 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentA/B: Automated and Scalable Web A/BTesting with Interactive LLM Agents
Apr 13, 2025



A/B testing experiment is a widely adopted method for evaluating UI/UX design decisions in modern web applications. Yet, traditional A/B testing remains constrained by its dependence on the large-scale and live traffic of human participants, and the long time of waiting for the testing result. Through formative interviews with six experienced industry practitioners, we identified critical bottlenecks in current A/B testing workflows. In response, we present AgentA/B, a novel system that leverages Large Language Model-based autonomous agents (LLM Agents) to automatically simulate user interaction behaviors with real webpages. AgentA/B enables scalable deployment of LLM agents with diverse personas, each capable of navigating the dynamic webpage and interactively executing multi-step interactions like search, clicking, filtering, and purchasing. In a demonstrative controlled experiment, we employ AgentA/B to simulate a between-subject A/B testing with 1,000 LLM agents Amazon.com, and compare agent behaviors with real human shopping behaviors at a scale. Our findings suggest AgentA/B can emulate human-like behavior patterns.
UXAgent: A System for Simulating Usability Testing of Web Design with LLM Agents
Apr 13, 2025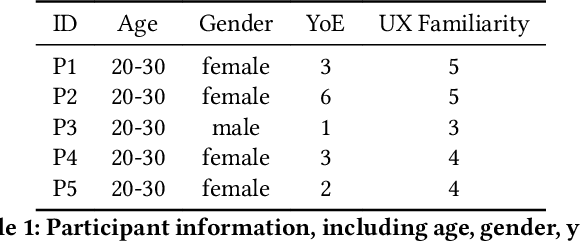
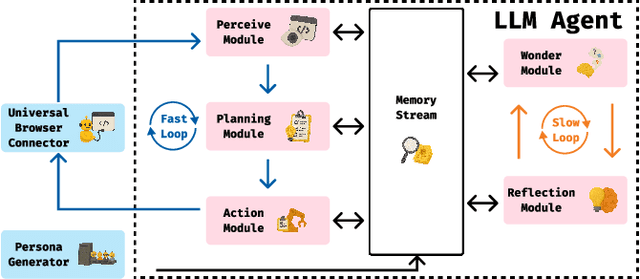
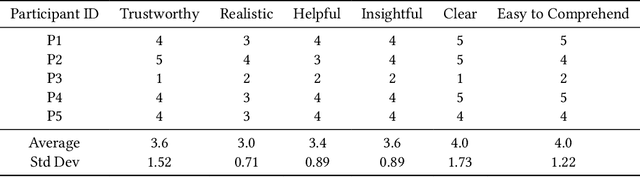
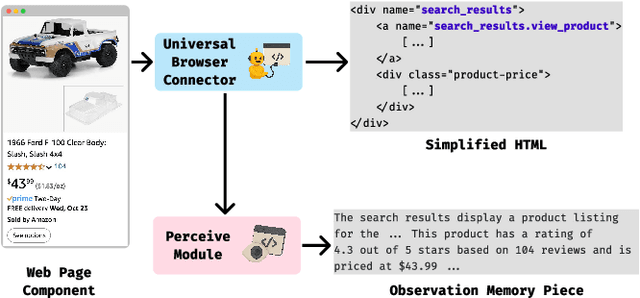
Usability testing is a fundamental research method that user experience (UX) researchers use to evaluate and iterate a web design, but\textbf{ how to evaluate and iterate the usability testing study design } itself? Recent advances in Large Language Model-simulated Agent (\textbf{LLM Agent}) research inspired us to design \textbf{UXAgent} to support UX researchers in evaluating and reiterating their usability testing study design before they conduct the real human-subject study. Our system features a Persona Generator module, an LLM Agent module, and a Universal Browser Connector module to automatically generate thousands of simulated users to interactively test the target website. The system also provides an Agent Interview Interface and a Video Replay Interface so that the UX researchers can easily review and analyze the generated qualitative and quantitative log data. Through a heuristic evaluation, five UX researcher participants praised the innovation of our system but also expressed concerns about the future of LLM Agent usage in UX studies.
Beyond Believability: Accurate Human Behavior Simulation with Fine-Tuned LLMs
Mar 27, 2025Recent research shows that LLMs can simulate ``believable'' human behaviors to power LLM agents via prompt-only methods. In this work, we focus on evaluating and improving LLM's objective ``accuracy'' rather than the subjective ``believability'' in the web action generation task, leveraging a large-scale, real-world dataset collected from online shopping human actions. We present the first comprehensive quantitative evaluation of state-of-the-art LLMs (e.g., DeepSeek-R1, Llama, and Claude) on the task of web action generation. Our results show that fine-tuning LLMs on real-world behavioral data substantially improves their ability to generate actions compared to prompt-only methods. Furthermore, incorporating synthesized reasoning traces into model training leads to additional performance gains, demonstrating the value of explicit rationale in behavior modeling. This work establishes a new benchmark for evaluating LLMs in behavior simulation and offers actionable insights into how real-world action data and reasoning augmentation can enhance the fidelity of LLM agents.
UXAgent: An LLM Agent-Based Usability Testing Framework for Web Design
Feb 18, 2025



Usability testing is a fundamental yet challenging (e.g., inflexible to iterate the study design flaws and hard to recruit study participants) research method for user experience (UX) researchers to evaluate a web design. Recent advances in Large Language Model-simulated Agent (LLM-Agent) research inspired us to design UXAgent to support UX researchers in evaluating and reiterating their usability testing study design before they conduct the real human subject study. Our system features an LLM-Agent module and a universal browser connector module so that UX researchers can automatically generate thousands of simulated users to test the target website. The results are shown in qualitative (e.g., interviewing how an agent thinks ), quantitative (e.g., # of actions), and video recording formats for UX researchers to analyze. Through a heuristic user evaluation with five UX researchers, participants praised the innovation of our system but also expressed concerns about the future of LLM Agent-assisted UX study.