 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti UAVs Preflight Planning in a Shared and Dynamic Airspace
Feb 12, 2026Preflight planning for large-scale Unmanned Aerial Vehicle (UAV) fleets in dynamic, shared airspace presents significant challenges, including temporal No-Fly Zones (NFZs), heterogeneous vehicle profiles, and strict delivery deadlines. While Multi-Agent Path Finding (MAPF) provides a formal framework, existing methods often lack the scalability and flexibility required for real-world Unmanned Traffic Management (UTM). We propose DTAPP-IICR: a Delivery-Time Aware Prioritized Planning method with Incremental and Iterative Conflict Resolution. Our framework first generates an initial solution by prioritizing missions based on urgency. Secondly, it computes roundtrip trajectories using SFIPP-ST, a novel 4D single-agent planner (Safe Flight Interval Path Planning with Soft and Temporal Constraints). SFIPP-ST handles heterogeneous UAVs, strictly enforces temporal NFZs, and models inter-agent conflicts as soft constraints. Subsequently, an iterative Large Neighborhood Search, guided by a geometric conflict graph, efficiently resolves any residual conflicts. A completeness-preserving directional pruning technique further accelerates the 3D search. On benchmarks with temporal NFZs, DTAPP-IICR achieves near-100% success with fleets of up to 1,000 UAVs and gains up to 50% runtime reduction from pruning, outperforming batch Enhanced Conflict-Based Search in the UTM context. Scaling successfully in realistic city-scale operations where other priority-based methods fail even at moderate deployments, DTAPP-IICR is positioned as a practical and scalable solution for preflight planning in dense, dynamic urban airspace.
