 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrow Up and Merge: Scaling Strategies for Efficient Language Adaptation
Dec 11, 2025Achieving high-performing language models which include medium- and lower-resource languages remains a challenge. Massively multilingual models still underperform compared to language-specific adaptations, especially at smaller model scales. In this work, we investigate scaling as an efficient strategy for adapting pretrained models to new target languages. Through comprehensive scaling ablations with approximately FLOP-matched models, we test whether upscaling an English base model enables more effective and resource-efficient adaptation than standard continued pretraining. We find that, once exposed to sufficient target-language data, larger upscaled models can match or surpass the performance of smaller models continually pretrained on much more data, demonstrating the benefits of scaling for data efficiency. Scaling also helps preserve the base model's capabilities in English, thus reducing catastrophic forgetting. Finally, we explore whether such scaled, language-specific models can be merged to construct modular and flexible multilingual systems. We find that while merging remains less effective than joint multilingual training, upscaled merges perform better than smaller ones. We observe large performance differences across merging methods, suggesting potential for improvement through merging approaches specialized for language-level integration.
How to Tune a Multilingual Encoder Model for Germanic Languages: A Study of PEFT, Full Fine-Tuning, and Language Adapters
Jan 10, 2025This paper investigates the optimal use of the multilingual encoder model mDeBERTa for tasks in three Germanic languages -- German, Swedish, and Icelandic -- representing varying levels of presence and likely data quality in mDeBERTas pre-training data. We compare full fine-tuning with the parameter-efficient fine-tuning (PEFT) methods LoRA and Pfeiffer bottleneck adapters, finding that PEFT is more effective for the higher-resource language, German. However, results for Swedish and Icelandic are less consistent. We also observe differences between tasks: While PEFT tends to work better for question answering, full fine-tuning is preferable for named entity recognition. Inspired by previous research on modular approaches that combine task and language adapters, we evaluate the impact of adding PEFT modules trained on unstructured text, finding that this approach is not beneficial.
PerSpeechNorm: A Persian Toolkit for Speech Processing Normalization
Nov 01, 2021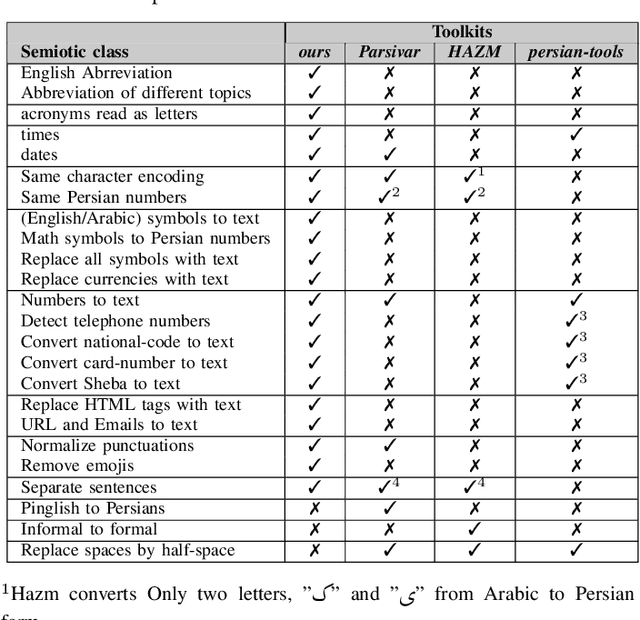

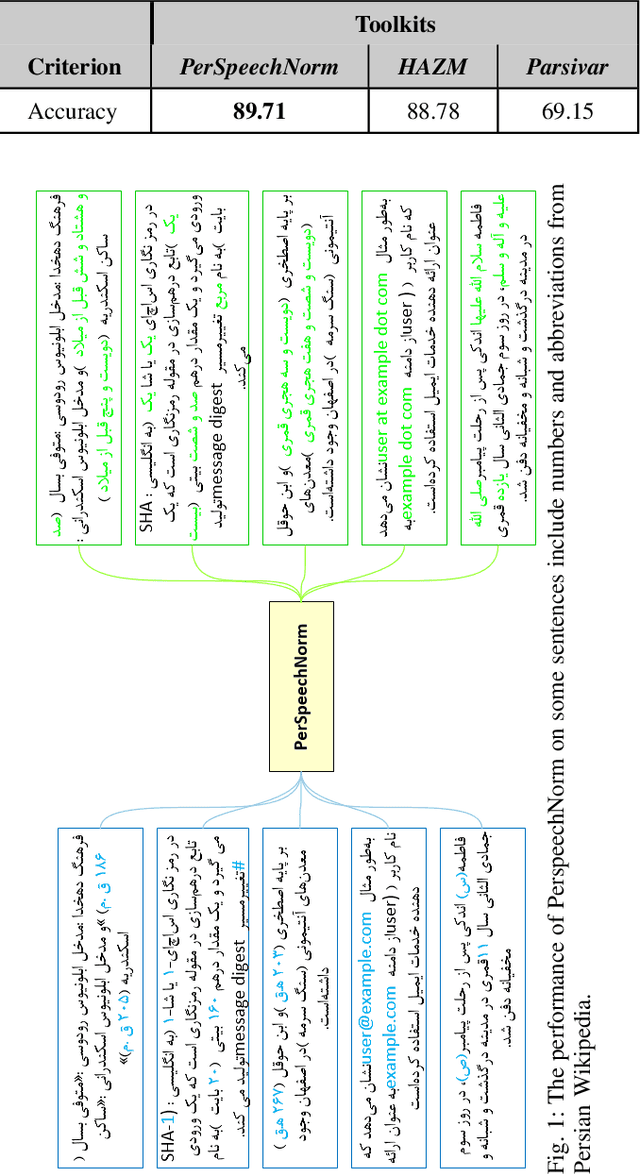
In general, speech processing models consist of a language model along with an acoustic model. Regardless of the language model's complexity and variants, three critical pre-processing steps are needed in language models: cleaning, normalization, and tokenization. Among mentioned steps, the normalization step is so essential to format unification in pure textual applications. However, for embedded language models in speech processing modules, normalization is not limited to format unification. Moreover, it has to convert each readable symbol, number, etc., to how they are pronounced. To the best of our knowledge, there is no Persian normalization toolkits for embedded language models in speech processing modules, So in this paper, we propose an open-source normalization toolkit for text processing in speech applications. Briefly, we consider different readable Persian text like symbols (common currencies, #, @, URL, etc.), numbers (date, time, phone number, national code, etc.), and so on. Comparison with other available Persian textual normalization tools indicates the superiority of the proposed method in speech processing. Also, comparing the model's performance for one of the proposed functions (sentence separation) with other common natural language libraries such as HAZM and Parsivar indicates the proper performance of the proposed method. Besides, its evaluation of some Persian Wikipedia data confirms the proper performance of the proposed method.