 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing One Sided Margin Loss for Solving Classification Problems in Deep Networks
Jun 02, 2022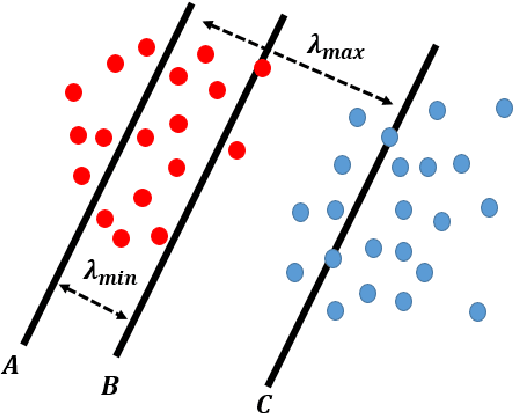
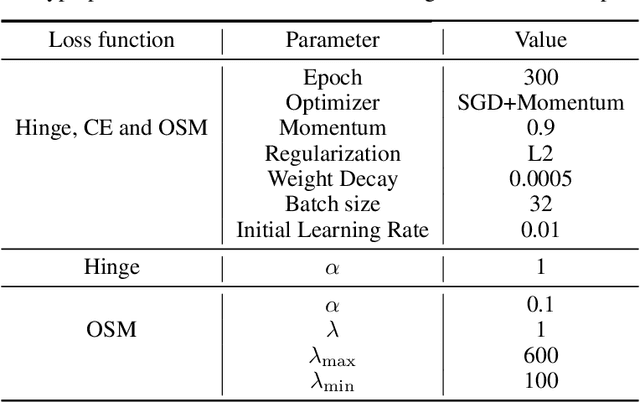
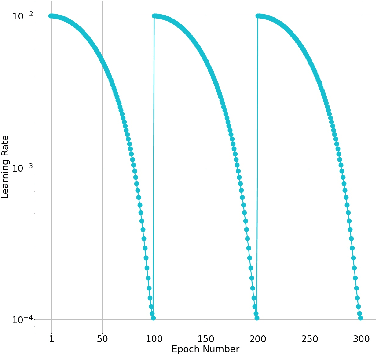
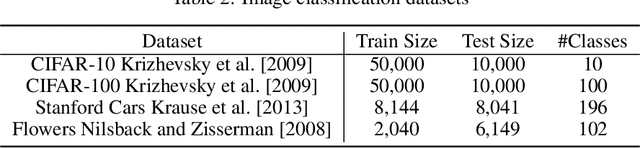
This paper introduces a new loss function, OSM (One-Sided Margin), to solve maximum-margin classification problems effectively. Unlike the hinge loss, in OSM the margin is explicitly determined with corresponding hyperparameters and then the classification problem is solved. In experiments, we observe that using OSM loss leads to faster training speeds and better accuracies than binary and categorical cross-entropy in several commonly used deep models for classification and optical character recognition problems. OSM has consistently shown better classification accuracies over cross-entropy and hinge losses for small to large neural networks. it has also led to a more efficient training procedure. We achieved state-of-the-art accuracies for small networks on several benchmark datasets of CIFAR10(98.82\%), CIFAR100(91.56\%), Flowers(98.04\%), Stanford Cars(93.91\%) with considerable improvements over other loss functions. Moreover, the accuracies are rather better than cross-entropy and hinge loss for large networks. Therefore, we strongly believe that OSM is a powerful alternative to hinge and cross-entropy losses to train deep neural networks on classification tasks.
