 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Hessians with Inter-Layer Dependencies for Mixed-Precision Post-Training Quantization
Jun 08, 2023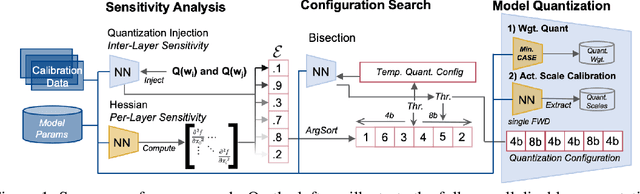
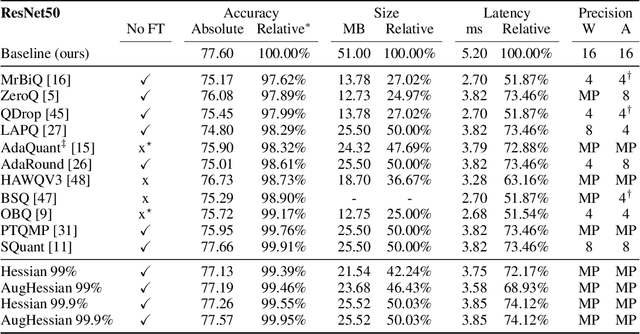
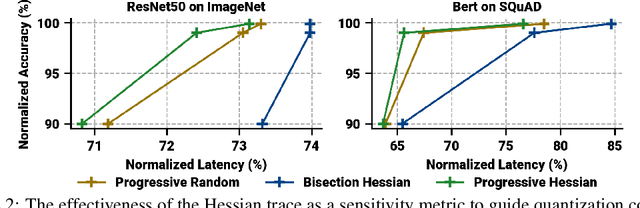
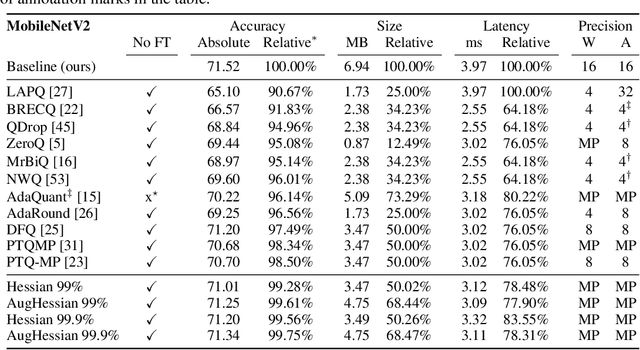
Efficiently serving neural network models with low latency is becoming more challenging due to increasing model complexity and parameter count. Model quantization offers a solution which simultaneously reduces memory footprint and compute requirements. However, aggressive quantization may lead to an unacceptable loss in model accuracy owing to differences in sensitivity to numerical imperfection across different layers in the model. To address this challenge, we propose a mixed-precision post training quantization (PTQ) approach that assigns different numerical precisions to tensors in a network based on their specific needs, for a reduced memory footprint and improved latency while preserving model accuracy. Previous works rely on layer-wise Hessian information to determine numerical precision, but as we demonstrate, Hessian estimation is typically insufficient in determining an effective ordering of layer sensitivities. We address this by augmenting the estimated Hessian with additional information to capture inter-layer dependencies. We demonstrate that this consistently improves PTQ performance along the accuracy-latency Pareto frontier across multiple models. Our method combines second-order information and inter-layer dependencies to guide a bisection search, finding quantization configurations within a user-configurable model accuracy degradation range. We evaluate the effectiveness of our method on the ResNet50, MobileNetV2, and BERT models. Our experiments demonstrate latency reductions compared to a 16-bit baseline of $25.48\%$, $21.69\%$, and $33.28\%$ respectively, while maintaining model accuracy to within $99.99\%$ of the baseline model.
Mixed Precision Post Training Quantization of Neural Networks with Sensitivity Guided Search
Feb 07, 2023



Serving large-scale machine learning (ML) models efficiently and with low latency has become challenging owing to increasing model size and complexity. Quantizing models can simultaneously reduce memory and compute requirements, facilitating their widespread access. However, for large models not all layers are equally amenable to the same numerical precision and aggressive quantization can lead to unacceptable loss in model accuracy. One approach to prevent this accuracy degradation is mixed-precision quantization, which allows different tensors to be quantized to varying levels of numerical precision, leveraging the capabilities of modern hardware. Such mixed-precision quantiztaion can more effectively allocate numerical precision to different tensors `as needed' to preserve model accuracy while reducing footprint and compute latency. In this paper, we propose a method to efficiently determine quantization configurations of different tensors in ML models using post-training mixed precision quantization. We analyze three sensitivity metrics and evaluate them for guiding configuration search of two algorithms. We evaluate our method for computer vision and natural language processing and demonstrate latency reductions of up to 27.59% and 34.31% compared to the baseline 16-bit floating point model while guaranteeing no more than 1% accuracy degradation.
Scale MLPerf-0.6 models on Google TPU-v3 Pods
Oct 02, 2019
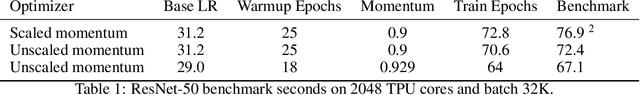

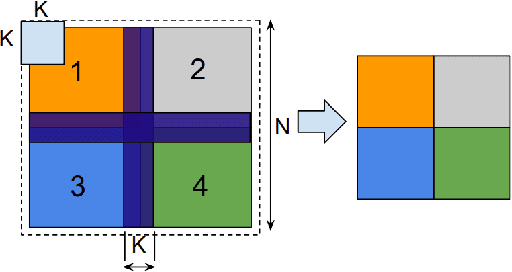
The recent submission of Google TPU-v3 Pods to the industry wide MLPerf v0.6 training benchmark demonstrates the scalability of a suite of industry relevant ML models. MLPerf defines a suite of models, datasets and rules to follow when benchmarking to ensure results are comparable across hardware, frameworks and companies. Using this suite of models, we discuss the optimizations and techniques including choice of optimizer, spatial partitioning and weight update sharding necessary to scale to 1024 TPU chips. Furthermore, we identify properties of models that make scaling them challenging, such as limited data parallelism and unscaled weights. These optimizations contribute to record performance in transformer, Resnet-50 and SSD in the Google MLPerf-0.6 submission.