 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Temporally Localized Manipulations in Authentic Video Streams
Jun 05, 2026The rapid advancement of video editing and generative artificial intelligence technologies has made realistic video manipulation increasingly accessible. Although existing datasets have significantly advanced research in deepfake detection, object removal, and video inpainting, they do not adequately model scenarios in which a short manipulated segment is inserted into an otherwise authentic video and the original video continues afterward. In this study, we review representative datasets from the literature, analyze their characteristics, and discuss their limitations with respect to temporally localized realistic manipulation detection. Based on this analysis, we motivate the need for a new dataset specifically designed for authentic videos containing short and highly realistic manipulated intervals. Finally, we evaluate two complementary approaches on our custom-curated test set to establish an initial benchmark for this challenging scenario. The first employs a linear probe on DINOv3 features, assessed under three thresholding strategies. The second leverages DINOv3 features with a consecutive frame similarity-based method to detect temporal manipulation boundaries. Together, these experiments provide an initial benchmark for partially manipulated video detection and highlight the need for content-adaptive thresholding mechanisms. The dataset, code, and supplementary materials are publicly available at https://github.com/OkanUmur/temporally-localized-video-manipulation-detection.
Cross-Domain Generalization Limits of Vision Foundation Models in Facial Deepfake Detection
May 24, 2026The rapid evolution of generative models has enabled the creation of hyper-realistic facial deepfakes, exposing a critical vulnerability in modern digital forensics: the inability of detectors to generalize to unseen manipulation techniques. Traditional networks suffer from representation collapse, overfitting to localized artifact fingerprints of specific training generators. This work investigates whether modern Vision Foundation Models can serve as generalizable, out-of-the-box feature extractors capable of tracking forensic anomalies across entirely unseen generative manifolds. We conduct a systematic cross-domain evaluation comparing three foundational learning paradigms: fully supervised macro-semantic features (RoPE-ViT), pure self-supervised geometric features (DINOv3), and multi-teacher agglomerative representations (NVIDIA C-RADIOv4-H). By deploying frozen backbones subjected to downstream linear probing, we map the performance limitations of these architectures on the challenging DF40 benchmark. Our empirical findings expose the intrinsic trade-offs between pre-training paradigms and parameter scale, proving that while foundation models retain high discriminative capabilities for entire face synthesis, localized face editing techniques expose fundamental boundaries in linear probe evaluation structures. Source code and model weights are available in http://github.com/mribrahim/deepfake
Spectral Manifold Regularization for Stable and Modular Routing in Deep MoE Architectures
