 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale data extraction from the UNOS organ donor documents
Aug 30, 2023The scope of our study is all UNOS data of the USA organ donors since 2008. The data is not analyzable in a large scale in the past because it was captured in PDF documents known as "Attachments", whereby every donor is represented by dozens of PDF documents in heterogenous formats. To make the data analyzable, one needs to convert the content inside these PDFs to an analyzable data format, such as a standard SQL database. In this paper we will focus on 2022 UNOS data comprised of $\approx 400,000$ PDF documents spanning millions of pages. The totality of UNOS data covers 15 years (2008--20022) and our results will be quickly extended to the entire data. Our method captures a portion of the data in DCD flowsheets, kidney perfusion data, and data captured during patient hospital stay (e.g. vital signs, ventilator settings, etc.). The current paper assumes that the reader is familiar with the content of the UNOS data. The overview of the types of data and challenges they present is a subject of another paper. Here we focus on demonstrating that the goal of building a comprehensive, analyzable database from UNOS documents is an attainable task, and we provide an overview of our methodology. The project resulted in datasets by far larger than previously available even in this preliminary phase.
Convergence Rates for Multi-classs Logistic Regression Near Minimum
Jan 10, 2021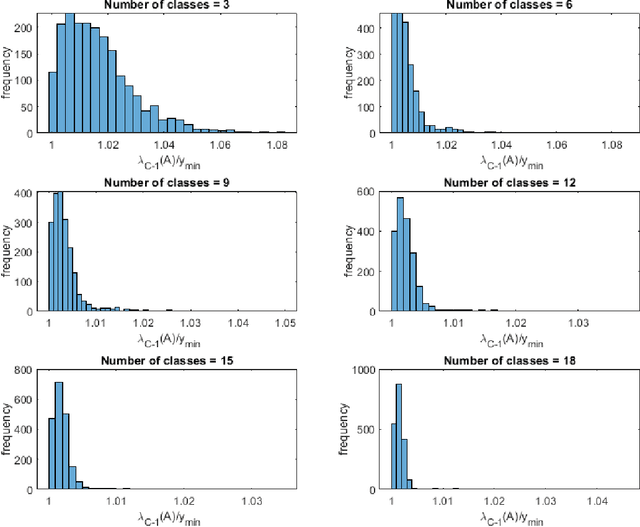
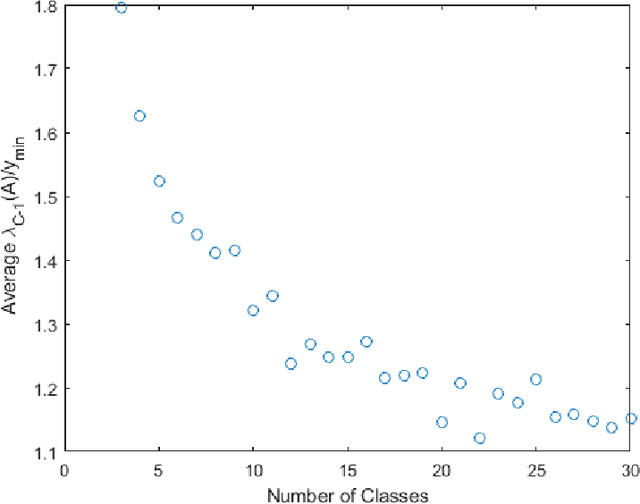
Training a neural network is typically done via variations of gradient descent. If a minimum of the loss function exists and gradient descent is used as the training method, we provide an expression that relates learning rate to the rate of convergence to the minimum. We also discuss existence of a minimum.
