 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p
Impact of Attention on Adversarial Robustness of Image Classification Models
Sep 02, 2021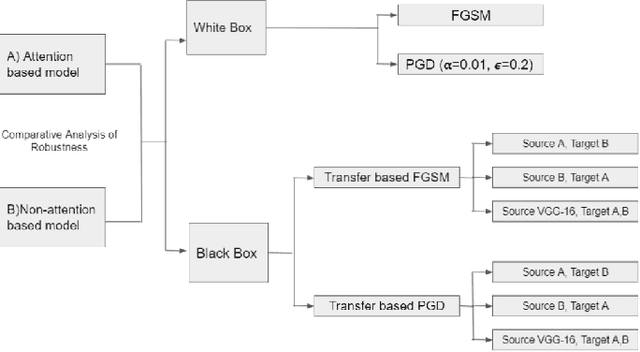
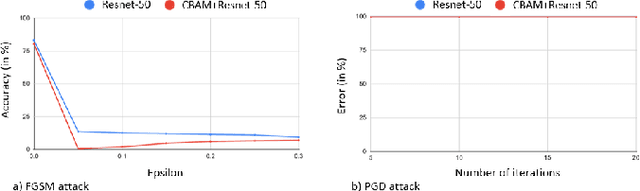
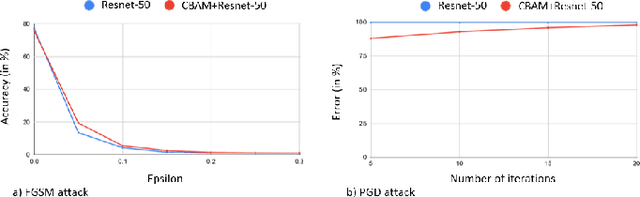
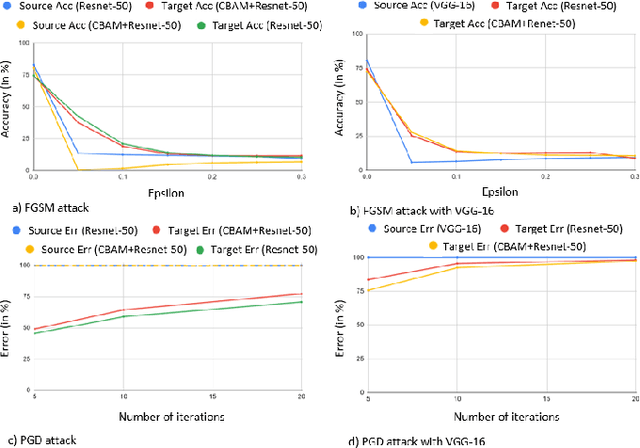
Adversarial attacks against deep learning models have gained significant attention and recent works have proposed explanations for the existence of adversarial examples and techniques to defend the models against these attacks. Attention in computer vision has been used to incorporate focused learning of important features and has led to improved accuracy. Recently, models with attention mechanisms have been proposed to enhance adversarial robustness. Following this context, this work aims at a general understanding of the impact of attention on adversarial robustness. This work presents a comparative study of adversarial robustness of non-attention and attention based image classification models trained on CIFAR-10, CIFAR-100 and Fashion MNIST datasets under the popular white box and black box attacks. The experimental results show that the robustness of attention based models may be dependent on the datasets used i.e. the number of classes involved in the classification. In contrast to the datasets with less number of classes, attention based models are observed to show better robustness towards classification.