 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreferences for Idiomatic Language are Acquired Slowly -- and Forgotten Quickly: A Case Study on Swedish
Feb 03, 2026In this study, we investigate how language models develop preferences for \textit{idiomatic} as compared to \textit{linguistically acceptable} Swedish, both during pretraining and when adapting a model from English to Swedish. To do so, we train models on Swedish from scratch and by fine-tuning English-pretrained models, probing their preferences at various checkpoints using minimal pairs that differ in linguistic acceptability or idiomaticity. For linguistic acceptability, we adapt existing benchmarks into a minimal-pair format. To assess idiomaticity, we introduce two novel datasets: one contrasting conventionalized idioms with plausible variants, and another contrasting idiomatic Swedish with Translationese. Our findings suggest that idiomatic competence emerges more slowly than other linguistic abilities, including grammatical and lexical correctness. While longer training yields diminishing returns for most tasks, idiom-related performance continues to improve, particularly in the largest model tested (8B). However, instruction tuning on data machine-translated from English -- the common approach for languages with little or no native instruction data -- causes models to rapidly lose their preference for idiomatic language.
Grow Up and Merge: Scaling Strategies for Efficient Language Adaptation
Dec 11, 2025Achieving high-performing language models which include medium- and lower-resource languages remains a challenge. Massively multilingual models still underperform compared to language-specific adaptations, especially at smaller model scales. In this work, we investigate scaling as an efficient strategy for adapting pretrained models to new target languages. Through comprehensive scaling ablations with approximately FLOP-matched models, we test whether upscaling an English base model enables more effective and resource-efficient adaptation than standard continued pretraining. We find that, once exposed to sufficient target-language data, larger upscaled models can match or surpass the performance of smaller models continually pretrained on much more data, demonstrating the benefits of scaling for data efficiency. Scaling also helps preserve the base model's capabilities in English, thus reducing catastrophic forgetting. Finally, we explore whether such scaled, language-specific models can be merged to construct modular and flexible multilingual systems. We find that while merging remains less effective than joint multilingual training, upscaled merges perform better than smaller ones. We observe large performance differences across merging methods, suggesting potential for improvement through merging approaches specialized for language-level integration.
Family Matters: Language Transfer and Merging for Adapting Small LLMs to Faroese
Oct 01, 2025We investigate how to adapt small, efficient LLMs to Faroese, a low-resource North Germanic language. Starting from English models, we continue pre-training on related Scandinavian languages, either individually or combined via merging, before fine-tuning on Faroese. We compare full fine-tuning with parameter-efficient tuning using LoRA, evaluating their impact on both linguistic accuracy and text comprehension. Due to the lack of existing Faroese evaluation data, we construct two new minimal-pair benchmarks from adapted and newly collected datasets and complement them with human evaluations by Faroese linguists. Our results demonstrate that transfer from related languages is crucial, though the optimal source language depends on the task: Icelandic enhances linguistic accuracy, whereas Danish boosts comprehension. Similarly, the choice between full fine-tuning and LoRA is task-dependent: LoRA improves linguistic acceptability and slightly increases human evaluation scores on the base model, while full fine-tuning yields stronger comprehension performance and better preserves model capabilities during downstream fine-tuning.
How to Tune a Multilingual Encoder Model for Germanic Languages: A Study of PEFT, Full Fine-Tuning, and Language Adapters
Jan 10, 2025This paper investigates the optimal use of the multilingual encoder model mDeBERTa for tasks in three Germanic languages -- German, Swedish, and Icelandic -- representing varying levels of presence and likely data quality in mDeBERTas pre-training data. We compare full fine-tuning with the parameter-efficient fine-tuning (PEFT) methods LoRA and Pfeiffer bottleneck adapters, finding that PEFT is more effective for the higher-resource language, German. However, results for Swedish and Icelandic are less consistent. We also observe differences between tasks: While PEFT tends to work better for question answering, full fine-tuning is preferable for named entity recognition. Inspired by previous research on modular approaches that combine task and language adapters, we evaluate the impact of adding PEFT modules trained on unstructured text, finding that this approach is not beneficial.
Train More Parameters But Mind Their Placement: Insights into Language Adaptation with PEFT
Dec 17, 2024
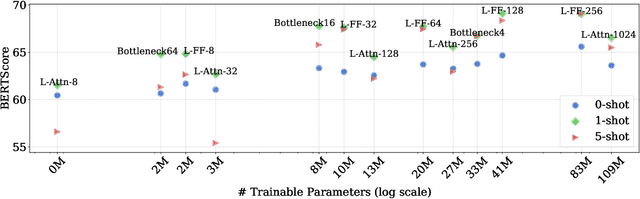
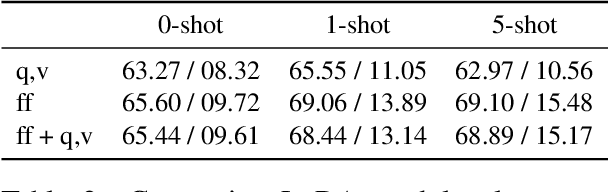

Smaller LLMs still face significant challenges even in medium-resourced languages, particularly when it comes to language-specific knowledge -- a problem not easily resolved with machine-translated data. In this case study on Icelandic, we aim to enhance the generation performance of an LLM by specialising it using unstructured text corpora. A key focus is on preventing interference with the models' capabilities of handling longer context during this adaptation. Through ablation studies using various parameter-efficient fine-tuning (PEFT) methods and setups, we find that increasing the number of trainable parameters leads to better and more robust language adaptation. LoRAs placed in the feed-forward layers and bottleneck adapters show promising results with sufficient parameters, while prefix tuning and (IA)3 are not suitable. Although improvements are consistent in 0-shot summarisation, some adapted models struggle with longer context lengths, an issue that can be mitigated by adapting only the final layers.