PerSpeechNorm: A Persian Toolkit for Speech Processing Normalization
Nov 01, 2021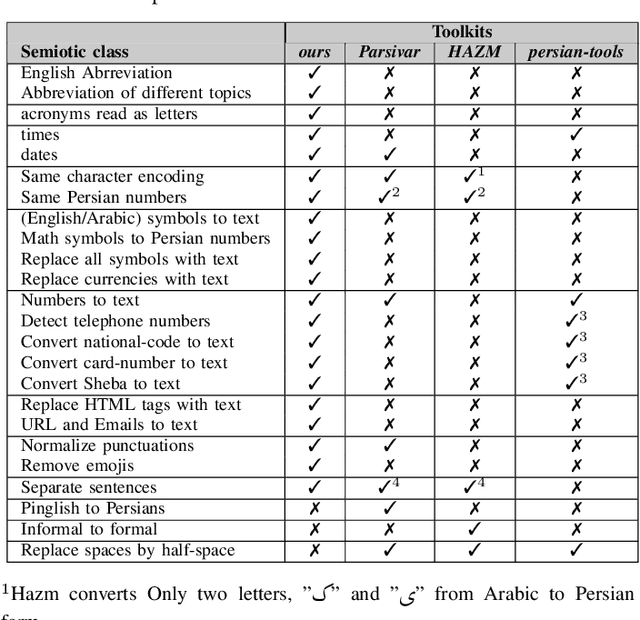

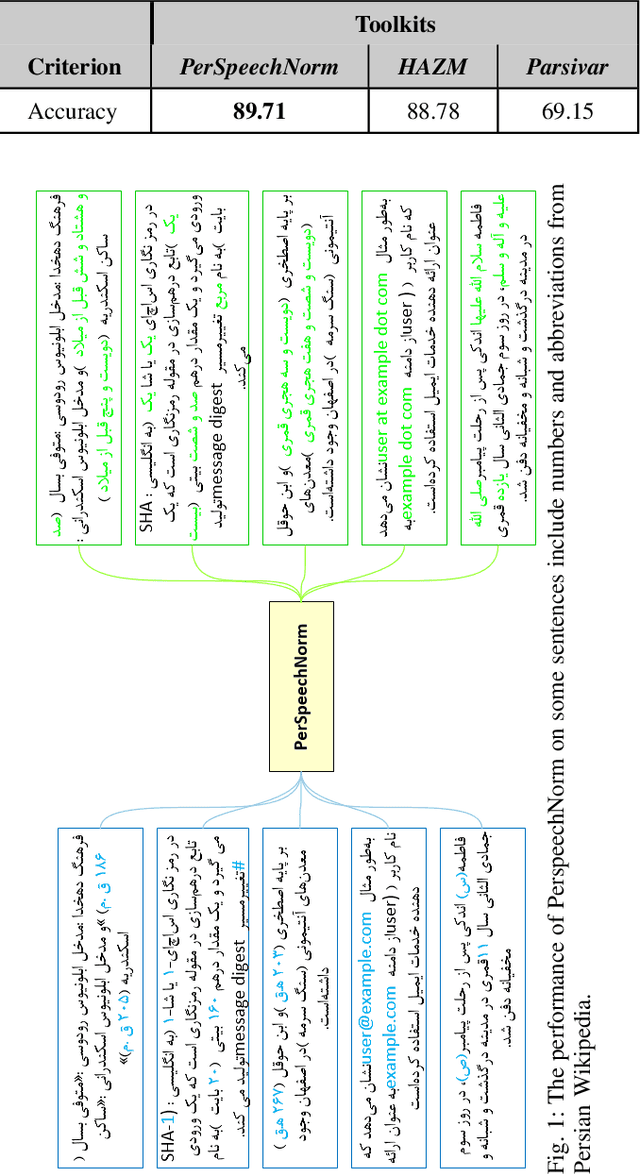
In general, speech processing models consist of a language model along with an acoustic model. Regardless of the language model's complexity and variants, three critical pre-processing steps are needed in language models: cleaning, normalization, and tokenization. Among mentioned steps, the normalization step is so essential to format unification in pure textual applications. However, for embedded language models in speech processing modules, normalization is not limited to format unification. Moreover, it has to convert each readable symbol, number, etc., to how they are pronounced. To the best of our knowledge, there is no Persian normalization toolkits for embedded language models in speech processing modules, So in this paper, we propose an open-source normalization toolkit for text processing in speech applications. Briefly, we consider different readable Persian text like symbols (common currencies, #, @, URL, etc.), numbers (date, time, phone number, national code, etc.), and so on. Comparison with other available Persian textual normalization tools indicates the superiority of the proposed method in speech processing. Also, comparing the model's performance for one of the proposed functions (sentence separation) with other common natural language libraries such as HAZM and Parsivar indicates the proper performance of the proposed method. Besides, its evaluation of some Persian Wikipedia data confirms the proper performance of the proposed method.