Enhancing Time Series Forecasting with Fuzzy Attention-Integrated Transformers
Mar 31, 2025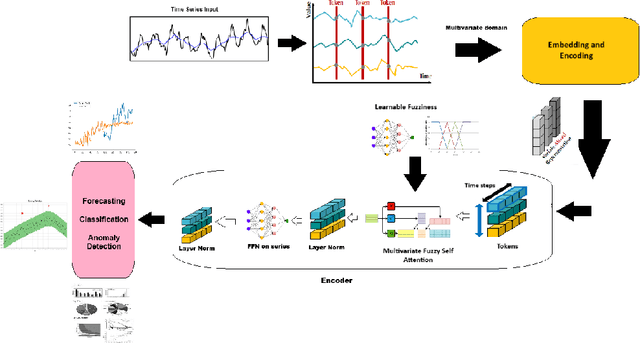
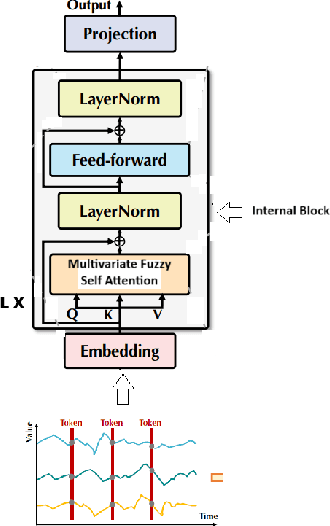
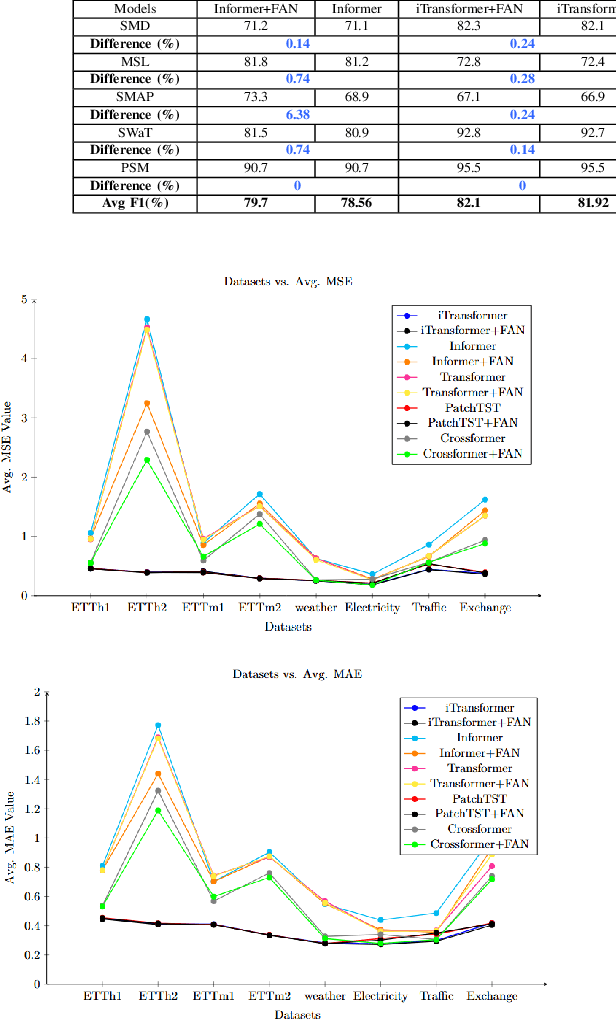
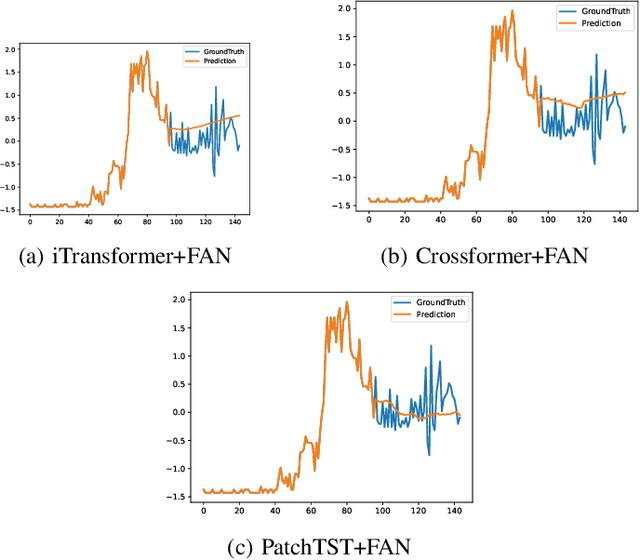
This paper introduces FANTF (Fuzzy Attention Network-Based Transformers), a novel approach that integrates fuzzy logic with existing transformer architectures to advance time series forecasting, classification, and anomaly detection tasks. FANTF leverages a proposed fuzzy attention mechanism incorporating fuzzy membership functions to handle uncertainty and imprecision in noisy and ambiguous time series data. The FANTF approach enhances its ability to capture complex temporal dependencies and multivariate relationships by embedding fuzzy logic principles into the self-attention module of the existing transformer's architecture. The framework combines fuzzy-enhanced attention with a set of benchmark existing transformer-based architectures to provide efficient predictions, classification and anomaly detection. Specifically, FANTF generates learnable fuzziness attention scores that highlight the relative importance of temporal features and data points, offering insights into its decision-making process. Experimental evaluatios on some real-world datasets reveal that FANTF significantly enhances the performance of forecasting, classification, and anomaly detection tasks over traditional transformer-based models.
