 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment of a New Image-to-text Conversion System for Pashto, Farsi and Traditional Chinese
Paper and Code
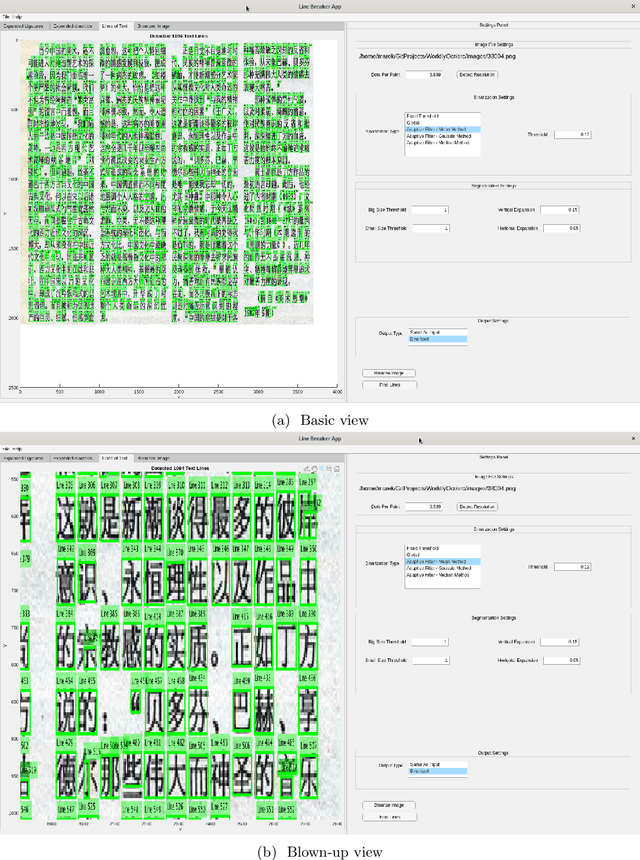
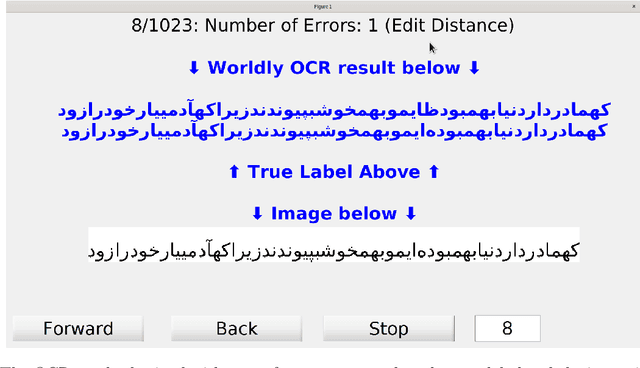

We report upon the results of a research and prototype building project \emph{Worldly~OCR} dedicated to developing new, more accurate image-to-text conversion software for several languages and writing systems. These include the cursive scripts Farsi and Pashto, and Latin cursive scripts. We also describe approaches geared towards Traditional Chinese, which is non-cursive, but features an extremely large character set of 65,000 characters. Our methodology is based on Machine Learning, especially Deep Learning, and Data Science, and is directed towards vast quantities of original documents, exceeding a billion pages. The target audience of this paper is a general audience with interest in Digital Humanities or in retrieval of accurate full-text and metadata from digital images.