 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLINT: Learning-based Flow Estimation and Temporal Interpolation for Scientific Ensemble Visualization
Sep 27, 2024



We present FLINT (learning-based FLow estimation and temporal INTerpolation), a novel deep learning-based approach to estimate flow fields for 2D+time and 3D+time scientific ensemble data. FLINT can flexibly handle different types of scenarios with (1) a flow field being partially available for some members (e.g., omitted due to space constraints) or (2) no flow field being available at all (e.g., because it could not be acquired during an experiment). The design of our architecture allows to flexibly cater to both cases simply by adapting our modular loss functions, effectively treating the different scenarios as flow-supervised and flow-unsupervised problems, respectively (with respect to the presence or absence of ground-truth flow). To the best of our knowledge, FLINT is the first approach to perform flow estimation from scientific ensembles, generating a corresponding flow field for each discrete timestep, even in the absence of original flow information. Additionally, FLINT produces high-quality temporal interpolants between scalar fields. FLINT employs several neural blocks, each featuring several convolutional and deconvolutional layers. We demonstrate performance and accuracy for different usage scenarios with scientific ensembles from both simulations and experiments.
Human Motion Detection Using Sharpened Dimensionality Reduction and Clustering
Feb 23, 2022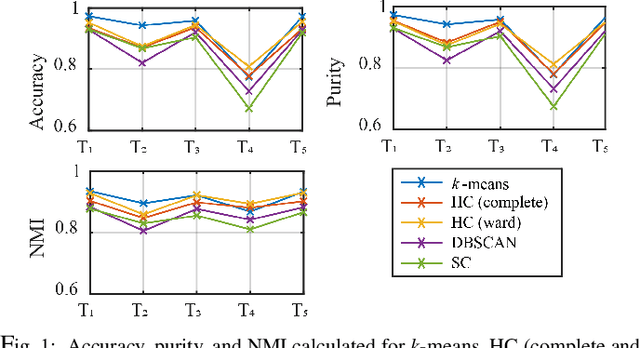
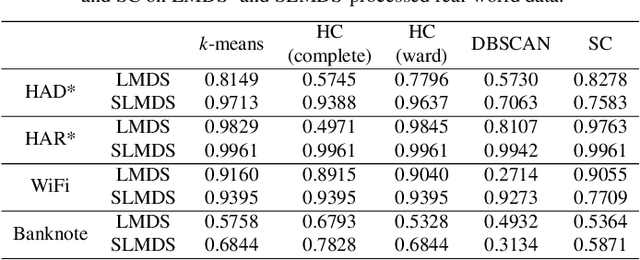

