 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairSample: Training Fair and Accurate Graph Convolutional Neural Networks Efficiently
Jan 26, 2024



Fairness in Graph Convolutional Neural Networks (GCNs) becomes a more and more important concern as GCNs are adopted in many crucial applications. Societal biases against sensitive groups may exist in many real world graphs. GCNs trained on those graphs may be vulnerable to being affected by such biases. In this paper, we adopt the well-known fairness notion of demographic parity and tackle the challenge of training fair and accurate GCNs efficiently. We present an in-depth analysis on how graph structure bias, node attribute bias, and model parameters may affect the demographic parity of GCNs. Our insights lead to FairSample, a framework that jointly mitigates the three types of biases. We employ two intuitive strategies to rectify graph structures. First, we inject edges across nodes that are in different sensitive groups but similar in node features. Second, to enhance model fairness and retain model quality, we develop a learnable neighbor sampling policy using reinforcement learning. To address the bias in node features and model parameters, FairSample is complemented by a regularization objective to optimize fairness.
Data Pricing in Machine Learning Pipelines
Aug 18, 2021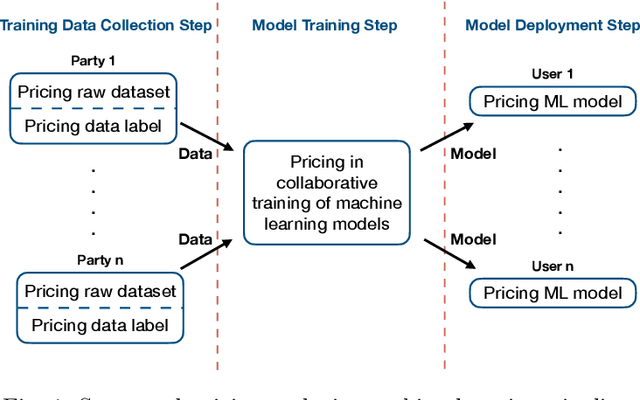

Machine learning is disruptive. At the same time, machine learning can only succeed by collaboration among many parties in multiple steps naturally as pipelines in an eco-system, such as collecting data for possible machine learning applications, collaboratively training models by multiple parties and delivering machine learning services to end users. Data is critical and penetrating in the whole machine learning pipelines. As machine learning pipelines involve many parties and, in order to be successful, have to form a constructive and dynamic eco-system, marketplaces and data pricing are fundamental in connecting and facilitating those many parties. In this article, we survey the principles and the latest research development of data pricing in machine learning pipelines. We start with a brief review of data marketplaces and pricing desiderata. Then, we focus on pricing in three important steps in machine learning pipelines. To understand pricing in the step of training data collection, we review pricing raw data sets and data labels. We also investigate pricing in the step of collaborative training of machine learning models, and overview pricing machine learning models for end users in the step of machine learning deployment. We also discuss a series of possible future directions.
Comprehensible Counterfactual Interpretation on Kolmogorov-Smirnov Test
Nov 01, 2020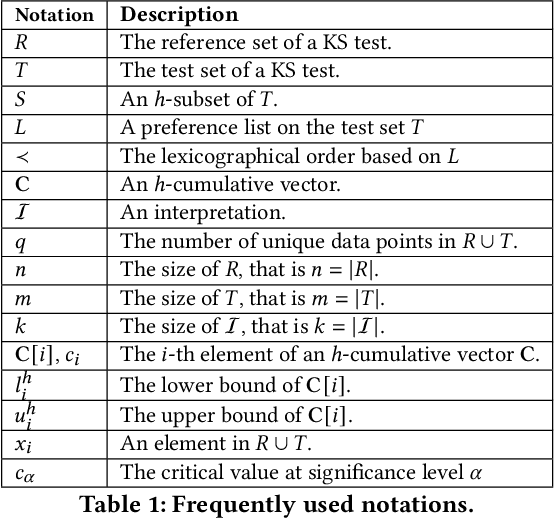



