 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTAM: Video-Tactile-Action Models for Complex Physical Interaction Beyond VLAs
Mar 24, 2026Video-Action Models (VAMs) have emerged as a promising framework for embodied intelligence, learning implicit world dynamics from raw video streams to produce temporally consistent action predictions. Although such models demonstrate strong performance on long-horizon tasks through visual reasoning, they remain limited in contact-rich scenarios where critical interaction states are only partially observable from vision alone. In particular, fine-grained force modulation and contact transitions are not reliably encoded in visual tokens, leading to unstable or imprecise behaviors. To bridge this gap, we introduce the Video-Tactile Action Model (VTAM), a multimodal world modeling framework that incorporates tactile perception as a complementary grounding signal. VTAM augments a pretrained video transformer with tactile streams via a lightweight modality transfer finetuning, enabling efficient cross-modal representation learning without tactile-language paired data or independent tactile pretraining. To stabilize multimodal fusion, we introduce a tactile regularization loss that enforces balanced cross-modal attention, preventing visual latent dominance in the action model. VTAM demonstrates superior performance in contact-rich manipulation, maintaining a robust success rate of 90 percent on average. In challenging scenarios such as potato chip pick-and-place requiring high-fidelity force awareness, VTAM outperforms the pi 0.5 baseline by 80 percent. Our findings demonstrate that integrating tactile feedback is essential for correcting visual estimation errors in world action models, providing a scalable approach to physically grounded embodied foundation models.
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Jan 11, 2026Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.
DoorBot: Closed-Loop Task Planning and Manipulation for Door Opening in the Wild with Haptic Feedback
Apr 12, 2025Robots operating in unstructured environments face significant challenges when interacting with everyday objects like doors. They particularly struggle to generalize across diverse door types and conditions. Existing vision-based and open-loop planning methods often lack the robustness to handle varying door designs, mechanisms, and push/pull configurations. In this work, we propose a haptic-aware closed-loop hierarchical control framework that enables robots to explore and open different unseen doors in the wild. Our approach leverages real-time haptic feedback, allowing the robot to adjust its strategy dynamically based on force feedback during manipulation. We test our system on 20 unseen doors across different buildings, featuring diverse appearances and mechanical types. Our framework achieves a 90% success rate, demonstrating its ability to generalize and robustly handle varied door-opening tasks. This scalable solution offers potential applications in broader open-world articulated object manipulation tasks.
Sensor-Invariant Tactile Representation
Feb 27, 2025High-resolution tactile sensors have become critical for embodied perception and robotic manipulation. However, a key challenge in the field is the lack of transferability between sensors due to design and manufacturing variations, which result in significant differences in tactile signals. This limitation hinders the ability to transfer models or knowledge learned from one sensor to another. To address this, we introduce a novel method for extracting Sensor-Invariant Tactile Representations (SITR), enabling zero-shot transfer across optical tactile sensors. Our approach utilizes a transformer-based architecture trained on a diverse dataset of simulated sensor designs, allowing it to generalize to new sensors in the real world with minimal calibration. Experimental results demonstrate the method's effectiveness across various tactile sensing applications, facilitating data and model transferability for future advancements in the field.
Learning to Double Guess: An Active Perception Approach for Estimating the Center of Mass of Arbitrary Objects
Feb 04, 2025Manipulating arbitrary objects in unstructured environments is a significant challenge in robotics, primarily due to difficulties in determining an object's center of mass. This paper introduces U-GRAPH: Uncertainty-Guided Rotational Active Perception with Haptics, a novel framework to enhance the center of mass estimation using active perception. Traditional methods often rely on single interaction and are limited by the inherent inaccuracies of Force-Torque (F/T) sensors. Our approach circumvents these limitations by integrating a Bayesian Neural Network (BNN) to quantify uncertainty and guide the robotic system through multiple, information-rich interactions via grid search and a neural network that scores each action. We demonstrate the remarkable generalizability and transferability of our method with training on a small dataset with limited variation yet still perform well on unseen complex real-world objects.
InViG: Benchmarking Interactive Visual Grounding with 500K Human-Robot Interactions
Oct 18, 2023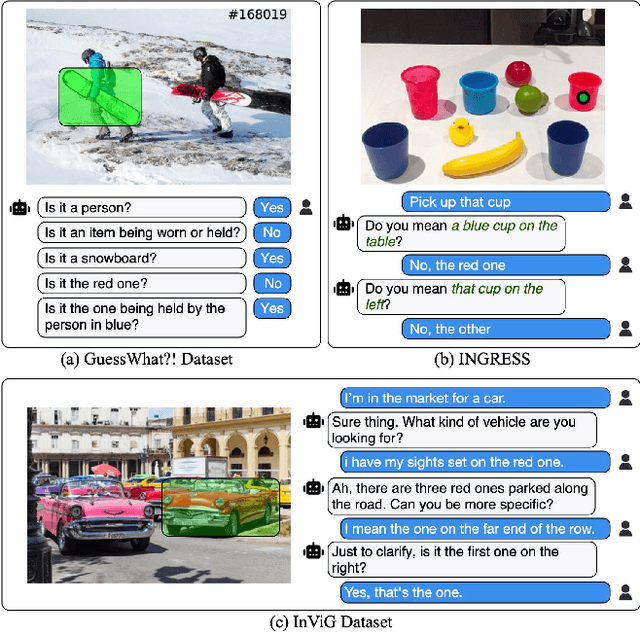



