 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting a Large Language Model with a Combination of Text and Visual Data for Conversational Visualization of Global Geospatial Data
Jan 16, 2025

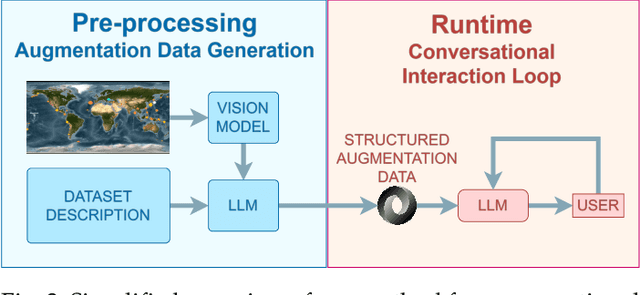

We present a method for augmenting a Large Language Model (LLM) with a combination of text and visual data to enable accurate question answering in visualization of scientific data, making conversational visualization possible. LLMs struggle with tasks like visual data interaction, as they lack contextual visual information. We address this problem by merging a text description of a visualization and dataset with snapshots of the visualization. We extract their essential features into a structured text file, highly compact, yet descriptive enough to appropriately augment the LLM with contextual information, without any fine-tuning. This approach can be applied to any visualization that is already finally rendered, as long as it is associated with some textual description.
NEOviz: Uncertainty-Driven Visual Analysis of Asteroid Trajectories
Nov 05, 2024We introduce NEOviz, an interactive visualization system designed to assist planetary defense experts in the visual analysis of the movements of near-Earth objects in the Solar System that might prove hazardous to Earth. Asteroids are often discovered using optical telescopes and their trajectories are calculated from images, resulting in an inherent asymmetric uncertainty in their position and velocity. Consequently, we typically cannot determine the exact trajectory of an asteroid, and an ensemble of trajectories must be generated to estimate an asteroid's movement over time. When propagating these ensembles over decades, it is challenging to visualize the varying paths and determine their potential impact on Earth, which could cause catastrophic damage. NEOviz equips experts with the necessary tools to effectively analyze the existing catalog of asteroid observations. In particular, we present a novel approach for visualizing the 3D uncertainty region through which an asteroid travels, while providing accurate spatial context in relation to system-critical infrastructure such as Earth, the Moon, and artificial satellites. Furthermore, we use NEOviz to visualize the divergence of asteroid trajectories, capturing high-variance events in an asteroid's orbital properties. For potential impactors, we combine the 3D visualization with an uncertainty-aware impact map to illustrate the potential risks to human populations. NEOviz was developed with continuous input from members of the planetary defense community through a participatory design process. It is exemplified in three real-world use cases and evaluated via expert feedback interviews.
Exploratory Visual Analysis for Increasing Data Readiness in Artificial Intelligence Projects
Sep 05, 2024



We present experiences and lessons learned from increasing data readiness of heterogeneous data for artificial intelligence projects using visual analysis methods. Increasing the data readiness level involves understanding both the data as well as the context in which it is used, which are challenges well suitable to visual analysis. For this purpose, we contribute a mapping between data readiness aspects and visual analysis techniques suitable for different data types. We use the defined mapping to increase data readiness levels in use cases involving time-varying data, including numerical, categorical, and text. In addition to the mapping, we extend the data readiness concept to better take aspects of the task and solution into account and explicitly address distribution shifts during data collection time. We report on our experiences in using the presented visual analysis techniques to aid future artificial intelligence projects in raising the data readiness level.
Adversarial Attacks on Machine Learning-Aided Visualizations
Sep 04, 2024Research in ML4VIS investigates how to use machine learning (ML) techniques to generate visualizations, and the field is rapidly growing with high societal impact. However, as with any computational pipeline that employs ML processes, ML4VIS approaches are susceptible to a range of ML-specific adversarial attacks. These attacks can manipulate visualization generations, causing analysts to be tricked and their judgments to be impaired. Due to a lack of synthesis from both visualization and ML perspectives, this security aspect is largely overlooked by the current ML4VIS literature. To bridge this gap, we investigate the potential vulnerabilities of ML-aided visualizations from adversarial attacks using a holistic lens of both visualization and ML perspectives. We first identify the attack surface (i.e., attack entry points) that is unique in ML-aided visualizations. We then exemplify five different adversarial attacks. These examples highlight the range of possible attacks when considering the attack surface and multiple different adversary capabilities. Our results show that adversaries can induce various attacks, such as creating arbitrary and deceptive visualizations, by systematically identifying input attributes that are influential in ML inferences. Based on our observations of the attack surface characteristics and the attack examples, we underline the importance of comprehensive studies of security issues and defense mechanisms as a call of urgency for the ML4VIS community.
