 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeforestVis: Behavior Analysis of Machine Learning Models with Surrogate Decision Stumps
Mar 31, 2023



As the complexity of machine learning (ML) models increases and the applications in different (and critical) domains grow, there is a strong demand for more interpretable and trustworthy ML. One straightforward and model-agnostic way to interpret complex ML models is to train surrogate models, such as rule sets and decision trees, that sufficiently approximate the original ones while being simpler and easier-to-explain. Yet, rule sets can become very lengthy, with many if-else statements, and decision tree depth grows rapidly when accurately emulating complex ML models. In such cases, both approaches can fail to meet their core goal, providing users with model interpretability. We tackle this by proposing DeforestVis, a visual analytics tool that offers user-friendly summarization of the behavior of complex ML models by providing surrogate decision stumps (one-level decision trees) generated with the adaptive boosting (AdaBoost) technique. Our solution helps users to explore the complexity vs fidelity trade-off by incrementally generating more stumps, creating attribute-based explanations with weighted stumps to justify decision making, and analyzing the impact of rule overriding on training instance allocation between one or more stumps. An independent test set allows users to monitor the effectiveness of manual rule changes and form hypotheses based on case-by-case investigations. We show the applicability and usefulness of DeforestVis with two use cases and expert interviews with data analysts and model developers.
Visual Cluster Separation Using High-Dimensional Sharpened Dimensionality Reduction
Oct 01, 2021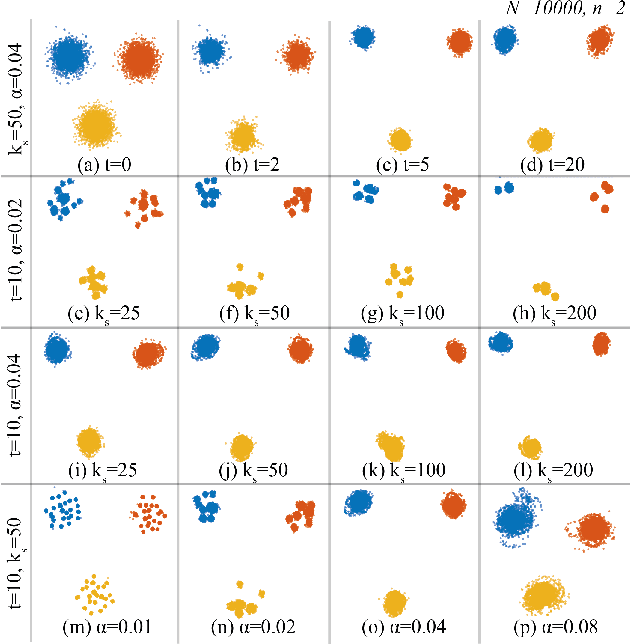

