 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Differentiable Programming System to Bridge Machine Learning and Scientific Computing
Jul 18, 2019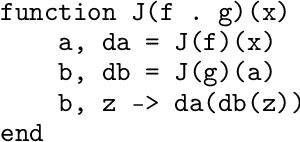

Scientific computing is increasingly incorporating the advancements in machine learning and the ability to work with large amounts of data. At the same time, machine learning models are becoming increasingly sophisticated and exhibit many features often seen in scientific computing, stressing the capabilities of machine learning frameworks. Just as the disciplines of scientific computing and machine learning have shared common underlying infrastructure in the form of numerical linear algebra, we now have the opportunity to further share new computational infrastructure, and thus ideas, in the form of Differentiable Programming. We describe Zygote, a Differentiable Programming system that is able to take gradients of general program structures. We implement this system in the Julia programming language. Our system supports almost all language constructs (control flow, recursion, mutation, etc.) and compiles high-performance code without requiring any user intervention or refactoring to stage computations. This enables an expressive programming model for deep learning, but more importantly, it enables us to incorporate a large ecosystem of libraries in our models in a straightforward way. We discuss our approach to automatic differentiation, including its support for advanced techniques such as mixed-mode, complex and checkpointed differentiation, and present several examples of differentiating programs.
Fashionable Modelling with Flux
Nov 01, 2018
Machine learning as a discipline has seen an incredible surge of interest in recent years due in large part to a perfect storm of new theory, superior tooling, renewed interest in its capabilities. We present in this paper a framework named Flux that shows how further refinement of the core ideas of machine learning, built upon the foundation of the Julia programming language, can yield an environment that is simple, easily modifiable, and performant. We detail the fundamental principles of Flux as a framework for differentiable programming, give examples of models that are implemented within Flux to display many of the language and framework-level features that contribute to its ease of use and high productivity, display internal compiler techniques used to enable the acceleration and performance that lies at the heart of Flux, and finally give an overview of the larger ecosystem that Flux fits inside of.
Automatic Full Compilation of Julia Programs and ML Models to Cloud TPUs
Oct 23, 2018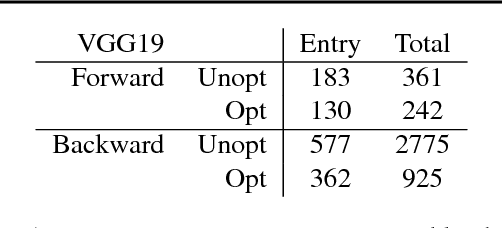
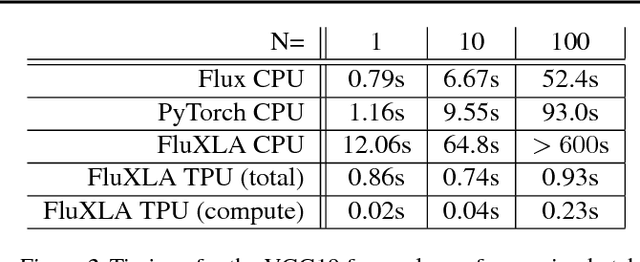
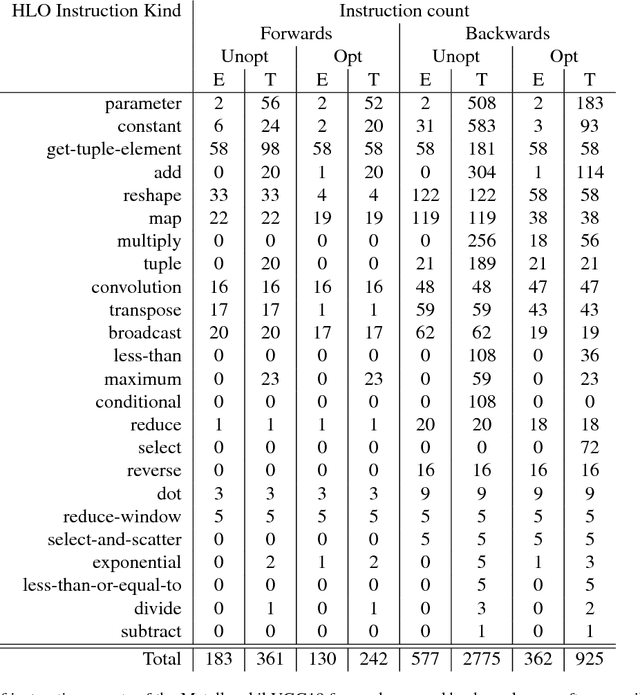
Google's Cloud TPUs are a promising new hardware architecture for machine learning workloads. They have powered many of Google's milestone machine learning achievements in recent years. Google has now made TPUs available for general use on their cloud platform and as of very recently has opened them up further to allow use by non-TensorFlow frontends. We describe a method and implementation for offloading suitable sections of Julia programs to TPUs via this new API and the Google XLA compiler. Our method is able to completely fuse the forward pass of a VGG19 model expressed as a Julia program into a single TPU executable to be offloaded to the device. Our method composes well with existing compiler-based automatic differentiation techniques on Julia code, and we are thus able to also automatically obtain the VGG19 backwards pass and similarly offload it to the TPU. Targeting TPUs using our compiler, we are able to evaluate the VGG19 forward pass on a batch of 100 images in 0.23s which compares favorably to the 52.4s required for the original model on the CPU. Our implementation is less than 1000 lines of Julia, with no TPU specific changes made to the core Julia compiler or any other Julia packages.