Integrating Quantum-Classical Attention in Patch Transformers for Enhanced Time Series Forecasting
Mar 31, 2025
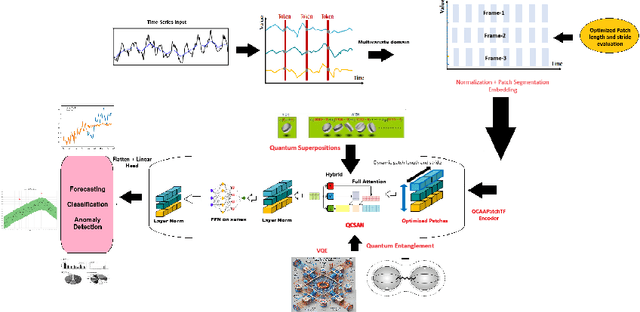
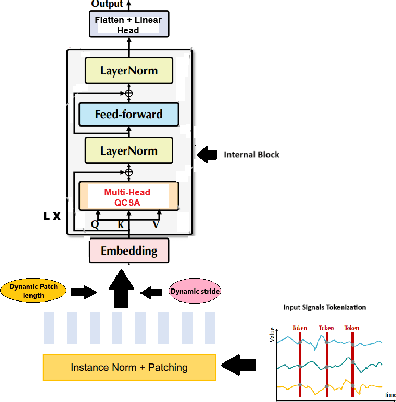
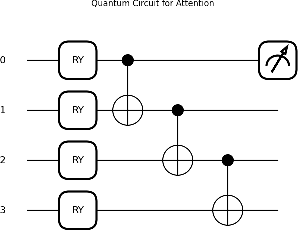
QCAAPatchTF is a quantum attention network integrated with an advanced patch-based transformer, designed for multivariate time series forecasting, classification, and anomaly detection. Leveraging quantum superpositions, entanglement, and variational quantum eigensolver principles, the model introduces a quantum-classical hybrid self-attention mechanism to capture multivariate correlations across time points. For multivariate long-term time series, the quantum self-attention mechanism can reduce computational complexity while maintaining temporal relationships. It then applies the quantum-classical hybrid self-attention mechanism alongside a feed-forward network in the encoder stage of the advanced patch-based transformer. While the feed-forward network learns nonlinear representations for each variable frame, the quantum self-attention mechanism processes individual series to enhance multivariate relationships. The advanced patch-based transformer computes the optimized patch length by dividing the sequence length into a fixed number of patches instead of using an arbitrary set of values. The stride is then set to half of the patch length to ensure efficient overlapping representations while maintaining temporal continuity. QCAAPatchTF achieves state-of-the-art performance in both long-term and short-term forecasting, classification, and anomaly detection tasks, demonstrating state-of-the-art accuracy and efficiency on complex real-world datasets.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
