 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Activation Patterns (NAPs): Visual Explainability of Learned Concepts
Paper and Code
Jun 20, 2022
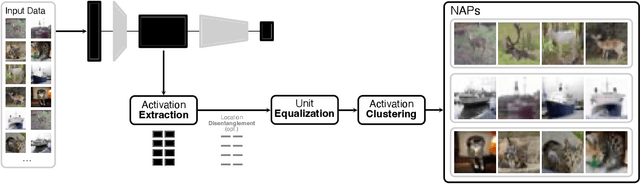
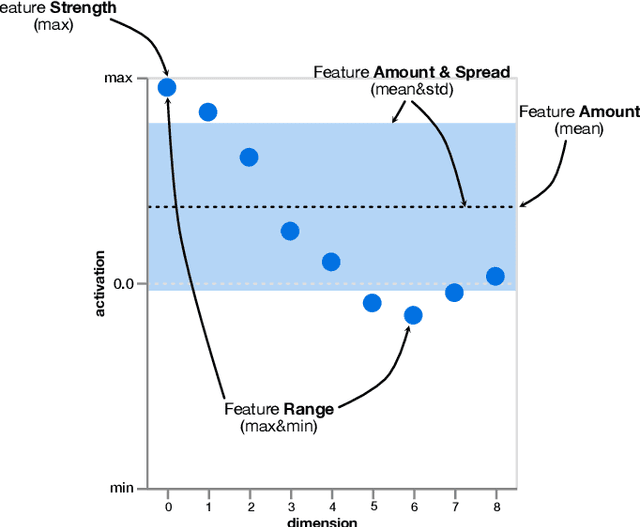
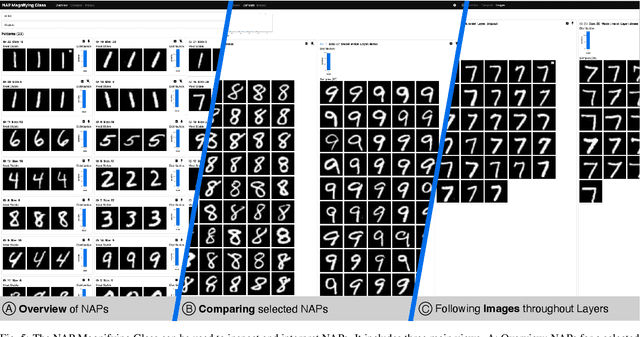
A key to deciphering the inner workings of neural networks is understanding what a model has learned. Promising methods for discovering learned features are based on analyzing activation values, whereby current techniques focus on analyzing high activation values to reveal interesting features on a neuron level. However, analyzing high activation values limits layer-level concept discovery. We present a method that instead takes into account the entire activation distribution. By extracting similar activation profiles within the high-dimensional activation space of a neural network layer, we find groups of inputs that are treated similarly. These input groups represent neural activation patterns (NAPs) and can be used to visualize and interpret learned layer concepts. We release a framework with which NAPs can be extracted from pre-trained models and provide a visual introspection tool that can be used to analyze NAPs. We tested our method with a variety of networks and show how it complements existing methods for analyzing neural network activation values.