Visual Analytics of Multivariate Networks with Representation Learning and Composite Variable Construction
Mar 16, 2023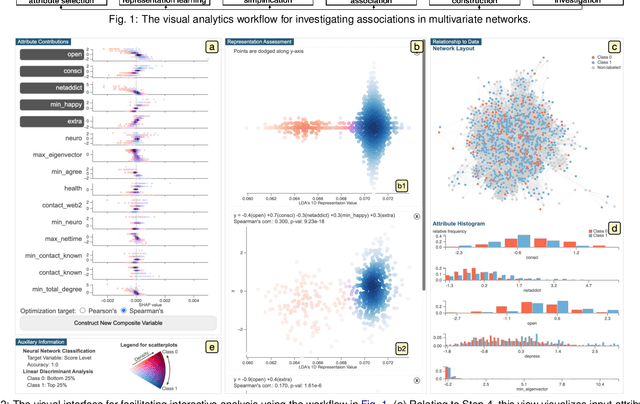
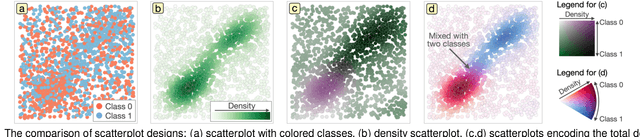
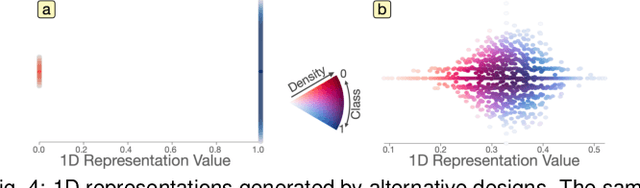
Multivariate networks are commonly found in real-world data-driven applications. Uncovering and understanding the relations of interest in multivariate networks is not a trivial task. This paper presents a visual analytics workflow for studying multivariate networks to extract associations between different structural and semantic characteristics of the networks (e.g., what are the combinations of attributes largely relating to the density of a social network?). The workflow consists of a neural-network-based learning phase to classify the data based on the chosen input and output attributes, a dimensionality reduction and optimization phase to produce a simplified set of results for examination, and finally an interpreting phase conducted by the user through an interactive visualization interface. A key part of our design is a composite variable construction step that remodels nonlinear features obtained by neural networks into linear features that are intuitive to interpret. We demonstrate the capabilities of this workflow with multiple case studies on networks derived from social media usage and also evaluate the workflow through an expert interview.