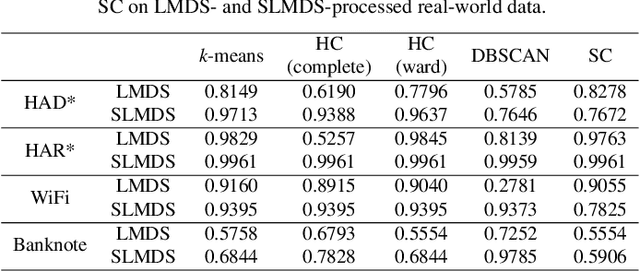
Sharpened dimensionality reduction (SDR), which belongs to the class of multidimensional projection techniques, has recently been introduced to tackle the challenges in the exploratory and visual analysis of high-dimensional data. SDR has been applied to various real-world datasets, such as human activity sensory data and astronomical datasets. However, manually labeling the samples from the generated projection are expensive. To address this problem, we propose here to use clustering methods such as k-means, Hierarchical Clustering, Density-Based Spatial Clustering of Applications with Noise (DBSCAN), and Spectral Clustering to easily label the 2D projections of high-dimensional data. We test our pipeline of SDR and the clustering methods on a range of synthetic and real-world datasets, including two different public human activity datasets extracted from smartphone accelerometer or gyroscope recordings of various movements. We apply clustering to assess the visual cluster separation of SDR, both qualitatively and quantitatively. We conclude that clustering SDR results yields better labeling results than clustering plain DR, and that k-means is the recommended clustering method for SDR in terms of clustering accuracy, ease-of-use, and computational scalability.
Visual Cluster Separation Using High-Dimensional Sharpened Dimensionality Reduction
Oct 01, 2021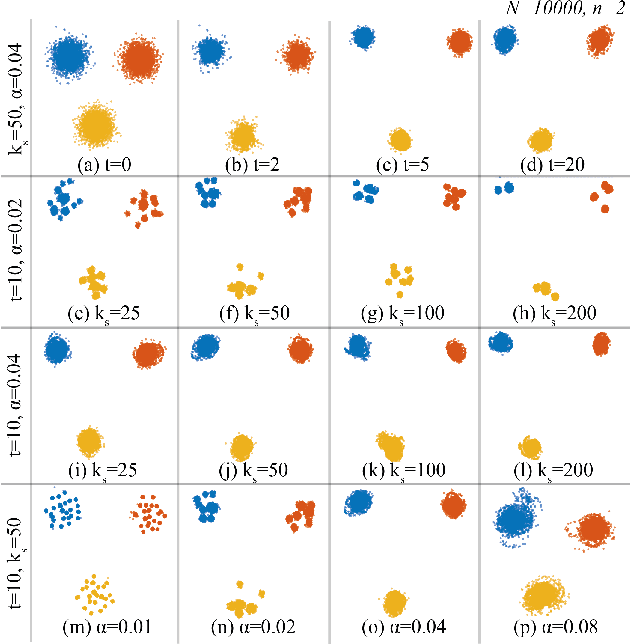

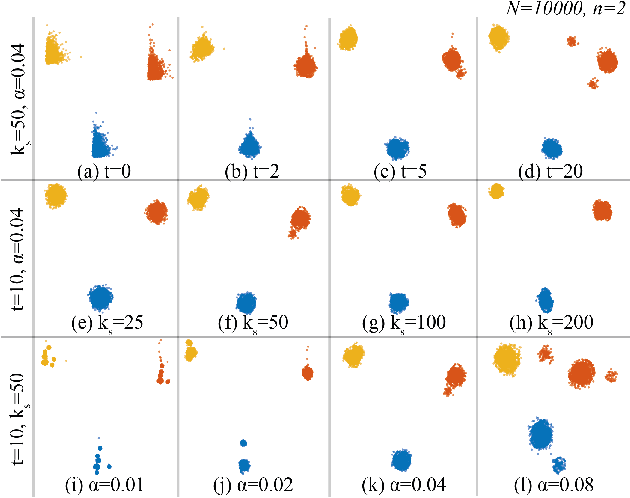
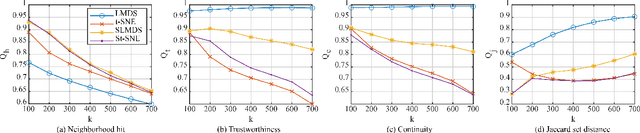
Applying dimensionality reduction (DR) to large, high-dimensional data sets can be challenging when distinguishing the underlying high-dimensional data clusters in a 2D projection for exploratory analysis. We address this problem by first sharpening the clusters in the original high-dimensional data prior to the DR step using Local Gradient Clustering (LGC). We then project the sharpened data from the high-dimensional space to 2D by a user-selected DR method. The sharpening step aids this method to preserve cluster separation in the resulting 2D projection. With our method, end-users can label each distinct cluster to further analyze an otherwise unlabeled data set. Our `High-Dimensional Sharpened DR' (HD-SDR) method, tested on both synthetic and real-world data sets, is favorable to DR methods with poor cluster separation and yields a better visual cluster separation than these DR methods with no sharpening. Our method achieves good quality (measured by quality metrics) and scales computationally well with large high-dimensional data. To illustrate its concrete applications, we further apply HD-SDR on a recent astronomical catalog.