 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPLE: Self-supervised Learning-Enhanced Nonlinear Dimensionality Reduction for Visual Analysis
Jan 28, 2026We present a new nonlinear dimensionality reduction method, MAPLE, that enhances UMAP by improving manifold modeling. MAPLE employs a self-supervised learning approach to more efficiently encode low-dimensional manifold geometry. Central to this approach are maximum manifold capacity representations (MMCRs), which help untangle complex manifolds by compressing variances among locally similar data points while amplifying variance among dissimilar data points. This design is particularly effective for high-dimensional data with substantial intra-cluster variance and curved manifold structures, such as biological or image data. Our qualitative and quantitative evaluations demonstrate that MAPLE can produce clearer visual cluster separations and finer subcluster resolution than UMAP while maintaining comparable computational cost.
Adversarial Attacks on Machine Learning-Aided Visualizations
Sep 04, 2024Research in ML4VIS investigates how to use machine learning (ML) techniques to generate visualizations, and the field is rapidly growing with high societal impact. However, as with any computational pipeline that employs ML processes, ML4VIS approaches are susceptible to a range of ML-specific adversarial attacks. These attacks can manipulate visualization generations, causing analysts to be tricked and their judgments to be impaired. Due to a lack of synthesis from both visualization and ML perspectives, this security aspect is largely overlooked by the current ML4VIS literature. To bridge this gap, we investigate the potential vulnerabilities of ML-aided visualizations from adversarial attacks using a holistic lens of both visualization and ML perspectives. We first identify the attack surface (i.e., attack entry points) that is unique in ML-aided visualizations. We then exemplify five different adversarial attacks. These examples highlight the range of possible attacks when considering the attack surface and multiple different adversary capabilities. Our results show that adversaries can induce various attacks, such as creating arbitrary and deceptive visualizations, by systematically identifying input attributes that are influential in ML inferences. Based on our observations of the attack surface characteristics and the attack examples, we underline the importance of comprehensive studies of security issues and defense mechanisms as a call of urgency for the ML4VIS community.
Simbanex: Similarity-based Exploration of IEEE VIS Publications
Aug 31, 2024Embeddings are powerful tools for transforming complex and unstructured data into numeric formats suitable for computational analysis tasks. In this work, we use multiple embeddings for similarity calculations to be applied in bibliometrics and scientometrics. We build a multivariate network (MVN) from a large set of scientific publications and explore an aspect-driven analysis approach to reveal similarity patterns in the given publication data. By dividing our MVN into separately embeddable aspects, we are able to obtain a flexible vector representation which we use as input to a novel method of similarity-based clustering. Based on these preprocessing steps, we developed a visual analytics application, called Simbanex, that has been designed for the interactive visual exploration of similarity patterns within the underlying publications.
Visualization for Trust in Machine Learning Revisited: The State of the Field in 2023
Mar 18, 2024



Visualization for explainable and trustworthy machine learning remains one of the most important and heavily researched fields within information visualization and visual analytics with various application domains, such as medicine, finance, and bioinformatics. After our 2020 state-of-the-art report comprising 200 techniques, we have persistently collected peer-reviewed articles describing visualization techniques, categorized them based on the previously established categorization schema consisting of 119 categories, and provided the resulting collection of 542 techniques in an online survey browser. In this survey article, we present the updated findings of new analyses of this dataset as of fall 2023 and discuss trends, insights, and eight open challenges for using visualizations in machine learning. Our results corroborate the rapidly growing trend of visualization techniques for increasing trust in machine learning models in the past three years, with visualization found to help improve popular model explainability methods and check new deep learning architectures, for instance.
