 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Out-of-Distribution Generalization Capabilities of DNN-based Encoding Models for the Ventral Visual Cortex
Jun 16, 2024



We characterized the generalization capabilities of DNN-based encoding models when predicting neuronal responses from the visual cortex. We collected \textit{MacaqueITBench}, a large-scale dataset of neural population responses from the macaque inferior temporal (IT) cortex to over $300,000$ images, comprising $8,233$ unique natural images presented to seven monkeys over $109$ sessions. Using \textit{MacaqueITBench}, we investigated the impact of distribution shifts on models predicting neural activity by dividing the images into Out-Of-Distribution (OOD) train and test splits. The OOD splits included several different image-computable types including image contrast, hue, intensity, temperature, and saturation. Compared to the performance on in-distribution test images -- the conventional way these models have been evaluated -- models performed worse at predicting neuronal responses to out-of-distribution images, retaining as little as $20\%$ of the performance on in-distribution test images. The generalization performance under OOD shifts can be well accounted by a simple image similarity metric -- the cosine distance between image representations extracted from a pre-trained object recognition model is a strong predictor of neural predictivity under different distribution shifts. The dataset of images, neuronal firing rate recordings, and computational benchmarks are hosted publicly at: https://bit.ly/3zeutVd.
Performance-optimized deep neural networks are evolving into worse models of inferotemporal visual cortex
Jun 06, 2023One of the most impactful findings in computational neuroscience over the past decade is that the object recognition accuracy of deep neural networks (DNNs) correlates with their ability to predict neural responses to natural images in the inferotemporal (IT) cortex. This discovery supported the long-held theory that object recognition is a core objective of the visual cortex, and suggested that more accurate DNNs would serve as better models of IT neuron responses to images. Since then, deep learning has undergone a revolution of scale: billion parameter-scale DNNs trained on billions of images are rivaling or outperforming humans at visual tasks including object recognition. Have today's DNNs become more accurate at predicting IT neuron responses to images as they have grown more accurate at object recognition? Surprisingly, across three independent experiments, we find this is not the case. DNNs have become progressively worse models of IT as their accuracy has increased on ImageNet. To understand why DNNs experience this trade-off and evaluate if they are still an appropriate paradigm for modeling the visual system, we turn to recordings of IT that capture spatially resolved maps of neuronal activity elicited by natural images. These neuronal activity maps reveal that DNNs trained on ImageNet learn to rely on different visual features than those encoded by IT and that this problem worsens as their accuracy increases. We successfully resolved this issue with the neural harmonizer, a plug-and-play training routine for DNNs that aligns their learned representations with humans. Our results suggest that harmonized DNNs break the trade-off between ImageNet accuracy and neural prediction accuracy that assails current DNNs and offer a path to more accurate models of biological vision.
Look Twice: A Computational Model of Return Fixations across Tasks and Species
Jan 05, 2021
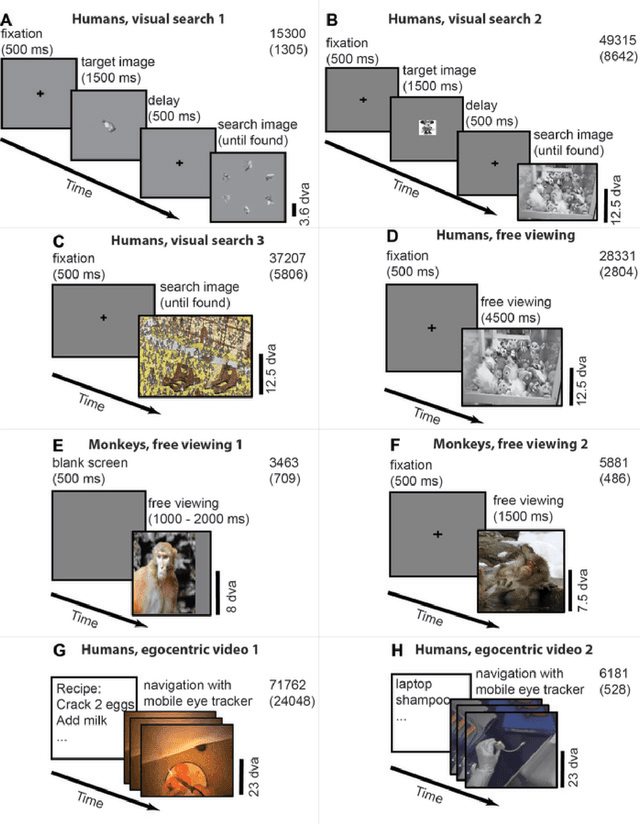
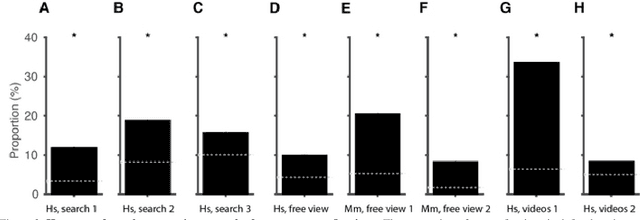
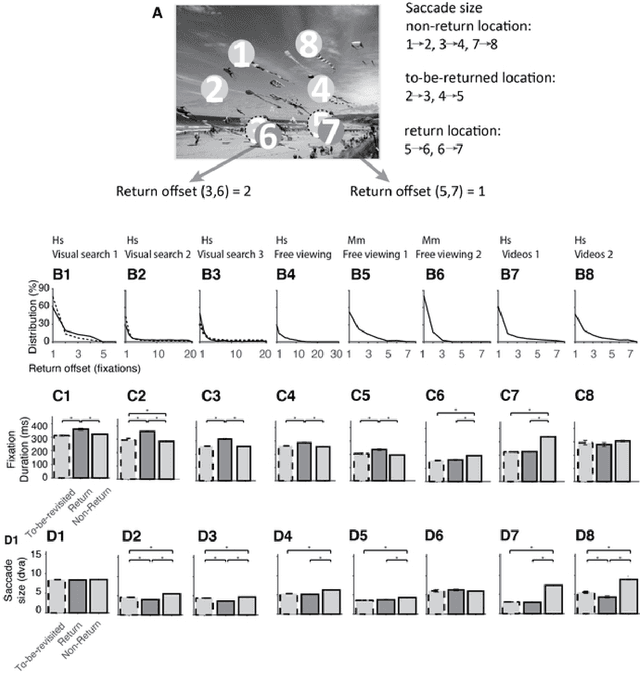
Saccadic eye movements allow animals to bring different parts of an image into high-resolution. During free viewing, inhibition of return incentivizes exploration by discouraging previously visited locations. Despite this inhibition, here we show that subjects make frequent return fixations. We systematically studied a total of 44,328 return fixations out of 217,440 fixations across different tasks, in monkeys and humans, and in static images or egocentric videos. The ubiquitous return fixations were consistent across subjects, tended to occur within short offsets, and were characterized by longer duration than non-return fixations. The locations of return fixations corresponded to image areas of higher saliency and higher similarity to the sought target during visual search tasks. We propose a biologically-inspired computational model that capitalizes on a deep convolutional neural network for object recognition to predict a sequence of fixations. Given an input image, the model computes four maps that constrain the location of the next saccade: a saliency map, a target similarity map, a saccade size map, and a memory map. The model exhibits frequent return fixations and approximates the properties of return fixations across tasks and species. The model provides initial steps towards capturing the trade-off between exploitation of informative image locations combined with exploration of novel image locations during scene viewing.