Feature Learning for Dimensionality Reduction toward Maximal Extraction of Hidden Patterns
Jun 28, 2022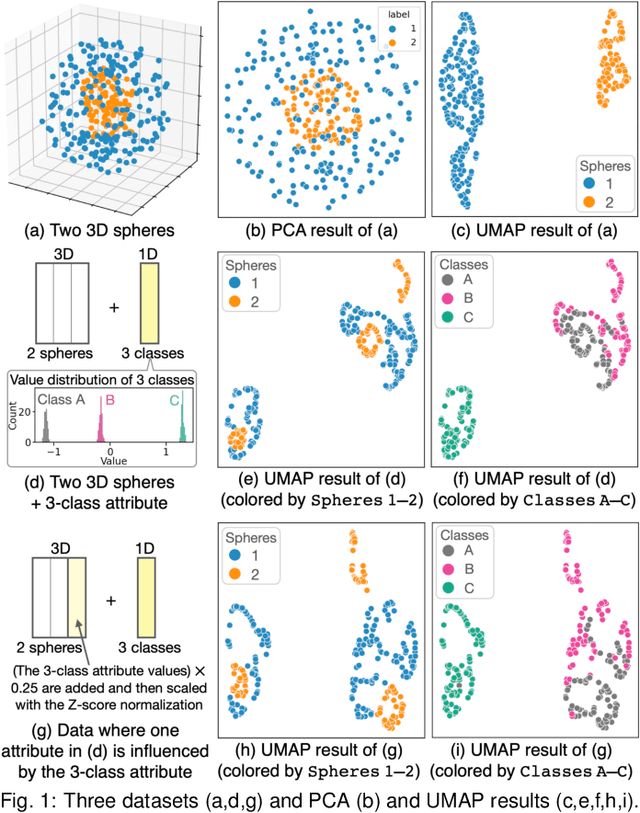
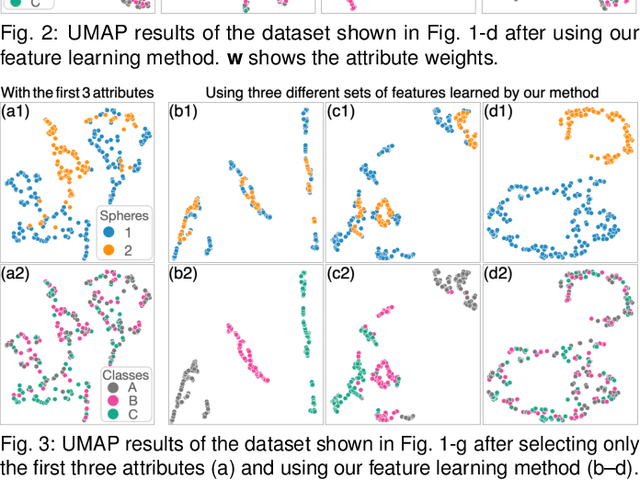
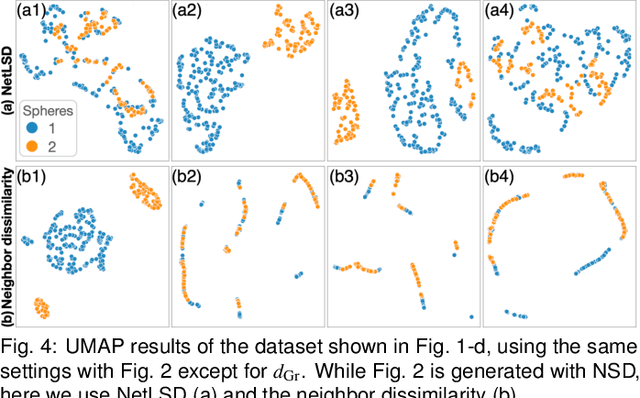
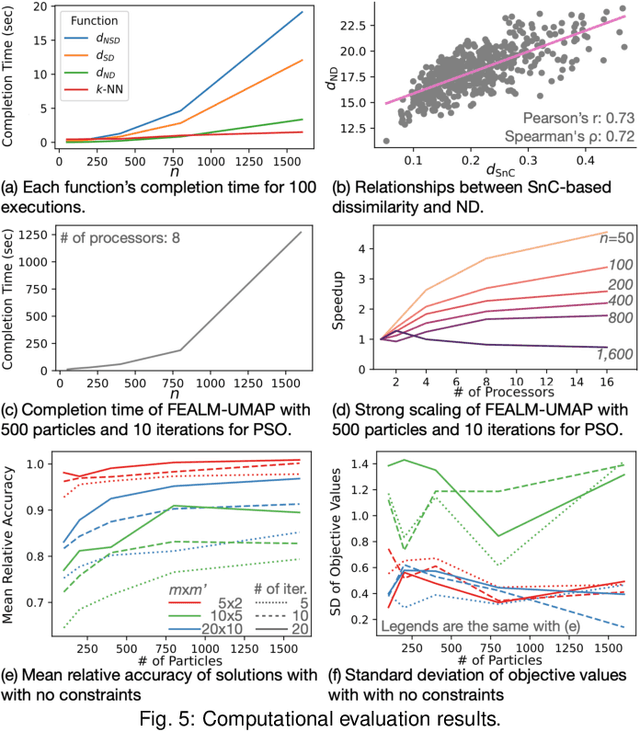
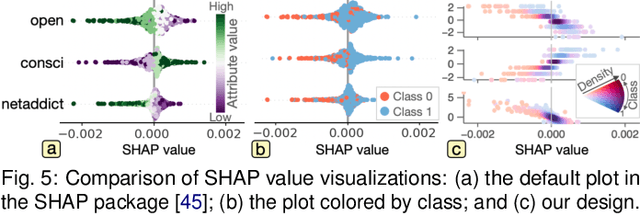
Dimensionality reduction (DR) plays a vital role in the visual analysis of high-dimensional data. One main aim of DR is to reveal hidden patterns that lie on intrinsic low-dimensional manifolds. However, DR often overlooks important patterns when the manifolds are strongly distorted or hidden by certain influential data attributes. This paper presents a feature learning framework, FEALM, designed to generate an optimized set of data projections for nonlinear DR in order to capture important patterns in the hidden manifolds. These projections produce maximally different nearest-neighbor graphs so that resultant DR outcomes are significantly different. To achieve such a capability, we design an optimization algorithm as well as introduce a new graph dissimilarity measure, called neighbor-shape dissimilarity. Additionally, we develop interactive visualizations to assist comparison of obtained DR results and interpretation of each DR result. We demonstrate FEALM's effectiveness through experiments using synthetic datasets and multiple case studies on real-world datasets.