DeforestVis: Behavior Analysis of Machine Learning Models with Surrogate Decision Stumps
Mar 31, 2023



As the complexity of machine learning (ML) models increases and the applications in different (and critical) domains grow, there is a strong demand for more interpretable and trustworthy ML. One straightforward and model-agnostic way to interpret complex ML models is to train surrogate models, such as rule sets and decision trees, that sufficiently approximate the original ones while being simpler and easier-to-explain. Yet, rule sets can become very lengthy, with many if-else statements, and decision tree depth grows rapidly when accurately emulating complex ML models. In such cases, both approaches can fail to meet their core goal, providing users with model interpretability. We tackle this by proposing DeforestVis, a visual analytics tool that offers user-friendly summarization of the behavior of complex ML models by providing surrogate decision stumps (one-level decision trees) generated with the adaptive boosting (AdaBoost) technique. Our solution helps users to explore the complexity vs fidelity trade-off by incrementally generating more stumps, creating attribute-based explanations with weighted stumps to justify decision making, and analyzing the impact of rule overriding on training instance allocation between one or more stumps. An independent test set allows users to monitor the effectiveness of manual rule changes and form hypotheses based on case-by-case investigations. We show the applicability and usefulness of DeforestVis with two use cases and expert interviews with data analysts and model developers.
MetaStackVis: Visually-Assisted Performance Evaluation of Metamodels
Dec 07, 2022
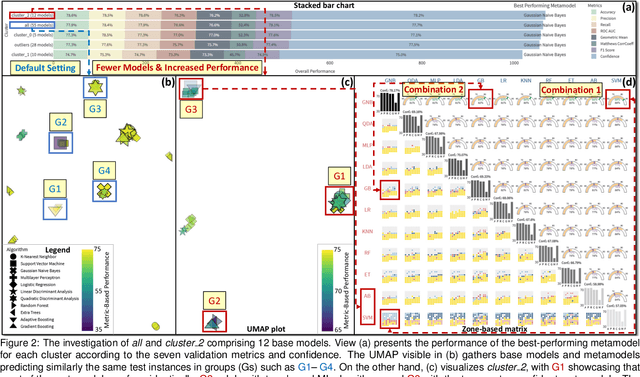
Stacking (or stacked generalization) is an ensemble learning method with one main distinctiveness from the rest: even though several base models are trained on the original data set, their predictions are further used as input data for one or more metamodels arranged in at least one extra layer. Composing a stack of models can produce high-performance outcomes, but it usually involves a trial-and-error process. Therefore, our previously developed visual analytics system, StackGenVis, was mainly designed to assist users in choosing a set of top-performing and diverse models by measuring their predictive performance. However, it only employs a single logistic regression metamodel. In this paper, we investigate the impact of alternative metamodels on the performance of stacking ensembles using a novel visualization tool, called MetaStackVis. Our interactive tool helps users to visually explore different singular and pairs of metamodels according to their predictive probabilities and multiple validation metrics, as well as their ability to predict specific problematic data instances. MetaStackVis was evaluated with a usage scenario based on a medical data set and via expert interviews.
HardVis: Visual Analytics to Handle Instance Hardness Using Undersampling and Oversampling Techniques
Mar 29, 2022
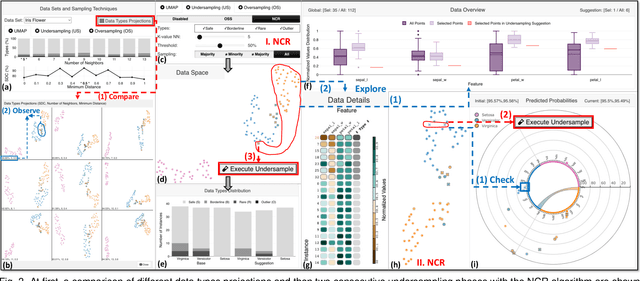

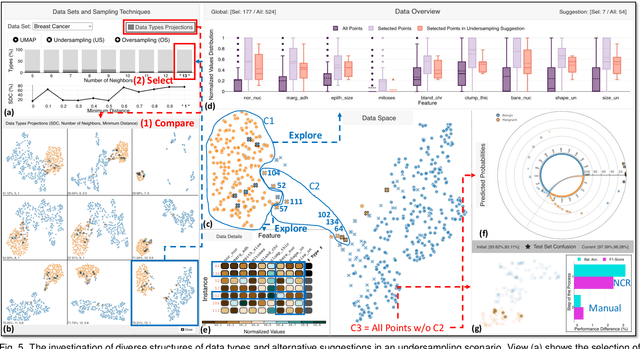
