 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair4Free: Generating High-fidelity Fair Synthetic Samples using Data Free Distillation
Oct 02, 2024


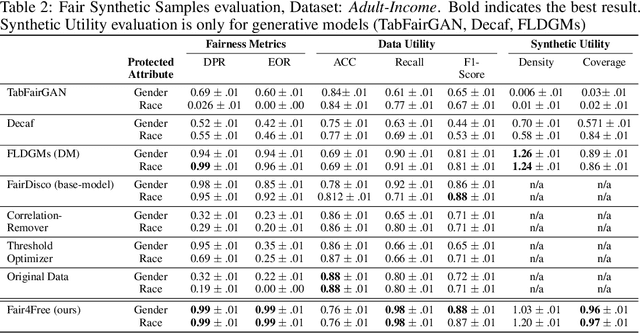
This work presents Fair4Free, a novel generative model to generate synthetic fair data using data-free distillation in the latent space. Fair4Free can work on the situation when the data is private or inaccessible. In our approach, we first train a teacher model to create fair representation and then distil the knowledge to a student model (using a smaller architecture). The process of distilling the student model is data-free, i.e. the student model does not have access to the training dataset while distilling. After the distillation, we use the distilled model to generate fair synthetic samples. Our extensive experiments show that our synthetic samples outperform state-of-the-art models in all three criteria (fairness, utility and synthetic quality) with a performance increase of 5% for fairness, 8% for utility and 12% in synthetic quality for both tabular and image datasets.
Generating Synthetic Fair Syntax-agnostic Data by Learning and Distilling Fair Representation
Aug 20, 2024



Data Fairness is a crucial topic due to the recent wide usage of AI powered applications. Most of the real-world data is filled with human or machine biases and when those data are being used to train AI models, there is a chance that the model will reflect the bias in the training data. Existing bias-mitigating generative methods based on GANs, Diffusion models need in-processing fairness objectives and fail to consider computational overhead while choosing computationally-heavy architectures, which may lead to high computational demands, instability and poor optimization performance. To mitigate this issue, in this work, we present a fair data generation technique based on knowledge distillation, where we use a small architecture to distill the fair representation in the latent space. The idea of fair latent space distillation enables more flexible and stable training of Fair Generative Models (FGMs). We first learn a syntax-agnostic (for any data type) fair representation of the data, followed by distillation in the latent space into a smaller model. After distillation, we use the distilled fair latent space to generate high-fidelity fair synthetic data. While distilling, we employ quality loss (for fair distillation) and utility loss (for data utility) to ensure that the fairness and data utility characteristics remain in the distilled latent space. Our approaches show a 5%, 5% and 10% rise in performance in fairness, synthetic sample quality and data utility, respectively, than the state-of-the-art fair generative model.
FairX: A comprehensive benchmarking tool for model analysis using fairness, utility, and explainability
Jun 20, 2024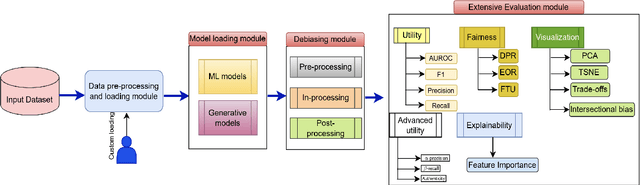

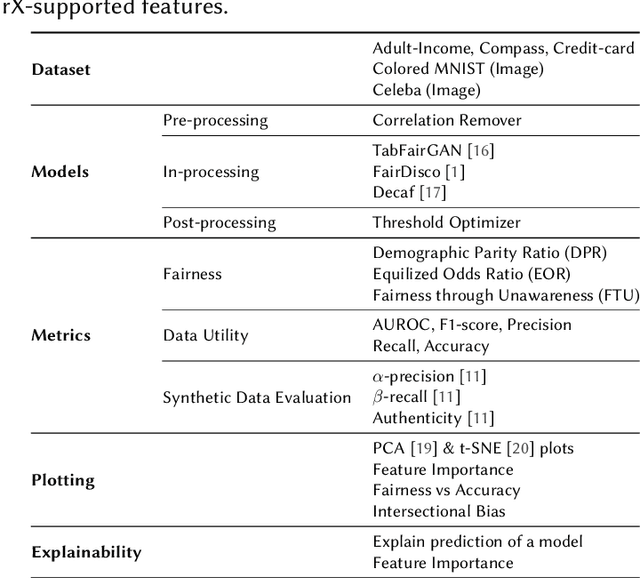
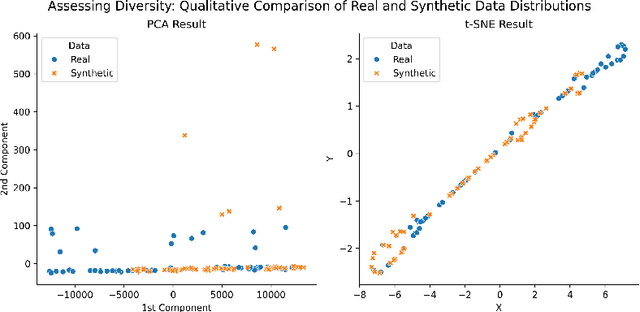
We present FairX, an open-source Python-based benchmarking tool designed for the comprehensive analysis of models under the umbrella of fairness, utility, and eXplainability (XAI). FairX enables users to train benchmarking bias-removal models and evaluate their fairness using a wide array of fairness metrics, data utility metrics, and generate explanations for model predictions, all within a unified framework. Existing benchmarking tools do not have the way to evaluate synthetic data generated from fair generative models, also they do not have the support for training fair generative models either. In FairX, we add fair generative models in the collection of our fair-model library (pre-processing, in-processing, post-processing) and evaluation metrics for evaluating the quality of synthetic fair data. This version of FairX supports both tabular and image datasets. It also allows users to provide their own custom datasets. The open-source FairX benchmarking package is publicly available at https://github.com/fahim-sikder/FairX.