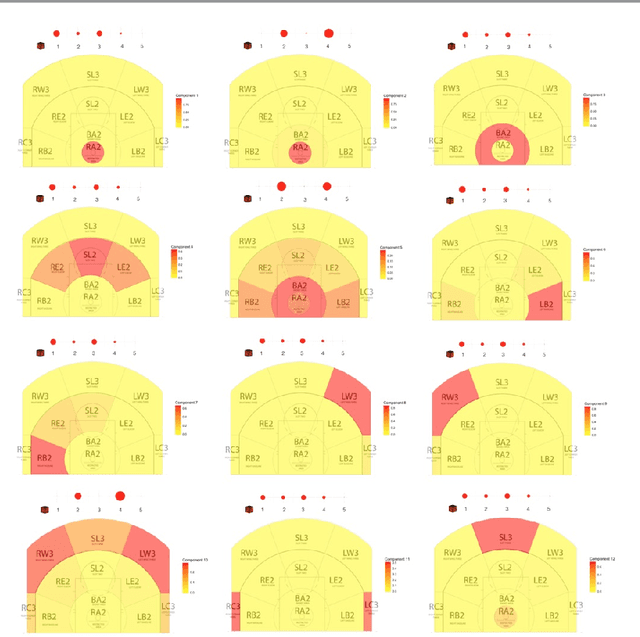
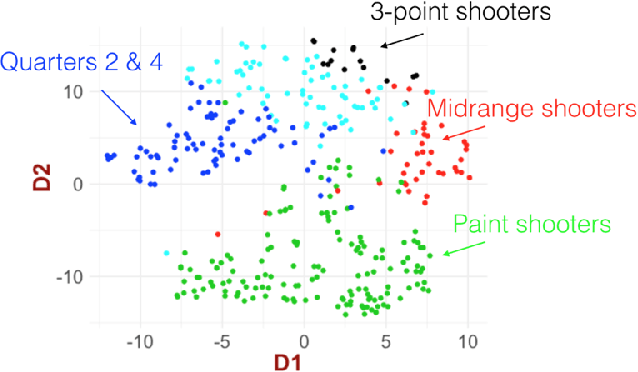
During the past few years advancements in sports information systems and technology has allowed us to collect a number of detailed spatio-temporal data capturing various aspects of basketball. For example, shot charts, that is, maps capturing locations of (made or missed) shots, and spatio-temporal trajectories for all the players on the court can capture information about the offensive and defensive tendencies and schemes of a team. Characterization of these processes is important for player and team comparisons, pre-game scouting, game preparation etc. Playing tendencies among teams have traditionally been compared in a heuristic manner. Recently automated ways for similar comparisons have appeared in the sports analytics literature. However, these approaches are almost exclusively focused on the spatial distribution of the underlying actions (usually shots taken), ignoring a multitude of other parameters that can affect the action studied. In this work, we propose a framework based on tensor decomposition for obtaining a set of prototype spatio-temporal patterns based on the core spatiotemporal information and contextual meta-data. The core of our framework is a 3D tensor X, whose dimensions represent the entity under consideration (team, player, possession etc.), the location on the court and time. We make use of the PARAFAC decomposition and we decompose the tensor into several interpretable patterns, that can be thought of as prototype patterns of the process examined (e.g., shot selection, offensive schemes etc.). We also introduce an approach for choosing the number of components to be considered. Using the tensor components, we can then express every entity as a weighted combination of these components. The framework introduced in this paper can have further applications in the work-flow of the basketball operations of a franchise, which we also briefly discuss.