Despite the tremendous advances in machine learning (ML), training with imbalanced data still poses challenges in many real-world applications. Among a series of diverse techniques to solve this problem, sampling algorithms are regarded as an efficient solution. However, the problem is more fundamental, with many works emphasizing the importance of instance hardness. This issue refers to the significance of managing unsafe or potentially noisy instances that are more likely to be misclassified and serve as the root cause of poor classification performance. This paper introduces HardVis, a visual analytics system designed to handle instance hardness mainly in imbalanced classification scenarios. Our proposed system assists users in visually comparing different distributions of data types, selecting types of instances based on local characteristics that will later be affected by the active sampling method, and validating which suggestions from undersampling or oversampling techniques are beneficial for the ML model. Additionally, rather than uniformly undersampling/oversampling a specific class, we allow users to find and sample easy and difficult to classify training instances from all classes. Users can explore subsets of data from different perspectives to decide all those parameters, while HardVis keeps track of their steps and evaluates the model's predictive performance in a test set separately. The end result is a well-balanced data set that boosts the predictive power of the ML model. The efficacy and effectiveness of HardVis are demonstrated with a hypothetical usage scenario and a use case. Finally, we also look at how useful our system is based on feedback we received from ML experts.
VisRuler: Visual Analytics for Extracting Decision Rules from Bagged and Boosted Decision Trees
Dec 01, 2021
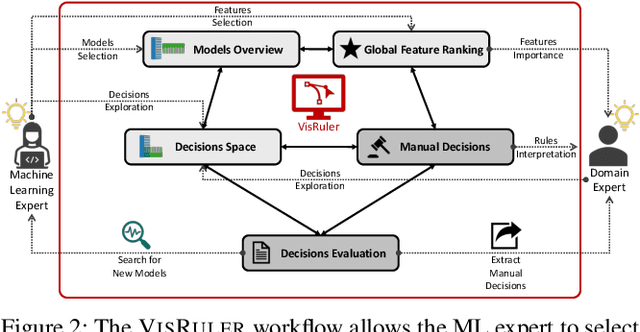
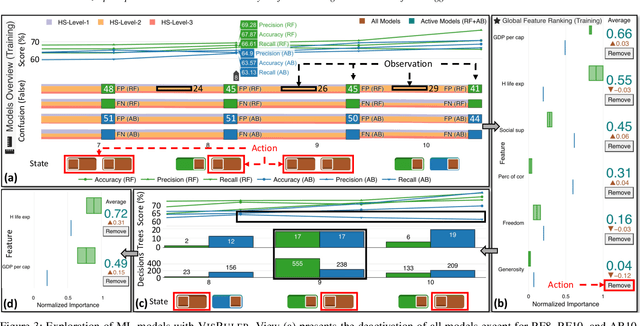
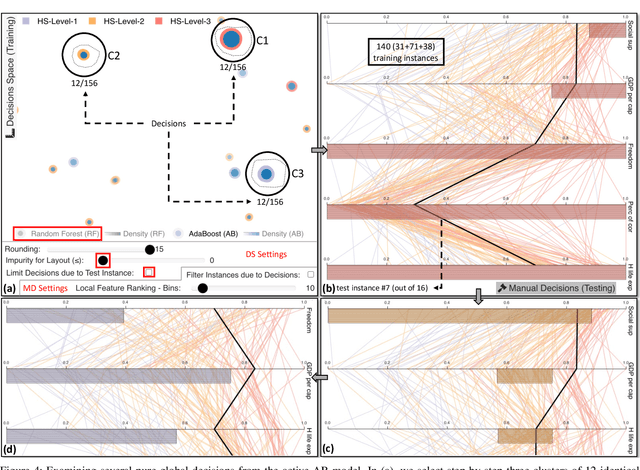
Bagging and boosting are two popular ensemble methods in machine learning (ML) that produce many individual decision trees. Due to the inherent ensemble characteristic of these methods, they typically outperform single decision trees or other ML models in predictive performance. However, numerous decision paths are generated for each decision tree, increasing the overall complexity of the model and hindering its use in domains that require trustworthy and explainable decisions, such as finance, social care, and health care. Thus, the interpretability of bagging and boosting algorithms, such as random forests and adaptive boosting, reduces as the number of decisions rises. In this paper, we propose a visual analytics tool that aims to assist users in extracting decisions from such ML models via a thorough visual inspection workflow that includes selecting a set of robust and diverse models (originating from different ensemble learning algorithms), choosing important features according to their global contribution, and deciding which decisions are essential for global explanation (or locally, for specific cases). The outcome is a final decision based on the class agreement of several models and the explored manual decisions exported by users. Finally, we evaluate the applicability and effectiveness of VisRuler via a use case, a usage scenario, and a user study.
