 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidedQuant: Large Language Model Quantization via Exploiting End Loss Guidance
May 11, 2025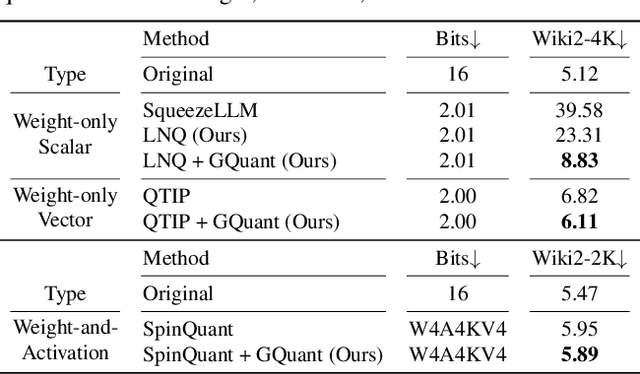
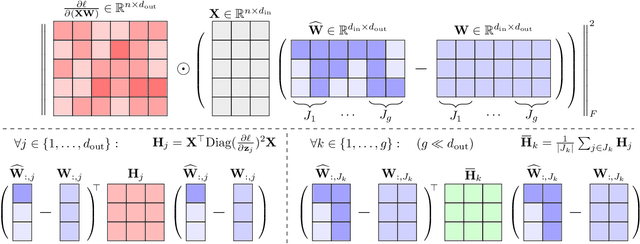
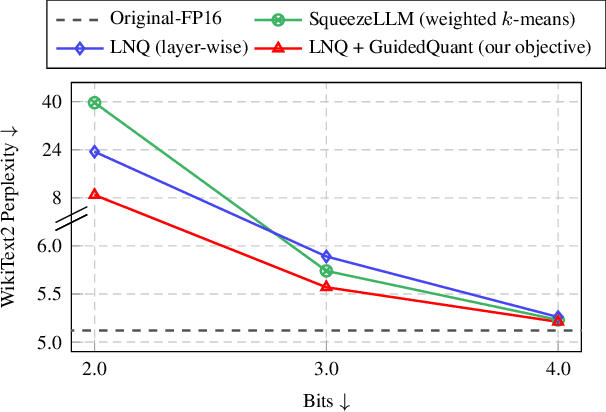
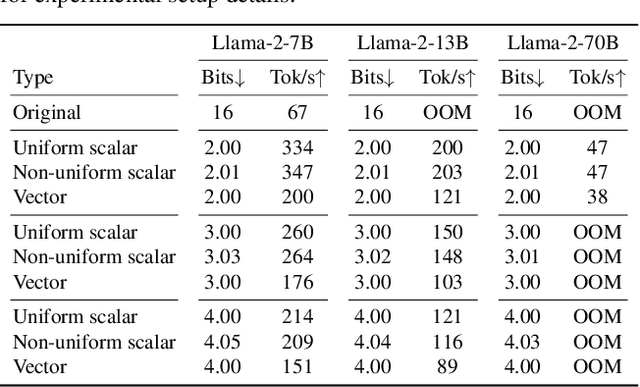
Post-training quantization is a key technique for reducing the memory and inference latency of large language models by quantizing weights and activations without requiring retraining. However, existing methods either (1) fail to account for the varying importance of hidden features to the end loss or, when incorporating end loss, (2) neglect the critical interactions between model weights. To address these limitations, we propose GuidedQuant, a novel quantization approach that integrates gradient information from the end loss into the quantization objective while preserving cross-weight dependencies within output channels. GuidedQuant consistently boosts the performance of state-of-the-art quantization methods across weight-only scalar, weight-only vector, and weight-and-activation quantization. Additionally, we introduce a novel non-uniform scalar quantization algorithm, which is guaranteed to monotonically decrease the quantization objective value, and outperforms existing methods in this category. We release the code at https://github.com/snu-mllab/GuidedQuant.
