 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Relational Database Interactions with Large Language Models: Column Descriptions and Their Impact on Text-to-SQL Performance
Aug 08, 2024



Relational databases often suffer from uninformative descriptors of table contents, such as ambiguous columns and hard-to-interpret values, impacting both human users and Text-to-SQL models. This paper explores the use of large language models (LLMs) to generate informative column descriptions as a semantic layer for relational databases. Using the BIRD-Bench development set, we created \textsc{ColSQL}, a dataset with gold-standard column descriptions generated and refined by LLMs and human annotators. We evaluated several instruction-tuned models, finding that GPT-4o and Command R+ excelled in generating high-quality descriptions. Additionally, we applied an LLM-as-a-judge to evaluate model performance. Although this method does not align well with human evaluations, we included it to explore its potential and to identify areas for improvement. More work is needed to improve the reliability of automatic evaluations for this task. We also find that detailed column descriptions significantly improve Text-to-SQL execution accuracy, especially when columns are uninformative. This study establishes LLMs as effective tools for generating detailed metadata, enhancing the usability of relational databases.
Understanding the Effects of Noise in Text-to-SQL: An Examination of the BIRD-Bench Benchmark
Feb 20, 2024Text-to-SQL, which involves translating natural language into Structured Query Language (SQL), is crucial for enabling broad access to structured databases without expert knowledge. However, designing models for such tasks is challenging due to numerous factors, including the presence of 'noise,' such as ambiguous questions and syntactical errors. This study provides an in-depth analysis of the distribution and types of noise in the widely used BIRD-Bench benchmark and the impact of noise on models. While BIRD-Bench was created to model dirty and noisy database values, it was not created to contain noise and errors in the questions and gold queries. We found that noise in questions and gold queries are prevalent in the dataset, with varying amounts across domains, and with an uneven distribution between noise types. The presence of incorrect gold SQL queries, which then generate incorrect gold answers, has a significant impact on the benchmark's reliability. Surprisingly, when evaluating models on corrected SQL queries, zero-shot baselines surpassed the performance of state-of-the-art prompting methods. We conclude that informative noise labels and reliable benchmarks are crucial to developing new Text-to-SQL methods that can handle varying types of noise.
How Reliable Are Automatic Evaluation Methods for Instruction-Tuned LLMs?
Feb 16, 2024Work on instruction-tuned Large Language Models (LLMs) has used automatic methods based on text overlap and LLM judgments as cost-effective alternatives to human evaluation. In this paper, we study the reliability of such methods across a broad range of tasks and in a cross-lingual setting. In contrast to previous findings, we observe considerable variability in correlations between automatic methods and human evaluators when scores are differentiated by task type. Specifically, the widely-used ROUGE-L metric strongly correlates with human judgments for short-answer English tasks but is unreliable in free-form generation tasks and cross-lingual transfer. The effectiveness of GPT-4 as an evaluator depends on including reference answers when prompting for assessments, which can lead to overly strict evaluations in free-form generation tasks. In summary, we find that, while automatic evaluation methods can approximate human judgements under specific conditions, their reliability is highly context-dependent. Our findings enhance the understanding of how automatic methods should be applied and interpreted when developing and evaluating instruction-tuned LLMs.
The Impact of Language Adapters in Cross-Lingual Transfer for NLU
Jan 31, 2024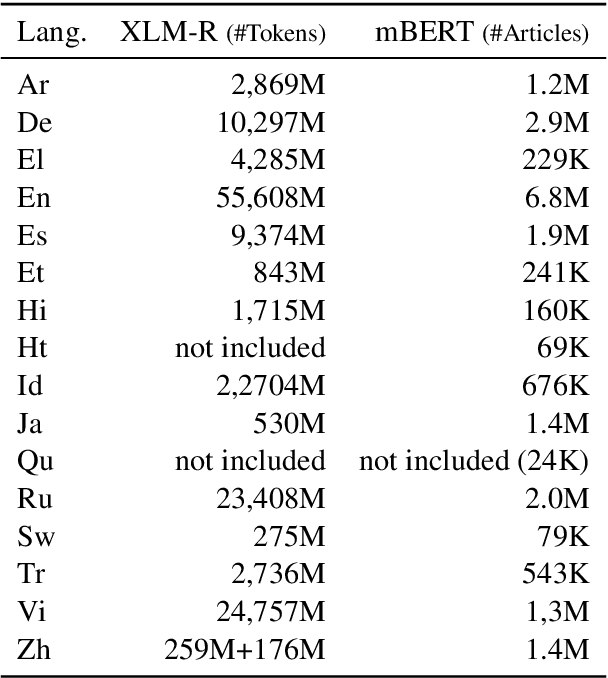
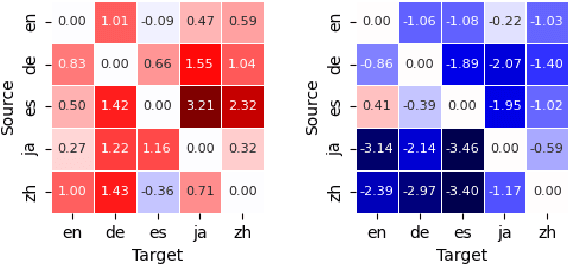

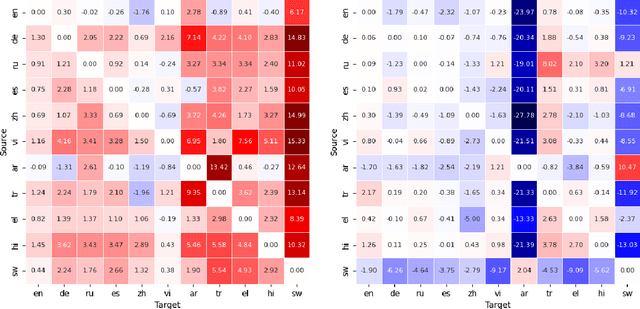
Modular deep learning has been proposed for the efficient adaption of pre-trained models to new tasks, domains and languages. In particular, combining language adapters with task adapters has shown potential where no supervised data exists for a language. In this paper, we explore the role of language adapters in zero-shot cross-lingual transfer for natural language understanding (NLU) benchmarks. We study the effect of including a target-language adapter in detailed ablation studies with two multilingual models and three multilingual datasets. Our results show that the effect of target-language adapters is highly inconsistent across tasks, languages and models. Retaining the source-language adapter instead often leads to an equivalent, and sometimes to a better, performance. Removing the language adapter after training has only a weak negative effect, indicating that the language adapters do not have a strong impact on the predictions.