FeatureEnVi: Visual Analytics for Feature Engineering Using Stepwise Selection and Semi-Automatic Extraction Approaches
Mar 26, 2021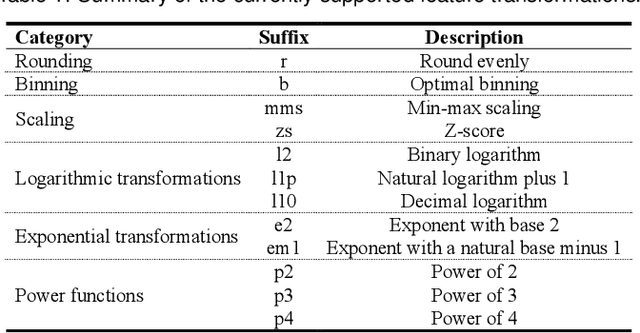
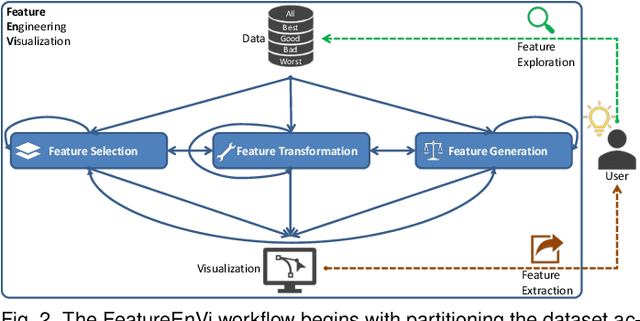
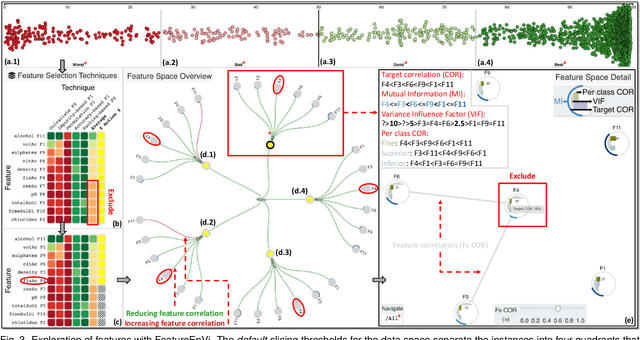
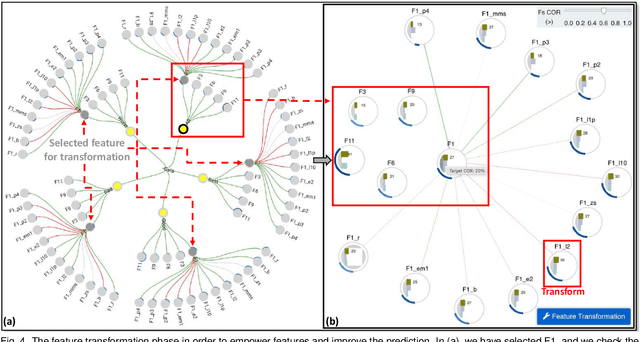
The machine learning (ML) life cycle involves a series of iterative steps, from the effective gathering and preparation of the data, including complex feature engineering processes, to the presentation and improvement of results, with various algorithms to choose from in every step. Feature engineering in particular can be very beneficial for ML, leading to numerous improvements such as boosting the predictive results, decreasing computational times, reducing excessive noise, and increasing the transparency behind the decisions taken during the training. Despite that, while several visual analytics tools exist to monitor and control the different stages of the ML life cycle (especially those related to data and algorithms), feature engineering support remains inadequate. In this paper, we present FeatureEnVi, a visual analytics system specifically designed to assist with the feature engineering process. Our proposed system helps users to choose the most important feature, to transform the original features into powerful alternatives, and to experiment with different feature generation combinations. Additionally, data space slicing allows users to explore the impact of features on both local and global scales. FeatureEnVi utilizes multiple automatic feature selection techniques; furthermore, it visually guides users with statistical evidence about the influence of each feature (or subsets of features). The final outcome is the extraction of heavily engineered features, evaluated by multiple validation metrics. The usefulness and applicability of FeatureEnVi are demonstrated with two use cases, using a popular red wine quality data set and publicly available data related to vehicle recognition from their silhouettes. We also report feedback from interviews with ML experts and a visualization researcher who assessed the effectiveness of our system.