Hadamard Domain Training with Integers for Class Incremental Quantized Learning
Oct 05, 2023



Continual learning is a desirable feature in many modern machine learning applications, which allows in-field adaptation and updating, ranging from accommodating distribution shift, to fine-tuning, and to learning new tasks. For applications with privacy and low latency requirements, the compute and memory demands imposed by continual learning can be cost-prohibitive for resource-constraint edge platforms. Reducing computational precision through fully quantized training (FQT) simultaneously reduces memory footprint and increases compute efficiency for both training and inference. However, aggressive quantization especially integer FQT typically degrades model accuracy to unacceptable levels. In this paper, we propose a technique that leverages inexpensive Hadamard transforms to enable low-precision training with only integer matrix multiplications. We further determine which tensors need stochastic rounding and propose tiled matrix multiplication to enable low-bit width accumulators. We demonstrate the effectiveness of our technique on several human activity recognition datasets and CIFAR100 in a class incremental learning setting. We achieve less than 0.5% and 3% accuracy degradation while we quantize all matrix multiplications inputs down to 4-bits with 8-bit accumulators.
Augmenting Hessians with Inter-Layer Dependencies for Mixed-Precision Post-Training Quantization
Jun 08, 2023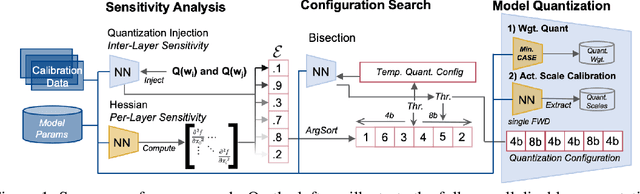
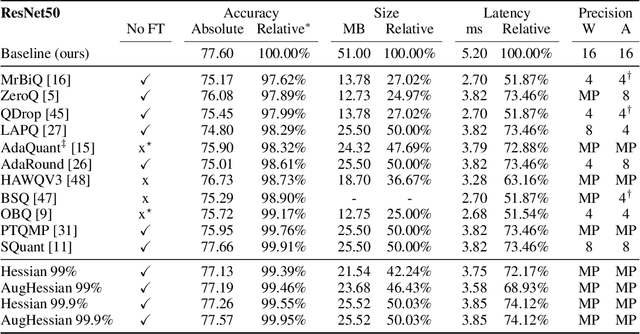
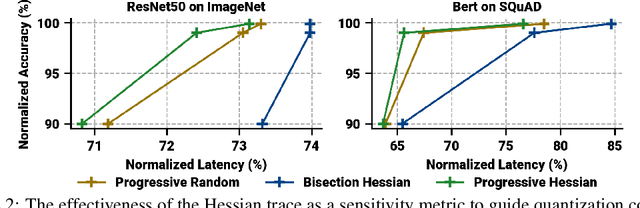
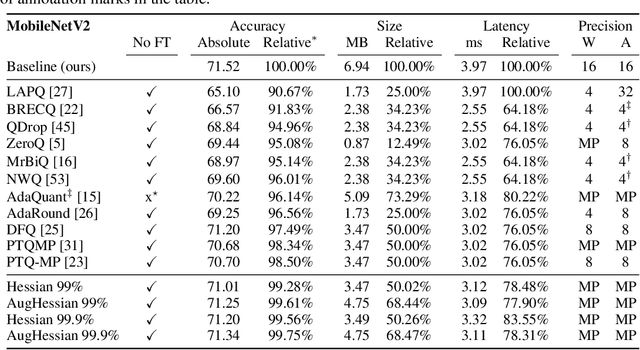
Efficiently serving neural network models with low latency is becoming more challenging due to increasing model complexity and parameter count. Model quantization offers a solution which simultaneously reduces memory footprint and compute requirements. However, aggressive quantization may lead to an unacceptable loss in model accuracy owing to differences in sensitivity to numerical imperfection across different layers in the model. To address this challenge, we propose a mixed-precision post training quantization (PTQ) approach