Ambiguity is ubiquitous in human communication. Previous approaches in Human-Robot Interaction (HRI) have often relied on predefined interaction templates, leading to reduced performance in realistic and open-ended scenarios. To address these issues, we present a large-scale dataset, \invig, for interactive visual grounding under language ambiguity. Our dataset comprises over 520K images accompanied by open-ended goal-oriented disambiguation dialogues, encompassing millions of object instances and corresponding question-answer pairs. Leveraging the \invig dataset, we conduct extensive studies and propose a set of baseline solutions for end-to-end interactive visual disambiguation and grounding, achieving a 45.6\% success rate during validation. To the best of our knowledge, the \invig dataset is the first large-scale dataset for resolving open-ended interactive visual grounding, presenting a practical yet highly challenging benchmark for ambiguity-aware HRI. Codes and datasets are available at: \href{https://openivg.github.io}{https://openivg.github.io}.
Combo of Thinking and Observing for Outside-Knowledge VQA
May 10, 2023



Outside-knowledge visual question answering is a challenging task that requires both the acquisition and the use of open-ended real-world knowledge. Some existing solutions draw external knowledge into the cross-modality space which overlooks the much vaster textual knowledge in natural-language space, while others transform the image into a text that further fuses with the textual knowledge into the natural-language space and completely abandons the use of visual features. In this paper, we are inspired to constrain the cross-modality space into the same space of natural-language space which makes the visual features preserved directly, and the model still benefits from the vast knowledge in natural-language space. To this end, we propose a novel framework consisting of a multimodal encoder, a textual encoder and an answer decoder. Such structure allows us to introduce more types of knowledge including explicit and implicit multimodal and textual knowledge. Extensive experiments validate the superiority of the proposed method which outperforms the state-of-the-art by 6.17% accuracy. We also conduct comprehensive ablations of each component, and systematically study the roles of varying types of knowledge. Codes and knowledge data can be found at https://github.com/PhoebusSi/Thinking-while-Observing.
Rethinking Generative Coverage: A Pointwise Guaranteed Approach
Feb 20, 2019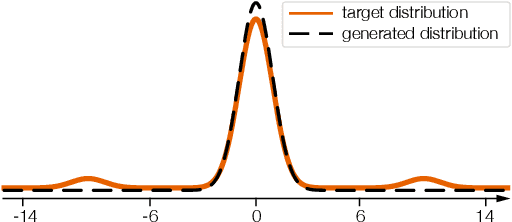


All generative models have to combat missing modes. The conventional wisdom is by reducing a statistical distance (such as f-divergence) between the generated distribution and the provided data distribution through training. We defy this wisdom. We show that even a small statistical distance does not imply a plausible mode coverage, because this distance measures a global similarity between two distributions, but not their similarity in local regions--which is needed to ensure a complete mode coverage. From a starkly different perspective, we view the battle against missing modes as a two-player game, between a player choosing a data point and an adversary choosing a generator aiming to cover that data point. Enlightened by von Neumann's minimax theorem, we see that if a generative model can approximate a data distribution moderately well under a global statistical distance measure, then we should be able to find a mixture of generators which collectively covers every data point and thus every mode with a lower-bounded probability density. A constructive realization of this minimax duality--that is, our proposed algorithm of finding the mixture of generators--is connected to a multiplicative weights update rule. We prove the pointwise coverage guarantee of our algorithm, and our experiments on real and synthetic data confirm better mode coverage over recent approaches that also use a mixture of generators but focus on global statistical distances.
Active Clothing Material Perception using Tactile Sensing and Deep Learning
Feb 25, 2018
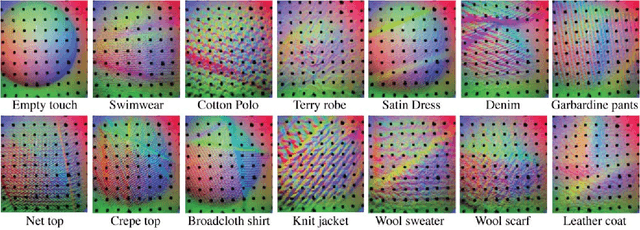


Humans represent and discriminate the objects in the same category using their properties, and an intelligent robot should be able to do the same. In this paper, we build a robot system that can autonomously perceive the object properties through touch. We work on the common object category of clothing. The robot moves under the guidance of an external Kinect sensor, and squeezes the clothes with a GelSight tactile sensor, then it recognizes the 11 properties of the clothing according to the tactile data. Those properties include the physical properties, like thickness, fuzziness, softness and durability, and semantic properties, like wearing season and preferred washing methods. We collect a dataset of 153 varied pieces of clothes, and conduct 6616 robot exploring iterations on them. To extract the useful information from the high-dimensional sensory output, we applied Convolutional Neural Networks (CNN) on the tactile data for recognizing the clothing properties, and on the Kinect depth images for selecting exploration locations. Experiments show that using the trained neural networks, the robot can autonomously explore the unknown clothes and learn their properties. This work proposes a new framework for active tactile perception system with vision-touch system, and has potential to enable robots to help humans with varied clothing related housework.