VisEvol: Visual Analytics to Support Hyperparameter Search through Evolutionary Optimization
Dec 02, 2020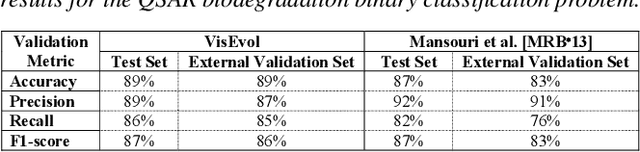
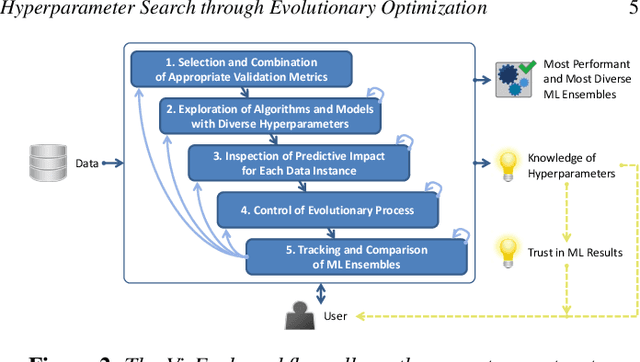
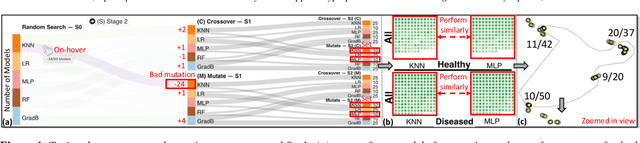
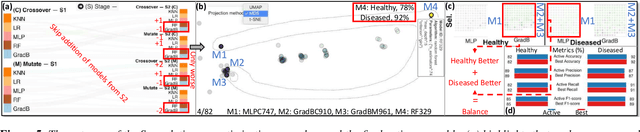
During the training phase of machine learning (ML) models, it is usually necessary to configure several hyperparameters. This process is computationally intensive and requires an extensive search to infer the best hyperparameter set for the given problem. The challenge is exacerbated by the fact that most ML models are complex internally, and training involves trial-and-error processes that could remarkably affect the predictive result. Moreover, each hyperparameter of an ML algorithm is potentially intertwined with the others, and changing it might result in unforeseeable impacts on the remaining hyperparameters. Evolutionary optimization is a promising method to try and address those issues. According to this method, performant models are stored, while the remainder are improved through crossover and mutation processes inspired by genetic algorithms. We present VisEvol, a visual analytics tool that supports interactive exploration of hyperparameters and intervention in this evolutionary procedure. In summary, our proposed tool helps the user to generate new models through evolution and eventually explore powerful hyperparameter combinations in diverse regions of the extensive hyperparameter space. The outcome is a voting ensemble (with equal rights) that boosts the final predictive performance. The utility and applicability of VisEvol are demonstrated with two use cases and interviews with ML experts who evaluated the effectiveness of the tool.