that assigns different numerical precisions to tensors in a network based on their specific needs, for a reduced memory footprint and improved latency while preserving model accuracy. Previous works rely on layer-wise Hessian information to determine numerical precision, but as we demonstrate, Hessian estimation is typically insufficient in determining an effective ordering of layer sensitivities. We address this by augmenting the estimated Hessian with additional information to capture inter-layer dependencies. We demonstrate that this consistently improves PTQ performance along the accuracy-latency Pareto frontier across multiple models. Our method combines second-order information and inter-layer dependencies to guide a bisection search, finding quantization configurations within a user-configurable model accuracy degradation range. We evaluate the effectiveness of our method on the ResNet50, MobileNetV2, and BERT models. Our experiments demonstrate latency reductions compared to a 16-bit baseline of $25.48\%$, $21.69\%$, and $33.28\%$ respectively, while maintaining model accuracy to within $99.99\%$ of the baseline model.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
The Hardware Impact of Quantization and Pruning for Weights in Spiking Neural Networks
Feb 08, 2023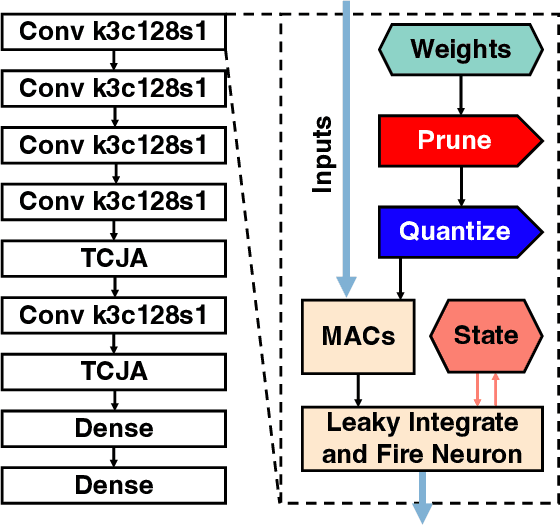
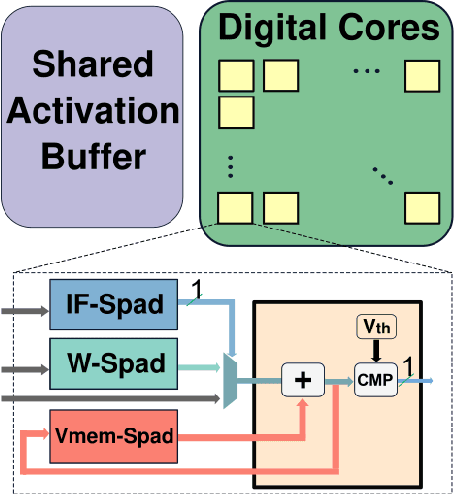
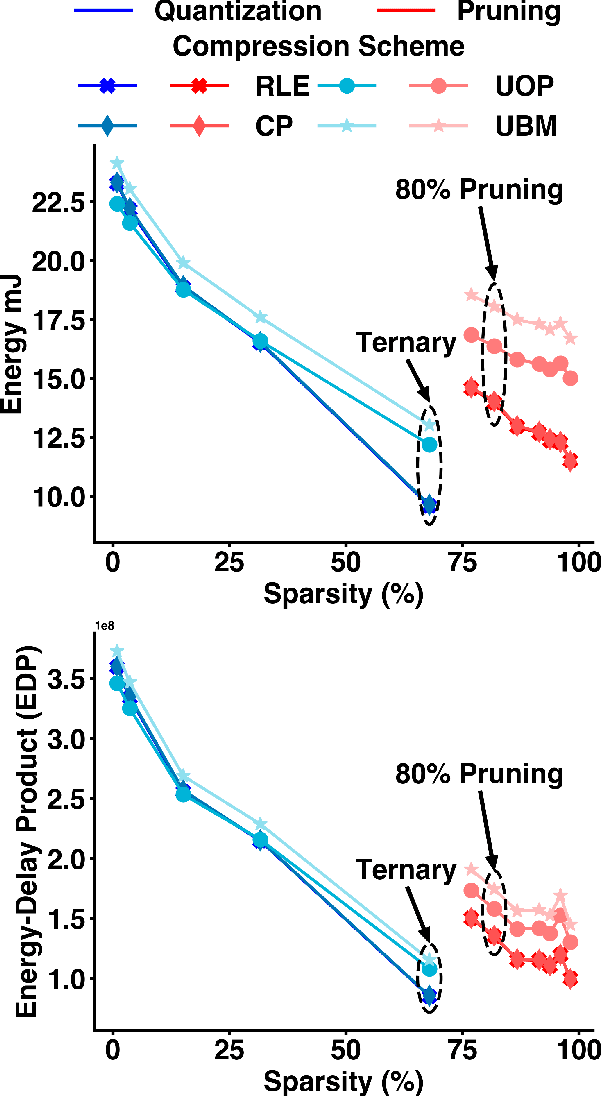
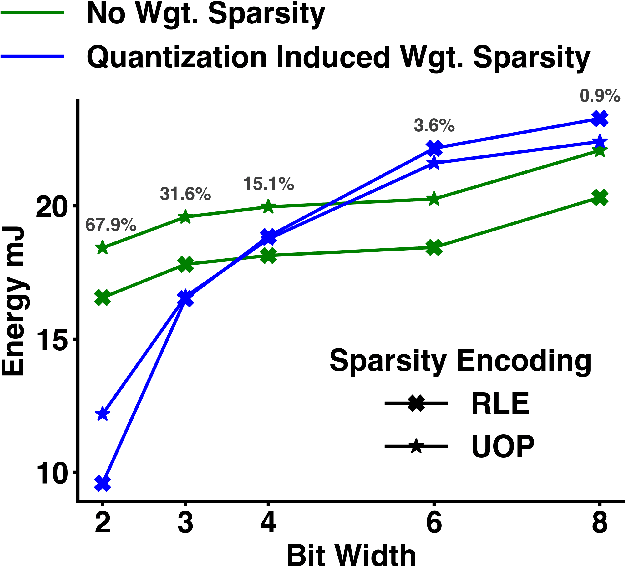
Energy efficient implementations and deployments of Spiking neural networks (SNNs) have been of great interest due to the possibility of developing artificial systems that can achieve the computational powers and energy efficiency of the biological brain. Efficient implementations of SNNs on modern digital hardware are also inspired by advances in machine learning and deep neural networks (DNNs). Two techniques widely employed in the efficient deployment of DNNs -- the quantization and pruning of parameters, can both compress the model size, reduce memory footprints, and facilitate low-latency execution. The interaction between quantization and pruning and how they might impact model performance on SNN accelerators is