Classifying the classifier: dissecting the weight space of neural networks
Feb 13, 2020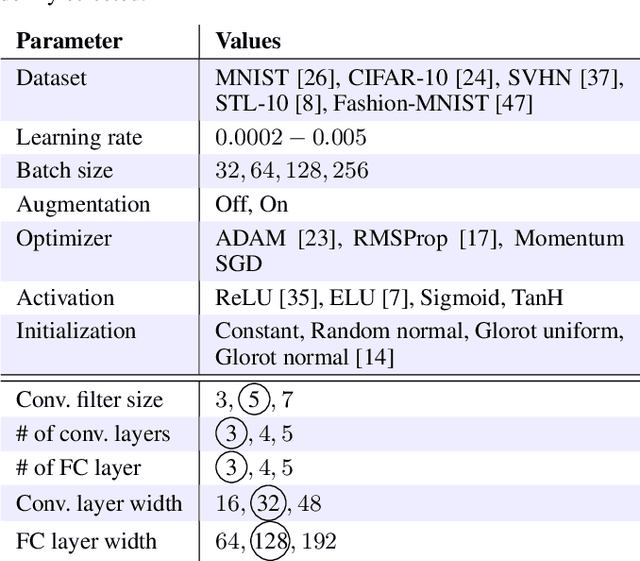
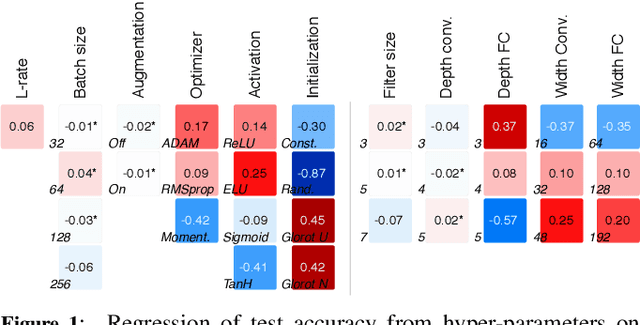
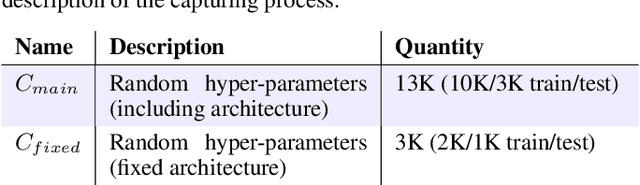
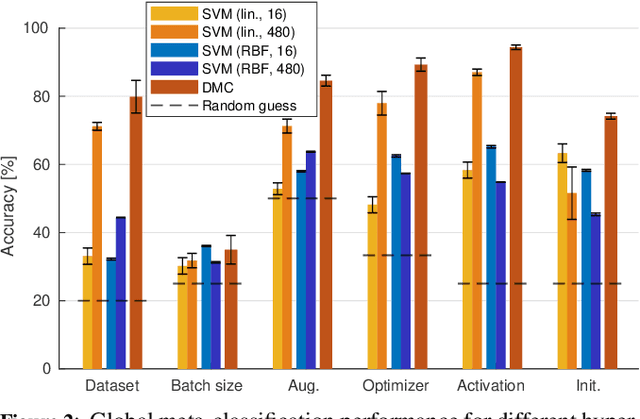
This paper presents an empirical study on the weights of neural networks, where we interpret each model as a point in a high-dimensional space -- the neural weight space. To explore the complex structure of this space, we sample from a diverse selection of training variations (dataset, optimization procedure, architecture, etc.) of neural network classifiers, and train a large number of models to represent the weight space. Then, we use a machine learning approach for analyzing and extracting information from this space. Most centrally, we train a number of novel deep meta-classifiers with the objective of classifying different properties of the training setup by identifying their footprints in the weight space. Thus, the meta-classifiers probe for patterns induced by hyper-parameters, so that we can quantify how much, where, and when these are encoded through the optimization process. This provides a novel and complementary view for explainable AI, and we show how meta-classifiers can reveal a great deal of information about the training setup and optimization, by only considering a small subset of randomly selected consecutive weights. To promote further research on the weight space, we release the neural weight space (NWS) dataset -- a collection of 320K weight snapshots from 16K individually trained deep neural networks.
