 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Scene Understanding Through Local Random Access Sequence Modeling
Apr 04, 20253D scene understanding from single images is a pivotal problem in computer vision with numerous downstream applications in graphics, augmented reality, and robotics. While diffusion-based modeling approaches have shown promise, they often struggle to maintain object and scene consistency, especially in complex real-world scenarios. To address these limitations, we propose an autoregressive generative approach called Local Random Access Sequence (LRAS) modeling, which uses local patch quantization and randomly ordered sequence generation. By utilizing optical flow as an intermediate representation for 3D scene editing, our experiments demonstrate that LRAS achieves state-of-the-art novel view synthesis and 3D object manipulation capabilities. Furthermore, we show that our framework naturally extends to self-supervised depth estimation through a simple modification of the sequence design. By achieving strong performance on multiple 3D scene understanding tasks, LRAS provides a unified and effective framework for building the next generation of 3D vision models.
Instruction-tuning Aligns LLMs to the Human Brain
Dec 01, 2023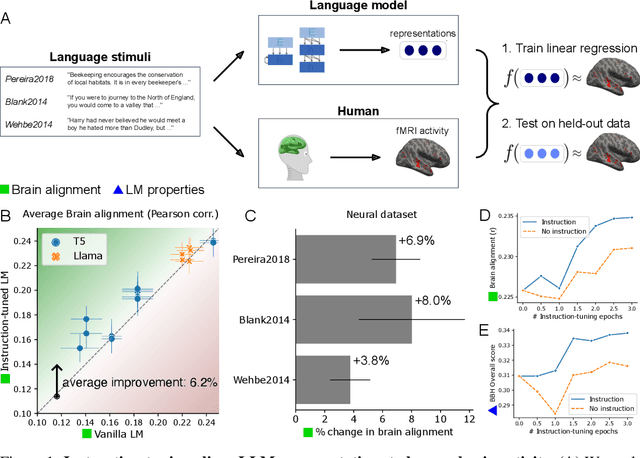

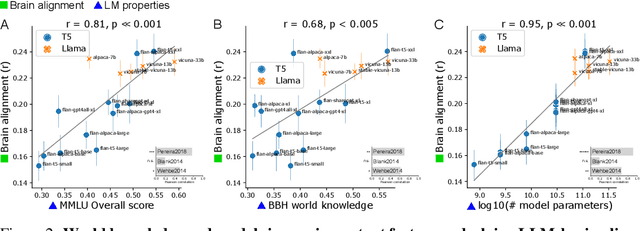
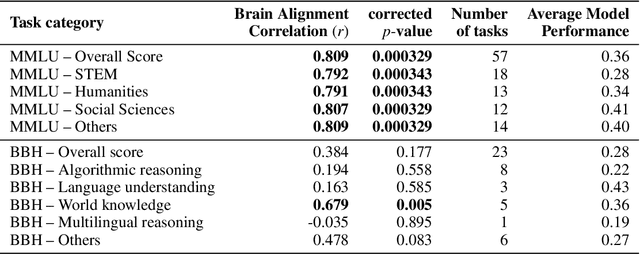
Instruction-tuning is a widely adopted method of finetuning that enables large language models (LLMs) to generate output that more closely resembles human responses to natural language queries, in many cases leading to human-level performance on diverse testbeds. However, it remains unclear whether instruction-tuning truly makes LLMs more similar to how humans process language. We investigate the effect of instruction-tuning on LLM-human similarity in two ways: (1) brain alignment, the similarity of LLM internal representations to neural activity in the human language system, and (2) behavioral alignment, the similarity of LLM and human behavior on a reading task. We assess 25 vanilla and instruction-tuned LLMs across three datasets involving humans reading naturalistic stories and sentences. We discover that instruction-tuning generally enhances brain alignment by an average of 6%, but does not have a similar effect on behavioral alignment. To identify the factors underlying LLM-brain alignment, we compute correlations between the brain alignment of LLMs and various model properties, such as model size, various problem-solving abilities, and performance on tasks requiring world knowledge spanning various domains. Notably, we find a strong positive correlation between brain alignment and model size (r = 0.95), as well as performance on tasks requiring world knowledge (r = 0.81). Our results demonstrate that instruction-tuning LLMs improves both world knowledge representations and brain alignment, suggesting that mechanisms that encode world knowledge in LLMs also improve representational alignment to the human brain.
Training language models for deeper understanding improves brain alignment
Dec 21, 2022Building systems that achieve a deeper understanding of language is one of the central goals of natural language processing (NLP). Towards this goal, recent works have begun to train language models on narrative datasets which require extracting the most critical information by integrating across long contexts. However, it is still an open question whether these models are learning a deeper understanding of the text, or if the models are simply learning a heuristic to complete the task. This work investigates this further by turning to the one language processing system that truly understands complex language: the human brain. We show that training language models for deeper narrative understanding results in richer representations that have improved alignment to human brain activity. We further find that the improvements in brain alignment are larger for character names than for other discourse features, which indicates that these models are learning important narrative elements. Taken together, these results suggest that this type of training can indeed lead to deeper language understanding. These findings have consequences both for cognitive neuroscience by revealing some of the significant factors behind brain-NLP alignment, and for NLP by highlighting that understanding of long-range context can be improved beyond language modeling.