currently unknown. We study various combinations of pruning and quantization in isolation, cumulatively, and simultaneously (jointly) to a state-of-the-art SNN targeting gesture recognition for dynamic vision sensor cameras (DVS). We show that this state-of-the-art model is amenable to aggressive parameter quantization, not suffering from any loss in accuracy down to ternary weights. However, pruning only maintains iso-accuracy up to 80% sparsity, which results in 45% more energy than the best quantization on our architectural model. Applying both pruning and quantization can result in an accuracy loss to offer a favourable trade-off on the energy-accuracy Pareto-frontier for the given hardware configuration.
Mixed Precision Post Training Quantization of Neural Networks with Sensitivity Guided Search
Feb 07, 2023



Serving large-scale machine learning (ML) models efficiently and with low latency has become challenging owing to increasing model size and complexity. Quantizing models can simultaneously reduce memory and compute requirements, facilitating their widespread access. However, for large models not all layers are equally amenable to the same numerical precision and aggressive quantization can lead to unacceptable loss in model accuracy. One approach to prevent this accuracy degradation is mixed-precision quantization, which allows different tensors to be quantized to varying levels of numerical precision, leveraging the capabilities of modern hardware. Such mixed-precision quantiztaion can more effectively allocate numerical precision to different tensors `as needed' to preserve model accuracy while reducing footprint and compute latency. In this paper, we propose a method to efficiently determine quantization configurations of different tensors in ML models using post-training mixed precision quantization. We analyze three sensitivity metrics and evaluate them for guiding configuration search of two algorithms. We evaluate our method for computer vision and natural language processing and demonstrate latency reductions of up to 27.59% and 34.31% compared to the baseline 16-bit floating point model while guaranteeing no more than 1% accuracy degradation.