A Unified Framework for Multi-Sensor HDR Video Reconstruction
Aug 22, 2013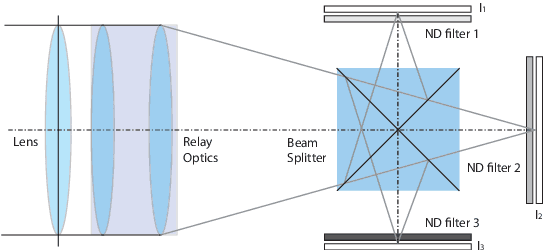
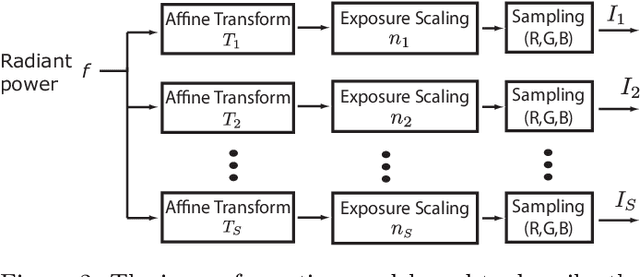
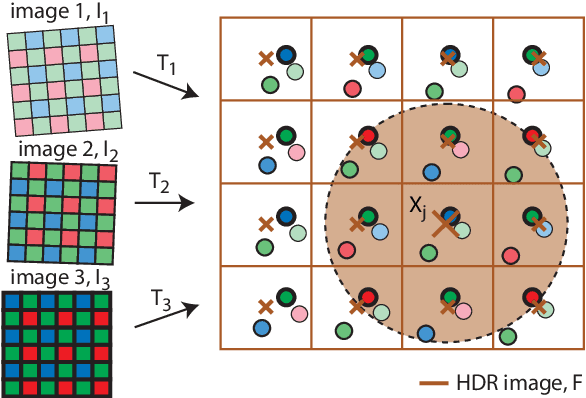
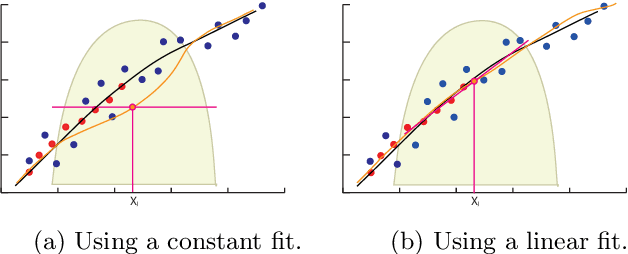
One of the most successful approaches to modern high quality HDR-video capture is to use camera setups with multiple sensors imaging the scene through a common optical system. However, such systems pose several challenges for HDR reconstruction algorithms. Previous reconstruction techniques have considered debayering, denoising, resampling (align- ment) and exposure fusion as separate problems. In contrast, in this paper we present a unifying approach, performing HDR assembly directly from raw sensor data. Our framework includes a camera noise model adapted to HDR video and an algorithm for spatially adaptive HDR reconstruction based on fitting of local polynomial approximations to observed sensor data. The method is easy to implement and allows reconstruction to an arbitrary resolution and output mapping. We present an implementation in CUDA and show real-time performance for an experimental 4 Mpixel multi-sensor HDR video system. We further show that our algorithm has clear advantages over existing methods, both in terms of flexibility and reconstruction quality.