EDformer: Embedded Decomposition Transformer for Interpretable Multivariate Time Series Predictions
Dec 16, 2024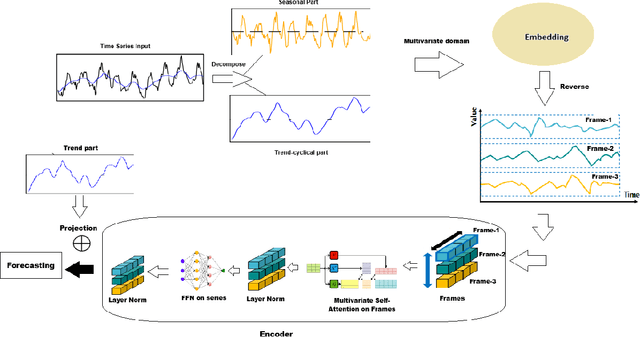
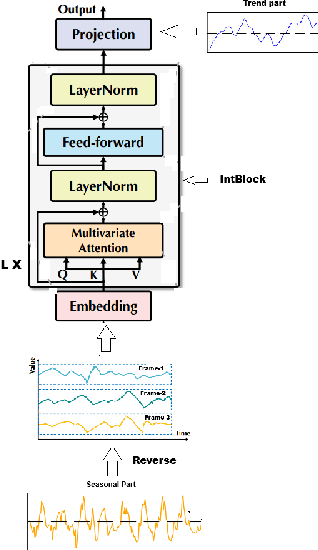
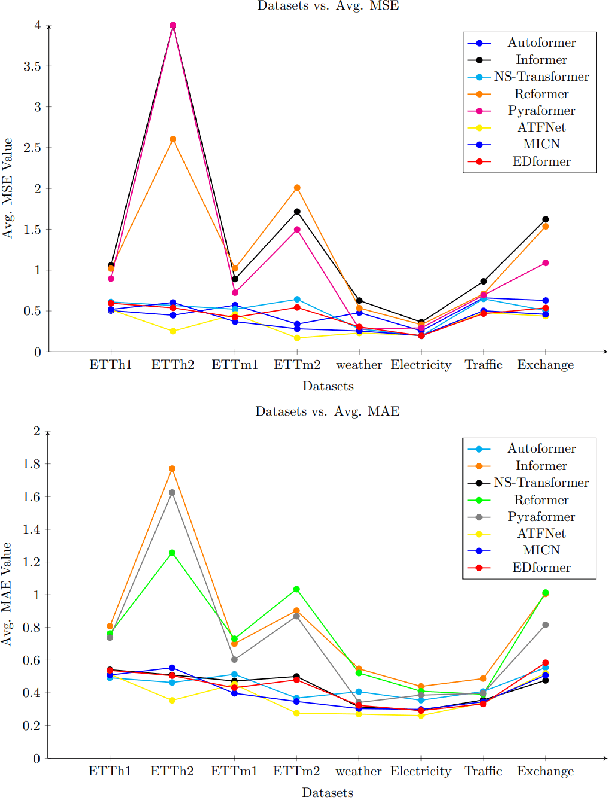
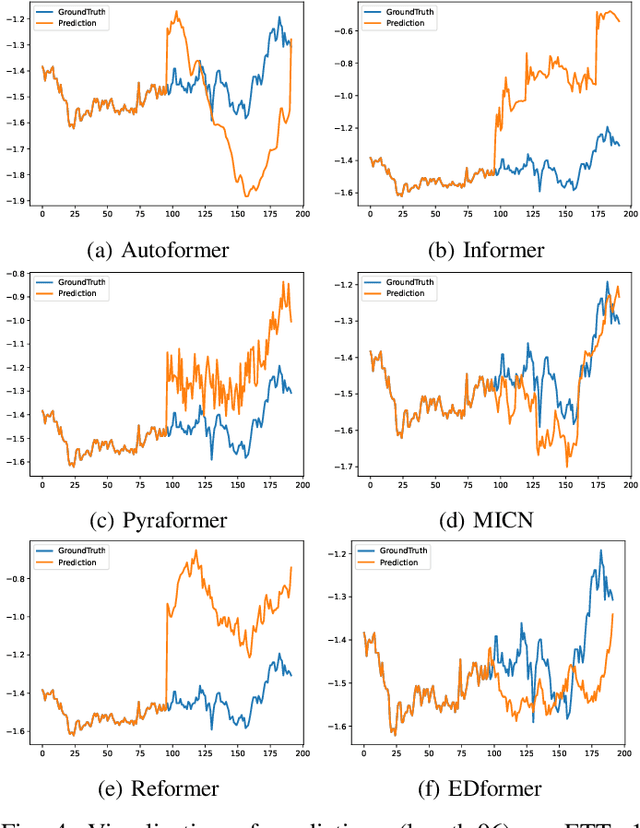
Time series forecasting is a crucial challenge with significant applications in areas such as weather prediction, stock market analysis, and scientific simulations. This paper introduces an embedded decomposed transformer, 'EDformer', for multivariate time series forecasting tasks. Without altering the fundamental elements, we reuse the Transformer architecture and consider the capable functions of its constituent parts in this work. Edformer first decomposes the input multivariate signal into seasonal and trend components. Next, the prominent multivariate seasonal component is reconstructed across the reverse dimensions, followed by applying the attention mechanism and feed-forward network in the encoder stage. In particular, the feed-forward network is used for each variable frame to learn nonlinear representations, while the attention mechanism uses the time points of individual seasonal series embedded within variate frames to capture multivariate correlations. Therefore, the trend signal is added with projection and performs the final forecasting. The EDformer model obtains state-of-the-art predicting results in terms of accuracy and efficiency on complex real-world time series datasets. This paper also addresses model explainability techniques to provide insights into how the model makes its predictions and why specific features or time steps are important, enhancing the interpretability and trustworthiness of the forecasting results.