Edge Inference with Fully Differentiable Quantized Mixed Precision Neural Networks
Jun 15, 2022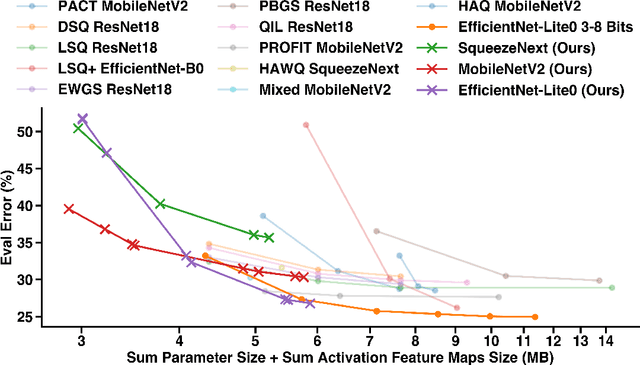
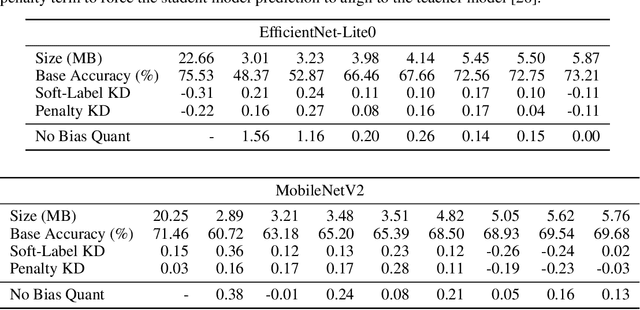
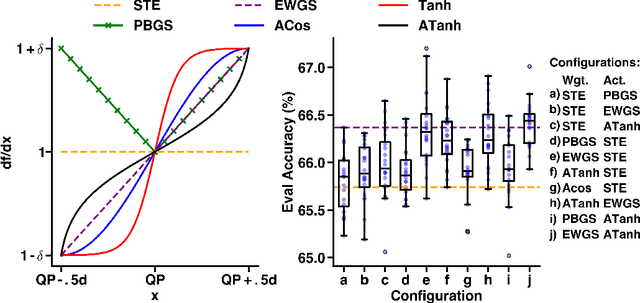
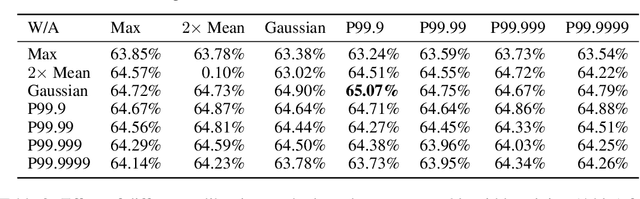
The large computing and memory cost of deep neural networks (DNNs) often precludes their use in resource-constrained devices. Quantizing the parameters and operations to lower bit-precision offers substantial memory and energy savings for neural network inference, facilitating the use of DNNs on edge computing platforms. Recent efforts at quantizing DNNs have employed a range of techniques encompassing progressive quantization, step-size adaptation, and gradient scaling. This paper proposes a new quantization approach for mixed precision convolutional neural networks (CNNs) targeting edge-computing. Our method establishes a new pareto frontier in model accuracy and memory footprint demonstrating a range of quantized models, delivering best-in-class accuracy below 4.3 MB of weights (wgts.) and activations (acts.). Our main contributions are: (i) hardware-aware heterogeneous differentiable quantization with tensor-sliced learned precision, (ii) targeted gradient modification for wgts. and acts. to mitigate quantization errors, and (iii) a multi-phase learning schedule to address instability in learning arising from updates to the learned quantizer and model parameters. We demonstrate the effectiveness of our techniques on the ImageNet dataset across a range of models including EfficientNet-Lite0 (e.g., 4.14MB of wgts. and acts. at 67.66% accuracy) and MobileNetV2 (e.g., 3.51MB wgts. and acts. at 65.39% accuracy).