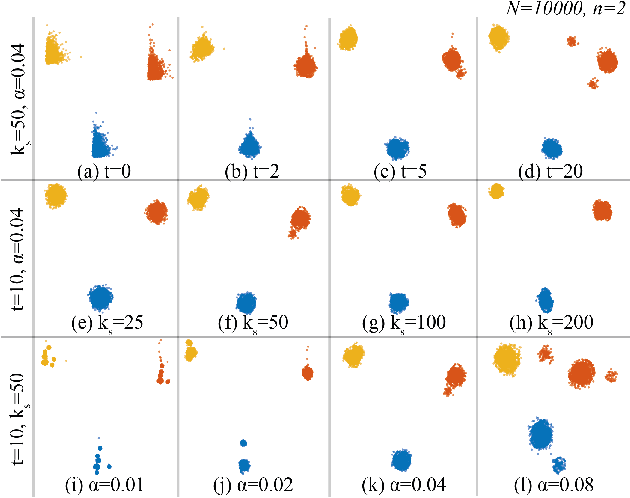
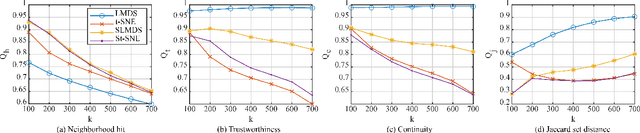
Applying dimensionality reduction (DR) to large, high-dimensional data sets can be challenging when distinguishing the underlying high-dimensional data clusters in a 2D projection for exploratory analysis. We address this problem by first sharpening the clusters in the original high-dimensional data prior to the DR step using Local Gradient Clustering (LGC). We then project the sharpened data from the high-dimensional space to 2D by a user-selected DR method. The sharpening step aids this method to preserve cluster separation in the resulting 2D projection. With our method, end-users can label each distinct cluster to further analyze an otherwise unlabeled data set. Our `High-Dimensional Sharpened DR' (HD-SDR) method, tested on both synthetic and real-world data sets, is favorable to DR methods with poor cluster separation and yields a better visual cluster separation than these DR methods with no sharpening. Our method achieves good quality (measured by quality metrics) and scales computationally well with large high-dimensional data. To illustrate its concrete applications, we further apply HD-SDR on a recent astronomical catalog.
Deep Learning Multidimensional Projections
Feb 21, 2019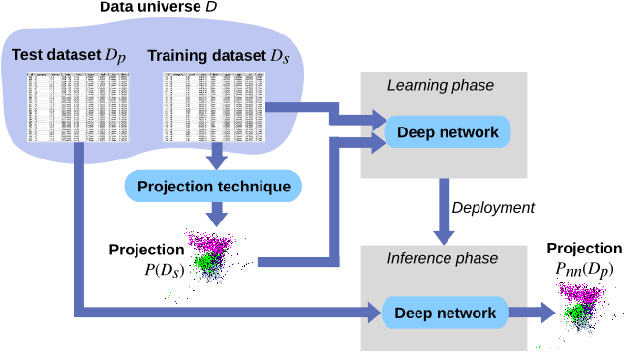
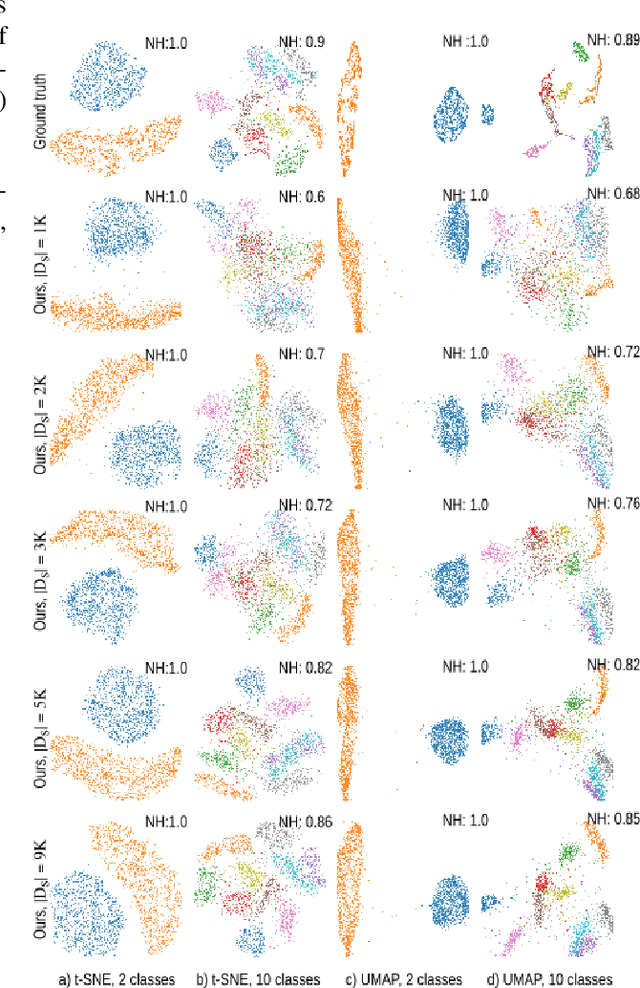

Dimensionality reduction methods, also known as projections, are frequently used for exploring multidimensional data in machine learning, data science, and information visualization. Among these, t-SNE and its variants have become very popular for their ability to visually separate distinct data clusters. However, such methods are computationally expensive for large datasets, suffer from stability problems, and cannot directly handle out-of-sample data. We propose a learning approach to construct such projections. We train a deep neural network based on a collection of samples from a given data universe, and their corresponding projections, and next use the network to infer projections of data from the same, or similar, universes. Our approach generates projections with similar characteristics as the learned ones, is computationally two to three orders of magnitude faster than SNE-class methods, has no complex-to-set user parameters, handles out-of-sample data in a stable manner, and can be used to learn any projection technique. We demonstrate our proposal on several real-world high dimensional datasets from machine learning.