Jan 07, 2026Mixture of Experts (MoE) architectures enable efficient scaling of neural networks but suffer from expert collapse, where routing converges to a few dominant experts. This reduces model capacity and causes catastrophic interference during adaptation. We propose the Spectrally-Regularized Mixture of Experts (SR-MoE), which imposes geometric constraints on the routing manifold to enforce structural modularity. Our method uses dual regularization: spectral norm constraints bound routing function Lipschitz continuity, while stable rank penalties preserve high-dimensional feature diversity in expert selection. We evaluate SR-MoE across architectural scales and dataset complexities using modular one-shot adaptation tasks. Results show that traditional linear gating fails with increasing depth (accuracy drops up to 4.72% due to expert entanglement), while SR-MoE maintains structural integrity (mean interference -0.32%). Our spectral constraints facilitate positive knowledge transfer, enabling localized expert updates without global performance decay. SR-MoE provides a general solution for building high-capacity, modular networks capable of stable lifelong learning.
EDformer: Embedded Decomposition Transformer for Interpretable Multivariate Time Series Predictions
Dec 16, 2024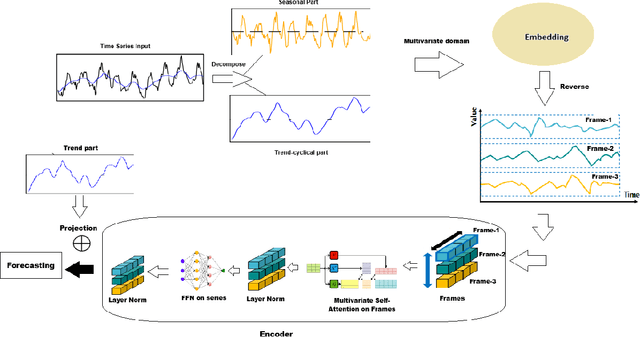
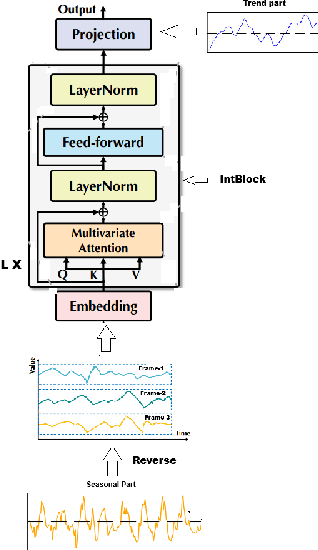
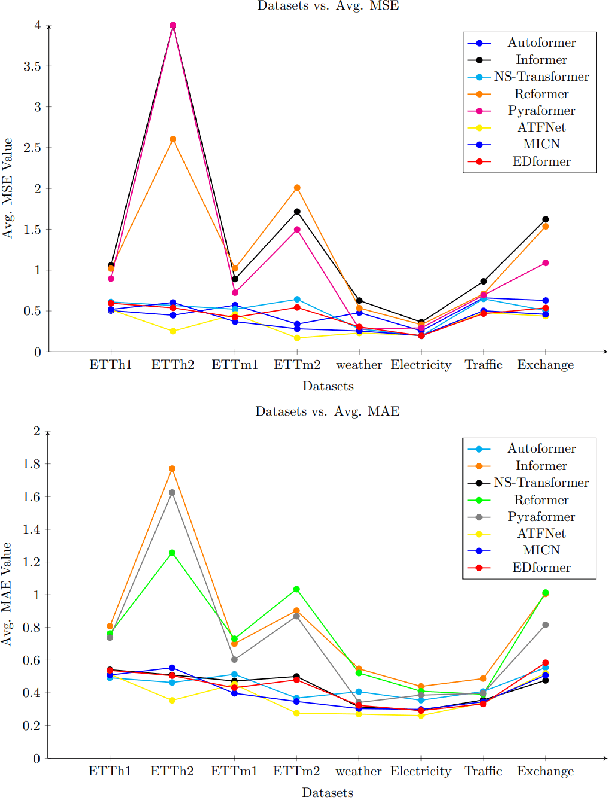
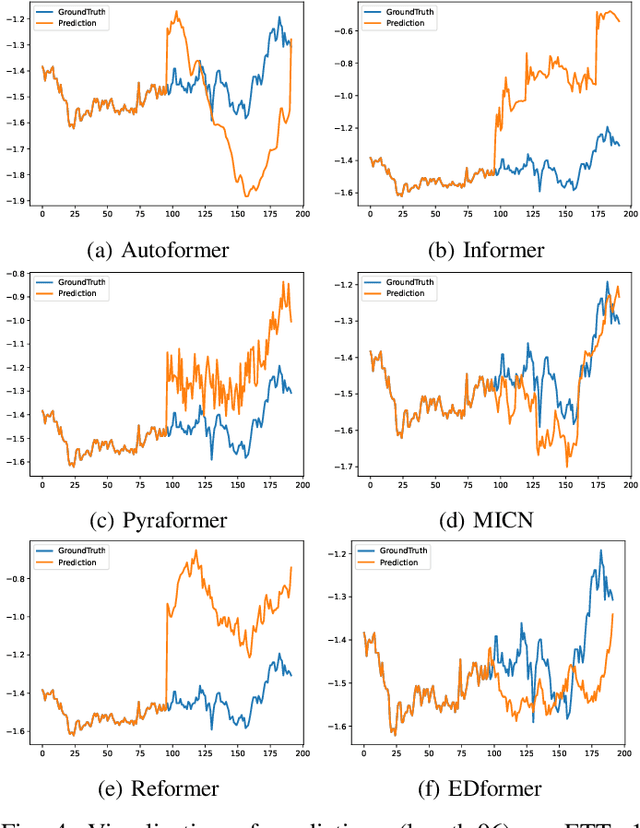
Time series forecasting is a crucial challenge with significant applications in areas such as weather prediction, stock market analysis, and scientific simulations. This paper introduces an embedded decomposed transformer, 'EDformer', for multivariate time series forecasting tasks. Without altering the fundamental elements, we reuse the Transformer architecture and consider the capable functions of its constituent parts in this work. Edformer first decomposes the input multivariate signal into seasonal and trend components. Next, the prominent multivariate seasonal component is reconstructed across the reverse dimensions, followed by applying the attention mechanism and feed-forward network in the encoder stage. In particular, the feed-forward network is used for each variable frame to learn nonlinear representations, while the attention mechanism uses the time points of individual seasonal series embedded within variate frames to capture multivariate correlations. Therefore, the trend signal is added with projection and performs the final forecasting. The EDformer model obtains state-of-the-art predicting results in terms of accuracy and efficiency on complex real-world time series datasets. This paper also addresses model explainability techniques to provide insights into how the model makes its predictions and why specific features or time steps are important, enhancing the interpretability and trustworthiness of the forecasting results.
UAV Images Dataset for Moving Object Detection from Moving Cameras
Mar 24, 2021



This paper presents a new high resolution aerial images dataset in which moving objects are labelled manually. It aims to contribute to the evaluation of the moving object detection methods for moving cameras. The problem of recognizing moving objects from aerial images is one of the important issues in computer vision. The biggest problem in the images taken by UAV is that the background is constantly variable due to camera movement. There are various datasets in the literature in which proposed methods for motion detection are evaluated. Prepared dataset consists of challenging images containing small targets compared to other datasets. Two methods in the literature have been tested for the prepared dataset. In addition, a simpler method compared to these methods has been proposed for moving object object in this paper.