Fair4Free: Generating High-fidelity Fair Synthetic Samples using Data Free Distillation
Oct 02, 2024


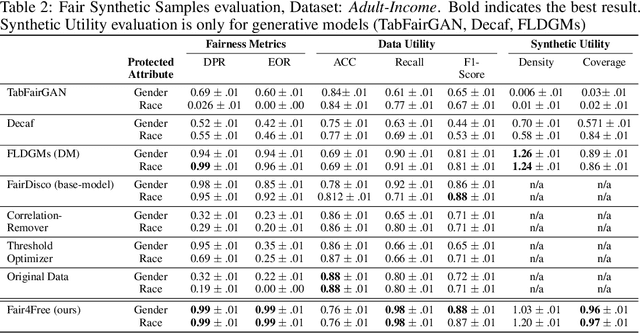
This work presents Fair4Free, a novel generative model to generate synthetic fair data using data-free distillation in the latent space. Fair4Free can work on the situation when the data is private or inaccessible. In our approach, we first train a teacher model to create fair representation and then distil the knowledge to a student model (using a smaller architecture). The process of distilling the student model is data-free, i.e. the student model does not have access to the training dataset while distilling. After the distillation, we use the distilled model to generate fair synthetic samples. Our extensive experiments show that our synthetic samples outperform state-of-the-art models in all three criteria (fairness, utility and synthetic quality) with a performance increase of 5% for fairness, 8% for utility and 12% in synthetic quality for both tabular and image datasets.
Exploratory Visual Analysis for Increasing Data Readiness in Artificial Intelligence Projects
Sep 05, 2024



We present experiences and lessons learned from increasing data readiness of heterogeneous data for artificial intelligence projects using visual analysis methods. Increasing the data readiness level involves understanding both the data as well as the context in which it is used, which are challenges well suitable to visual analysis. For this purpose, we contribute a mapping between data readiness aspects and visual analysis techniques suitable for different data types. We use the defined mapping to increase data readiness levels in use cases involving time-varying data, including numerical, categorical, and text. In addition to the mapping, we extend the data readiness concept to better take aspects of the task and solution into account and explicitly address distribution shifts during data collection time. We report on our experiences in using the presented visual analysis techniques to aid future artificial intelligence projects in raising the data readiness level.
Generating Synthetic Fair Syntax-agnostic Data by Learning and Distilling Fair Representation
Aug 20, 2024



Data Fairness is a crucial topic due to the recent wide usage of AI powered applications. Most of the real-world data is filled with human or machine biases and when those data are being used to train AI models, there is a chance that the model will reflect the bias in the training data. Existing bias-mitigating generative methods based on GANs, Diffusion models need in-processing fairness objectives and fail to consider computational overhead while choosing computationally-heavy architectures, which may lead to high computational demands, instability and poor optimization performance. To mitigate this issue, in this work, we present a fair data generation technique based on knowledge distillation, where we use a small architecture to distill the fair representation in the latent space. The idea of fair latent space distillation enables more flexible and stable training of Fair Generative Models (FGMs). We first learn a syntax-agnostic (for any data type) fair representation of the data, followed by distillation in the latent space into a smaller model. After distillation, we use the distilled fair latent space to generate high-fidelity fair synthetic data. While distilling, we employ quality loss (for fair distillation) and utility loss (for data utility) to ensure that the fairness and data utility characteristics remain in the distilled latent space. Our approaches show a 5%, 5% and 10% rise in performance in fairness, synthetic sample quality and data utility, respectively, than the state-of-the-art fair generative model.