Development of a New Image-to-text Conversion System for Pashto, Farsi and Traditional Chinese
May 08, 2020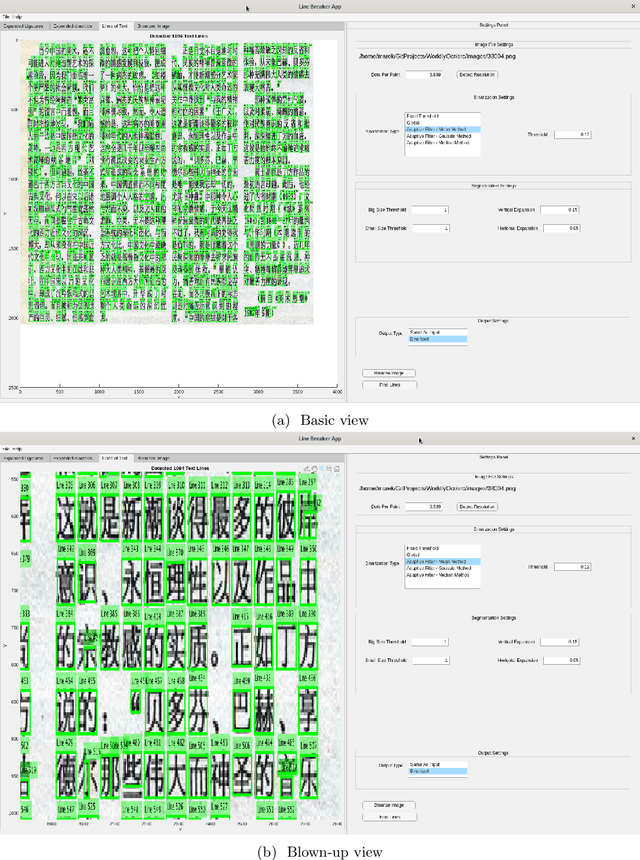
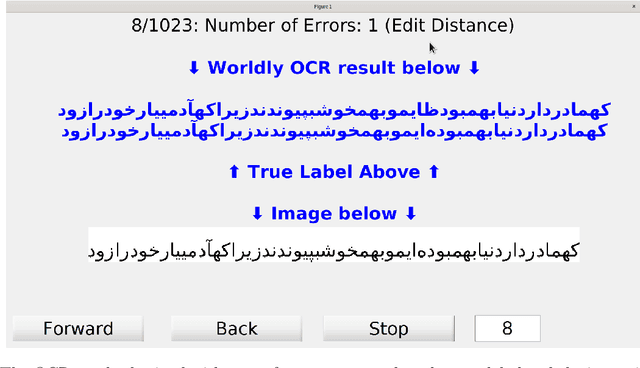

We report upon the results of a research and prototype building project \emph{Worldly~OCR} dedicated to developing new, more accurate image-to-text conversion software for several languages and writing systems. These include the cursive scripts Farsi and Pashto, and Latin cursive scripts. We also describe approaches geared towards Traditional Chinese, which is non-cursive, but features an extremely large character set of 65,000 characters. Our methodology is based on Machine Learning, especially Deep Learning, and Data Science, and is directed towards vast quantities of original documents, exceeding a billion pages. The target audience of this paper is a general audience with interest in Digital Humanities or in retrieval of accurate full-text and metadata from digital images.
A proof of convergence of multi-class logistic regression network
Apr 06, 2019This paper revisits the special type of a neural network known under two names. In the statistics and machine learning community it is known as a multi-class logistic regression neural network. In the neural network community, it is simply the soft-max layer. The importance is underscored by its role in deep learning: as the last layer, whose autput is actually the classification of the input patterns, such as images. Our exposition focuses on mathematically rigorous derivation of the key equation expressing the gradient. The fringe benefit of our approach is a fully vectorized expression, which is a basis of an efficient implementation. The second result of this paper is the positivity of the second derivative of the cross-entropy loss function as function of the weights. This result proves that optimization methods based on convexity may be used to train this network. As a corollary, we demonstrate that no $L^2$-regularizer is needed to guarantee convergence of gradient descent.
Deductron - A Recurrent Neural Network
Jun 23, 2018



The current paper is a study in Recurrent Neural Networks (RNN), motivated by the lack of examples simple enough so that they can be thoroughly understood theoretically, but complex enough to be realistic. We constructed an example of structured data, motivated by problems from image-to-text conversion (OCR), which requires long-term memory to decode. Our data is a simple writing system, encoding characters 'X' and 'O' as their upper halves, which is possible due to symmetry of the two characters. The characters can be connected, as in some languages using cursive, such as Arabic (abjad). The string 'XOOXXO' may be encoded as '${\vee}{\wedge}\kern-1.5pt{\wedge}{\vee}\kern-1.5pt{\vee}{\wedge}$'. It follows that we may need to know arbitrarily long past to decode a current character, thus requiring long-term memory. Subsequently we constructed an RNN capable of decoding sequences encoded in this manner. Rather than by training, we constructed our RNN "by inspection", i.e. we guessed its weights. This involved a sequence of steps. We wrote a conventional program which decodes the sequences as the example above. Subsequently, we interpreted the program as a neural network (the only example of this kind known to us). Finally, we generalized this neural network to discover a new RNN architecture whose instance is our handcrafted RNN. It turns out to be a 3 layer network, where the middle layer is capable of performing simple logical inferences; thus the name "deductron". It is demonstrated that it is possible to train our network by simulated annealing. Also, known variants of stochastic gradient descent (SGD) methods are shown to work.