 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Empowered Content-Aware Collaborative Filtering
Apr 02, 2022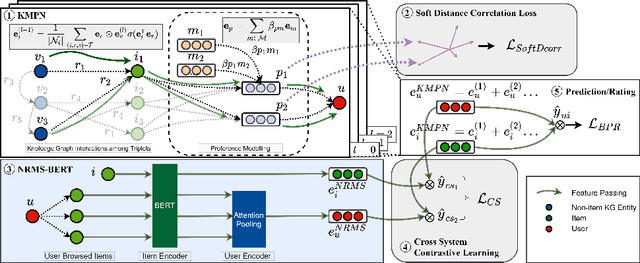
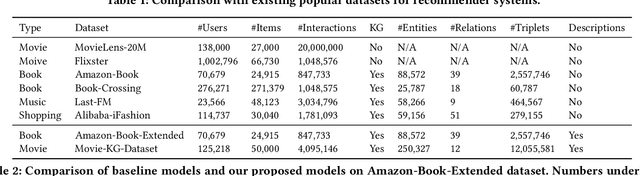


Knowledge graph (KG) based Collaborative Filtering is an effective approach to personalizing recommendation systems for relatively static domains such as movies and books, by leveraging structured information from KG to enrich both item and user representations. Motivated by the use of Transformers for understanding rich text in content-based filtering recommender systems, we propose Content-aware KG-enhanced Meta-preference Networks as a way to enhance collaborative filtering recommendation based on both structured information from KG as well as unstructured content features based on Transformer-empowered content-based filtering. To achieve this, we employ a novel training scheme, Cross-System Contrastive Learning, to address the inconsistency of the two very different systems and propose a powerful collaborative filtering model and a variant of the well-known NRMS system within this modeling framework. We also contribute to public domain resources through the creation of a large-scale movie-knowledge-graph dataset and an extension of the already public Amazon-Book dataset through incorporation of text descriptions crawled from external sources. We present experimental results showing that enhancing collaborative filtering with Transformer-based features derived from content-based filtering outperforms strong baseline systems, improving the ability of knowledge-graph-based collaborative filtering systems to exploit item content information.
Data Pricing in Machine Learning Pipelines
Aug 18, 2021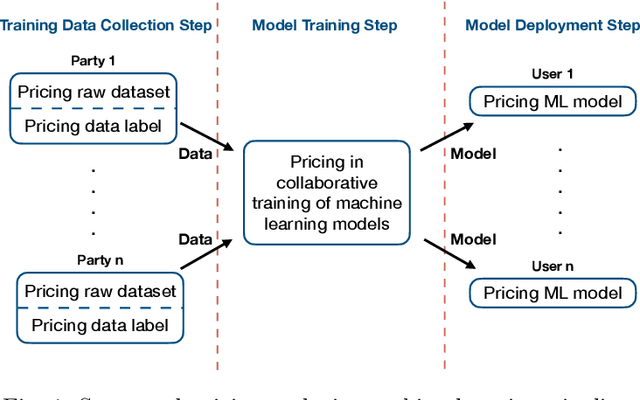

Machine learning is disruptive. At the same time, machine learning can only succeed by collaboration among many parties in multiple steps naturally as pipelines in an eco-system, such as collecting data for possible machine learning applications, collaboratively training models by multiple parties and delivering machine learning services to end users. Data is critical and penetrating in the whole machine learning pipelines. As machine learning pipelines involve many parties and, in order to be successful, have to form a constructive and dynamic eco-system, marketplaces and data pricing are fundamental in connecting and facilitating those many parties. In this article, we survey the principles and the latest research development of data pricing in machine learning pipelines. We start with a brief review of data marketplaces and pricing desiderata. Then, we focus on pricing in three important steps in machine learning pipelines. To understand pricing in the step of training data collection, we review pricing raw data sets and data labels. We also investigate pricing in the step of collaborative training of machine learning models, and overview pricing machine learning models for end users in the step of machine learning deployment. We also discuss a series of possible future directions.