The Kolmogorov-Smirnov (KS) test is popularly used in many applications, such as anomaly detection, astronomy, database security and AI systems. One challenge remained untouched is how we can obtain an interpretation on why a test set fails the KS test. In this paper, we tackle the problem of producing counterfactual interpretations for test data failing the KS test. Concept-wise, we propose the notion of most comprehensible counterfactual interpretations, which accommodates both the KS test data and the user domain knowledge in producing interpretations. Computation-wise, we develop an efficient algorithm MOCHI that avoids enumerating and checking an exponential number of subsets of the test set failing the KS test. MOCHI not only guarantees to produce the most comprehensible counterfactual interpretations, but also is orders of magnitudes faster than the baselines. Experiment-wise, we present a systematic empirical study on a series of benchmark real datasets to verify the effectiveness, efficiency and scalability of most comprehensible counterfactual interpretations and MOCHI.
Exact and Consistent Interpretation of Piecewise Linear Models Hidden behind APIs: A Closed Form Solution
Jun 17, 2019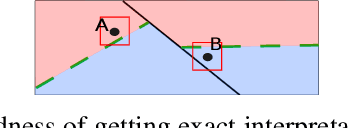
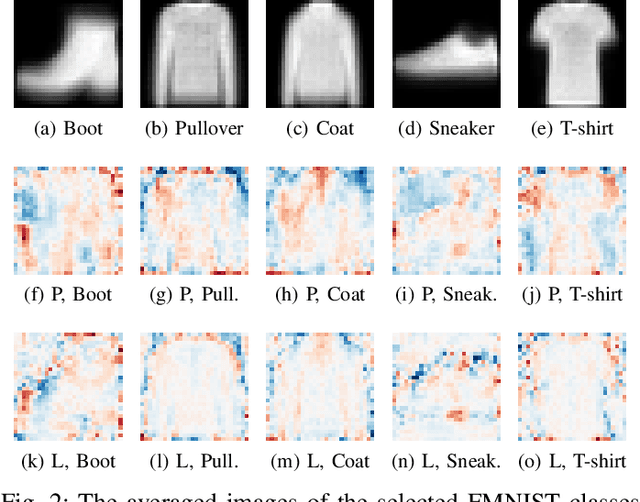

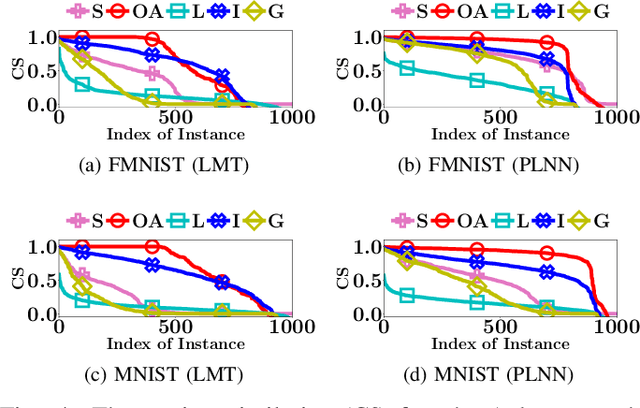
More and more AI services are provided through APIs on cloud where predictive models are hidden behind APIs. To build trust with users and reduce potential application risk, it is important to interpret how such predictive models hidden behind APIs make their decisions. The biggest challenge of interpreting such predictions is that no access to model parameters or training data is available. Existing works interpret the predictions of a model hidden behind an API by heuristically probing the response of the API with perturbed input instances. However, these methods do not provide any guarantee on the exactness and consistency of their interpretations. In this paper, we propose an elegant closed form solution named \texttt{OpenAPI} to compute exact and consistent interpretations for the family of Piecewise Linear Models (PLM), which includes many popular classification models. The major idea is to first construct a set of overdetermined linear equation systems with a small set of perturbed instances and the predictions made by the model on those instances. Then, we solve the equation systems to identify the decision features that are responsible for the prediction on an input instance. Our extensive experiments clearly demonstrate the exactness and consistency of our method.