Memory Organization for Energy-Efficient Learning and Inference in Digital Neuromorphic Accelerators
Mar 05, 2020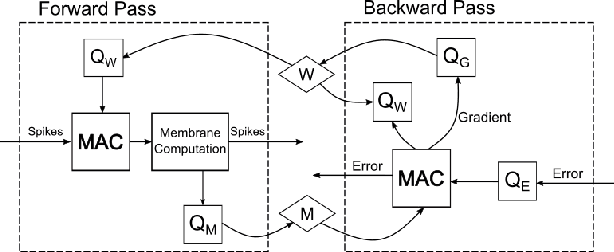
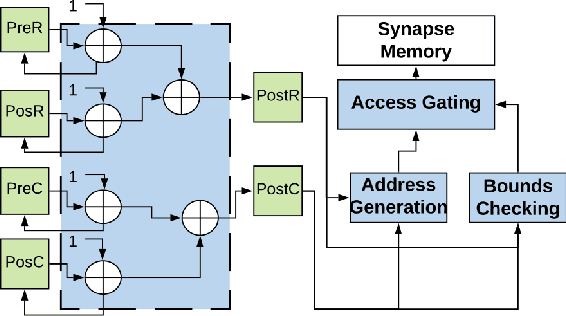
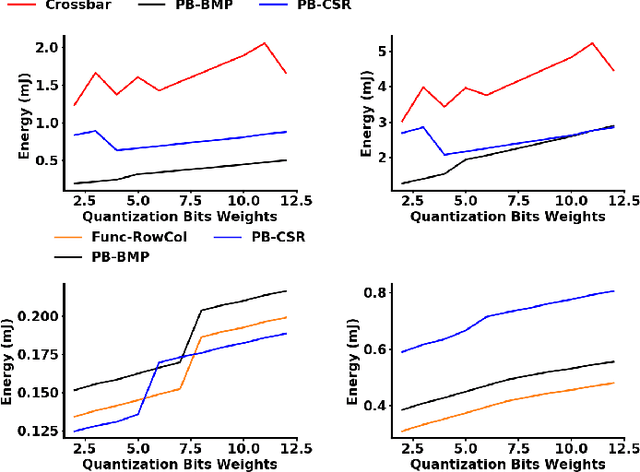
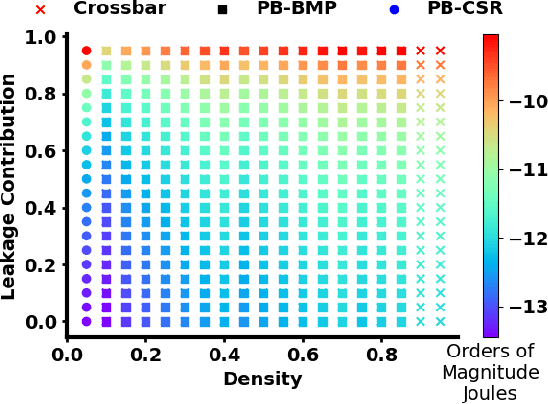
The energy efficiency of neuromorphic hardware is greatly affected by the energy of storing, accessing, and updating synaptic parameters. Various methods of memory organisation targeting energy-efficient digital accelerators have been investigated in the past, however, they do not completely encapsulate the energy costs at a system level. To address this shortcoming and to account for various overheads, we synthesize the controller and memory for different encoding schemes and extract the energy costs from these synthesized blocks. Additionally, we introduce functional encoding for structured connectivity such as the connectivity in convolutional layers. Functional encoding offers a 58% reduction in the energy to implement a backward pass and weight update in such layers compared to existing index-based solutions. We show that for a 2 layer spiking neural network trained to retain a spatio-temporal pattern, bitmap (PB-BMP) based organization can encode the sparser networks more efficiently. This form of encoding delivers a 1.37x improvement in energy efficiency coming at the cost of a 4% degradation in network retention accuracy as measured by the van Rossum distance.