Properties and Challenges of LLM-Generated Explanations
Feb 16, 2024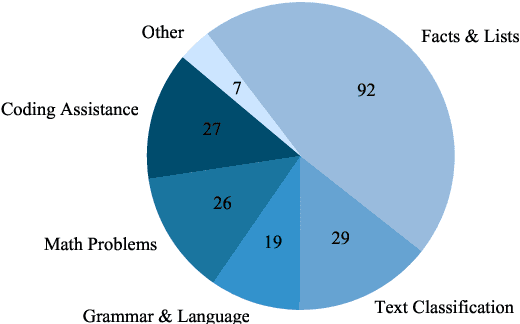
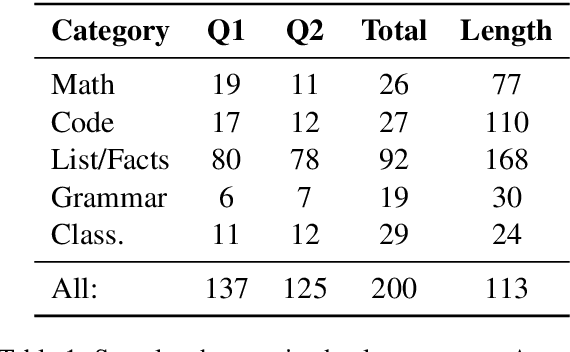
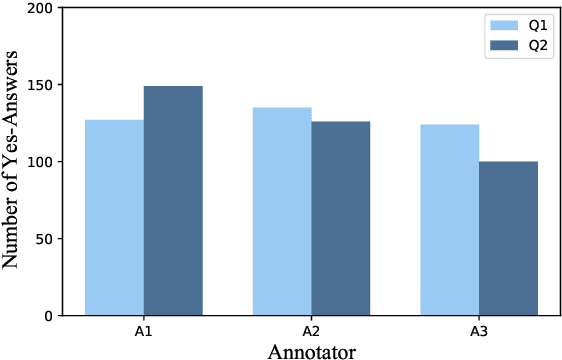
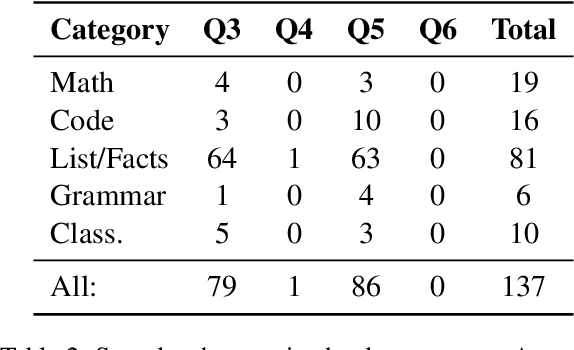
The self-rationalising capabilities of large language models (LLMs) have been explored in restricted settings, using task/specific data sets. However, current LLMs do not (only) rely on specifically annotated data; nonetheless, they frequently explain their outputs. The properties of the generated explanations are influenced by the pre-training corpus and by the target data used for instruction fine-tuning. As the pre-training corpus includes a large amount of human-written explanations "in the wild", we hypothesise that LLMs adopt common properties of human explanations. By analysing the outputs for a multi-domain instruction fine-tuning data set, we find that generated explanations show selectivity and contain illustrative elements, but less frequently are subjective or misleading. We discuss reasons and consequences of the properties' presence or absence. In particular, we outline positive and negative implications depending on the goals and user groups of the self-rationalising system.
A Hypothesis-Driven Framework for the Analysis of Self-Rationalising Models
Feb 07, 2024The self-rationalising capabilities of LLMs are appealing because the generated explanations can give insights into the plausibility of the predictions. However, how faithful the explanations are to the predictions is questionable, raising the need to explore the patterns behind them further. To this end, we propose a hypothesis-driven statistical framework. We use a Bayesian network to implement a hypothesis about how a task (in our example, natural language inference) is solved, and its internal states are translated into natural language with templates. Those explanations are then compared to LLM-generated free-text explanations using automatic and human evaluations. This allows us to judge how similar the LLM's and the Bayesian network's decision processes are. We demonstrate the usage of our framework with an example hypothesis and two realisations in Bayesian networks. The resulting models do not exhibit a strong similarity to GPT-3.5. We discuss the implications of this as well as the framework's potential to approximate LLM decisions better in future work.
The Impact of Language Adapters in Cross-Lingual Transfer for NLU
Jan 31, 2024
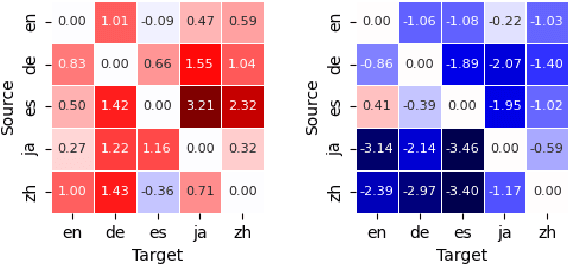

Modular deep learning has been proposed for the efficient adaption of pre-trained models to new tasks, domains and languages. In particular, combining language adapters with task adapters has shown potential where no supervised data exists for a language. In this paper, we explore the role of language adapters in zero-shot cross-lingual transfer for natural language understanding (NLU) benchmarks. We study the effect of including a target-language adapter in detailed ablation studies with two multilingual models and three multilingual datasets. Our results show that the effect of target-language adapters is highly inconsistent across tasks, languages and models. Retaining the source-language adapter instead often leads to an equivalent, and sometimes to a better, performance. Removing the language adapter after training has only a weak negative effect, indicating that the language adapters do not have a strong impact on the predictions.