 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploratory Visual Analysis for Increasing Data Readiness in Artificial Intelligence Projects
Sep 05, 2024



We present experiences and lessons learned from increasing data readiness of heterogeneous data for artificial intelligence projects using visual analysis methods. Increasing the data readiness level involves understanding both the data as well as the context in which it is used, which are challenges well suitable to visual analysis. For this purpose, we contribute a mapping between data readiness aspects and visual analysis techniques suitable for different data types. We use the defined mapping to increase data readiness levels in use cases involving time-varying data, including numerical, categorical, and text. In addition to the mapping, we extend the data readiness concept to better take aspects of the task and solution into account and explicitly address distribution shifts during data collection time. We report on our experiences in using the presented visual analysis techniques to aid future artificial intelligence projects in raising the data readiness level.
Neural Activation Patterns (NAPs): Visual Explainability of Learned Concepts
Jun 20, 2022
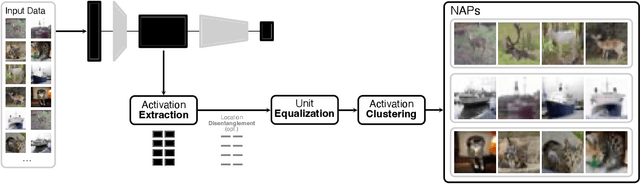
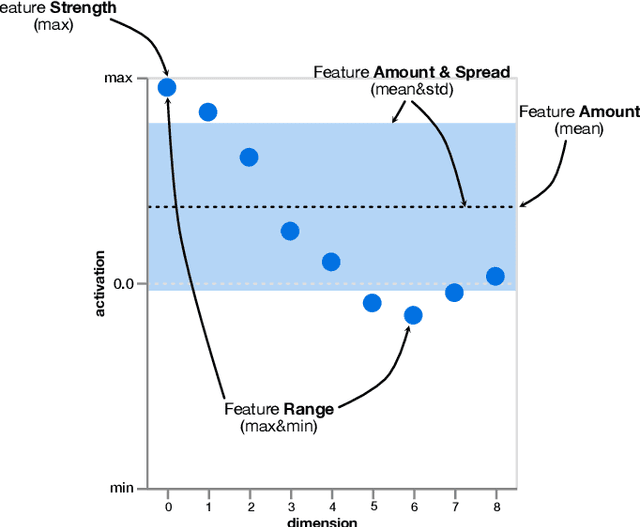
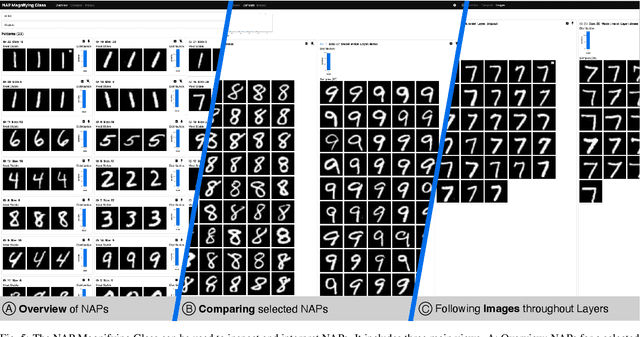
A key to deciphering the inner workings of neural networks is understanding what a model has learned. Promising methods for discovering learned features are based on analyzing activation values, whereby current techniques focus on analyzing high activation values to reveal interesting features on a neuron level. However, analyzing high activation values limits layer-level concept discovery. We present a method that instead takes into account the entire activation distribution. By extracting similar activation profiles within the high-dimensional activation space of a neural network layer, we find groups of inputs that are treated similarly. These input groups represent neural activation patterns (NAPs) and can be used to visualize and interpret learned layer concepts. We release a framework with which NAPs can be extracted from pre-trained models and provide a visual introspection tool that can be used to analyze NAPs. We tested our method with a variety of networks and show how it complements existing methods for analyzing neural network activation values.