Improving Relational Database Interactions with Large Language Models: Column Descriptions and Their Impact on Text-to-SQL Performance
Aug 08, 2024



Relational databases often suffer from uninformative descriptors of table contents, such as ambiguous columns and hard-to-interpret values, impacting both human users and Text-to-SQL models. This paper explores the use of large language models (LLMs) to generate informative column descriptions as a semantic layer for relational databases. Using the BIRD-Bench development set, we created \textsc{ColSQL}, a dataset with gold-standard column descriptions generated and refined by LLMs and human annotators. We evaluated several instruction-tuned models, finding that GPT-4o and Command R+ excelled in generating high-quality descriptions. Additionally, we applied an LLM-as-a-judge to evaluate model performance. Although this method does not align well with human evaluations, we included it to explore its potential and to identify areas for improvement. More work is needed to improve the reliability of automatic evaluations for this task. We also find that detailed column descriptions significantly improve Text-to-SQL execution accuracy, especially when columns are uninformative. This study establishes LLMs as effective tools for generating detailed metadata, enhancing the usability of relational databases.
FairX: A comprehensive benchmarking tool for model analysis using fairness, utility, and explainability
Jun 20, 2024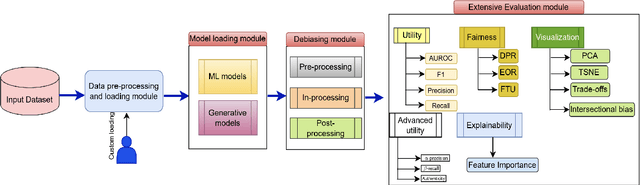

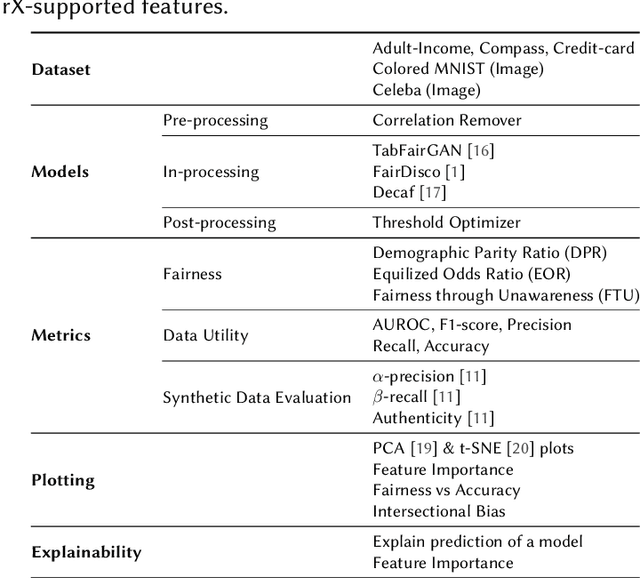
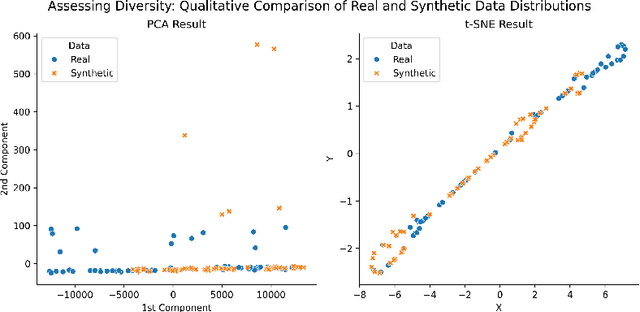
We present FairX, an open-source Python-based benchmarking tool designed for the comprehensive analysis of models under the umbrella of fairness, utility, and eXplainability (XAI). FairX enables users to train benchmarking bias-removal models and evaluate their fairness using a wide array of fairness metrics, data utility metrics, and generate explanations for model predictions, all within a unified framework. Existing benchmarking tools do not have the way to evaluate synthetic data generated from fair generative models, also they do not have the support for training fair generative models either. In FairX, we add fair generative models in the collection of our fair-model library (pre-processing, in-processing, post-processing) and evaluation metrics for evaluating the quality of synthetic fair data. This version of FairX supports both tabular and image datasets. It also allows users to provide their own custom datasets. The open-source FairX benchmarking package is publicly available at https://github.com/fahim-sikder/FairX.