Classifying the classifier: dissecting the weight space of neural networks
Feb 13, 2020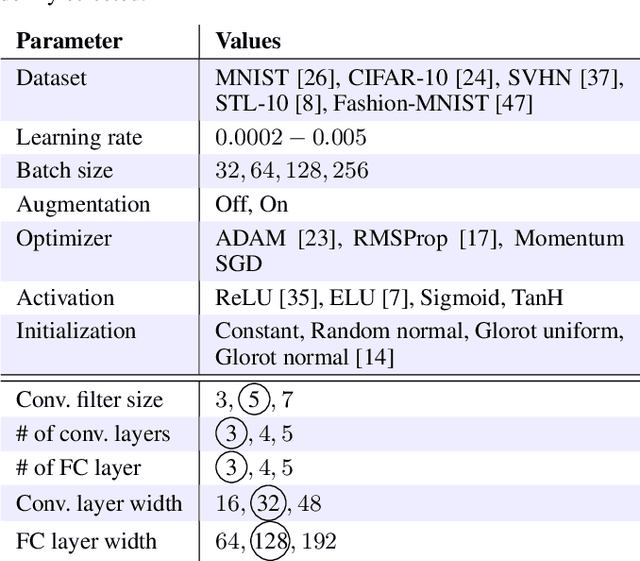
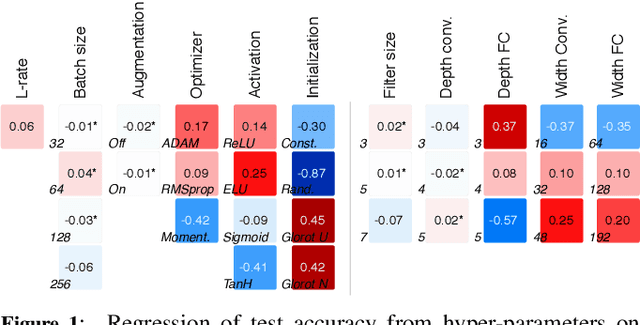
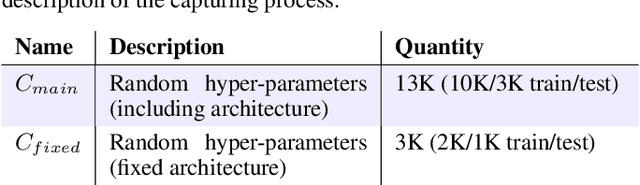
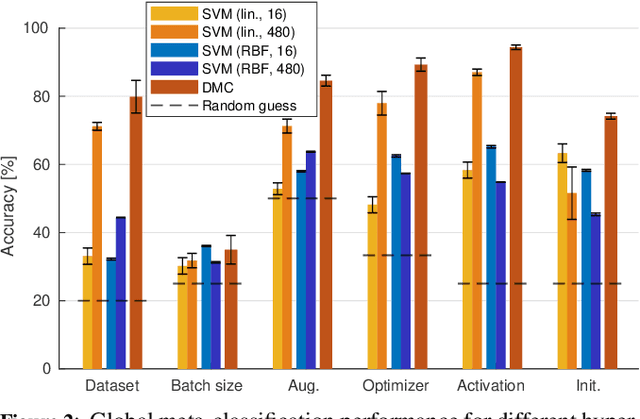
This paper presents an empirical study on the weights of neural networks, where we interpret each model as a point in a high-dimensional space -- the neural weight space. To explore the complex structure of this space, we sample from a diverse selection of training variations (dataset, optimization procedure, architecture, etc.) of neural network classifiers, and train a large number of models to represent the weight space. Then, we use a machine learning approach for analyzing and extracting information from this space. Most centrally, we train a number of novel deep meta-classifiers with the objective of classifying different properties of the training setup by identifying their footprints in the weight space. Thus, the meta-classifiers probe for patterns induced by hyper-parameters, so that we can quantify how much, where, and when these are encoded through the optimization process. This provides a novel and complementary view for explainable AI, and we show how meta-classifiers can reveal a great deal of information about the training setup and optimization, by only considering a small subset of randomly selected consecutive weights. To promote further research on the weight space, we release the neural weight space (NWS) dataset -- a collection of 320K weight snapshots from 16K individually trained deep neural networks.